1. 概述
算法的运行时间复杂度往往高度依赖于输入数据的特性。
本文将深入分析 标准快速排序(Quicksort)在处理大量重复元素时性能急剧下降的问题,并介绍几种高效的变体方案,用于优化对重复键值密集的数组进行分区和排序。
这些改进方案的核心思想是:通过更聪明的分区策略,避免在重复元素上做无意义的递归,从而将最坏情况下的时间复杂度从 O(n²) 优化到接近 O(n)。
2. 标准快速排序的陷阱
快速排序是一种基于分治思想的高效排序算法。它原地操作数组,通过简单的比较和交换操作完成排序。
2.1 单轴心分区(Single-pivot Partitioning)
标准快速排序依赖于单轴心分区。该过程将数组 A[p..r] 划分为两个部分 A[p..q] 和 A[q+1..r],满足:
- 左分区
A[p..q]中的所有元素 ≤ 轴心值A[q] - 右分区
A[q+1..r]中的所有元素 ≥ 轴心值A[q]

随后,左右两个分区作为独立子问题递归地进行快速排序。以下是 Lomuto 分区方案的演示:

2.2 重复元素带来的性能问题
考虑一个极端情况:A = [4, 4, 4, 4, 4, 4, 4],所有元素都相同。
使用单轴心分区时,每次划分会得到一个空分区和一个包含 N-1 个元素的分区。后续每次分区调用只能将问题规模减一,导致递归深度达到 O(n)。

由于分区过程本身是 O(n),总时间复杂度退化为 O(n²),这正是我们最不希望看到的最坏情况。在实际开发中,这种“踩坑”场景并不少见。
3. 三路分区(Three-way Partitioning)
为了高效处理大量重复键值的数组,我们需要更负责任地处理相等的元素。核心思想是:在首次遇到相等元素时,就将它们放置到最终的正确位置。
目标是将数组划分为三个区域:
- 左分区:所有元素 < 轴心值
- ✅ 中分区:所有元素 == 轴心值
- 右分区:所有元素 > 轴心值

下面我们深入探讨两种实现三路分区的有效方法。
4. Dijkstra 方法
Dijkstra 提出的三路分区方法非常经典,其思想源于著名的“荷兰国旗问题”(Dutch National Flag Problem)。
4.1 荷兰国旗问题(DNF)
该问题要求将一排红、白、蓝三色小球按颜色分组,并保证顺序为红、白、蓝。这与数组的三路分区完美对应:
- 红色组:元素 < 轴心值
- 白色组:元素 == 轴心值
- 蓝色组:元素 > 轴心值

4.2 算法原理
使用三个指针:
-
lt:指向“小于”区域的右边界 -
current:用于扫描当前元素 -
gt:指向“大于”区域的左边界
不变式(Invariant):
-
arr[0..lt-1]:所有元素 <pivot -
arr[lt..current-1]:所有元素 ==pivot -
arr[current..gt]:待处理区域 -
arr[gt+1..end]:所有元素 >pivot
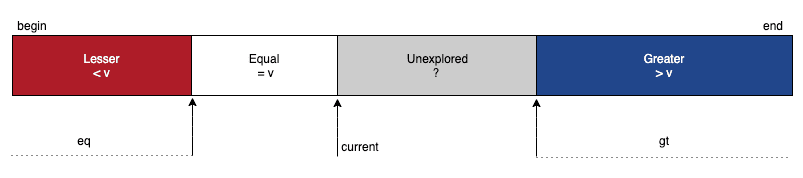
初始化:lt = current = begin, gt = end。
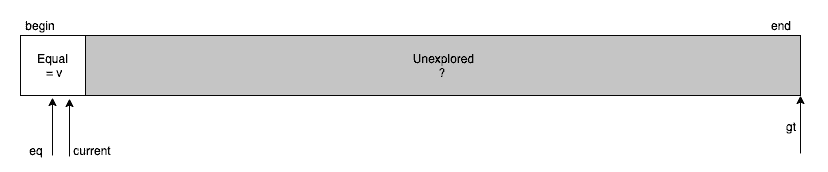
遍历逻辑:
-
arr[current] < pivot:与arr[lt]交换,lt++,current++ -
arr[current] == pivot:current++ -
arr[current] > pivot:与arr[gt]交换,gt--(current不变,因为换来的元素未检查)
终止条件:当 current > gt 时,扫描完成。

4.3 Java 实现
public static int compare(int num1, int num2) {
if (num1 > num2) return 1;
else if (num1 < num2) return -1;
else return 0;
}
public static void swap(int[] array, int position1, int position2) {
if (position1 != position2) {
int temp = array[position1];
array[position1] = array[position2];
array[position2] = temp;
}
}
public class Partition {
private int left;
private int right;
public Partition(int left, int right) {
this.left = left;
this.right = right;
}
public int getLeft() { return left; }
public int getRight() { return right; }
}
核心分区方法:
public static Partition partition(int[] input, int begin, int end) {
int lt = begin, current = begin, gt = end;
int partitioningValue = input[begin]; // 选首元素为轴心
while (current <= gt) {
int cmp = compare(input[current], partitioningValue);
switch (cmp) {
case -1:
swap(input, current++, lt++);
break;
case 0:
current++;
break;
case 1:
swap(input, current, gt--);
break;
}
}
return new Partition(lt, gt); // 返回等于区域的边界 [lt, gt]
}
三路快排主方法:
public static void quicksort(int[] input, int begin, int end) {
if (end <= begin) return;
Partition mid = partition(input, begin, end);
// 递归排序左分区(< pivot)
quicksort(input, begin, mid.getLeft() - 1);
// 递归排序右分区(> pivot)
quicksort(input, mid.getRight() + 1, end);
}
5. Bentley-McIlroy 方法
Jon Bentley 和 Douglas McIlroy 提出了一种更优化的三路快排变体,其分区策略更为高效。
5.1 分区方案
该算法的核心是基于迭代的分区。将数组划分为五个区域:
- 左端:等于轴心值的元素
- 中间偏左:小于轴心值的元素
- 中心:待探索区域
- 中间偏右:大于轴心值的元素
- 右端:等于轴心值的元素


探索结束后,将两端的“等于”区域的元素移到中心合并。

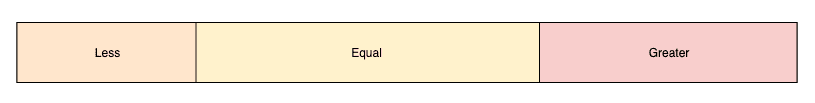
5.2 Java 实现
public static Partition partition(int input[], int begin, int end) {
int left = begin;
int right = end;
int partitioningValue = input[end]; // 选末尾元素为轴心
int leftEqualKeysCount = 0;
int rightEqualKeysCount = 0;
while (true) {
// 从左找 >= pivot 的元素
while (input[left] < partitioningValue) left++;
// 从右找 <= pivot 的元素
while (input[right] > partitioningValue) {
if (right == begin) break; // 防止越界
right--;
}
// 特殊情况:左右指针相遇且等于 pivot
if (left == right && input[left] == partitioningValue) {
swap(input, begin + leftEqualKeysCount, left);
leftEqualKeysCount++;
left++;
}
if (left >= right) break;
swap(input, left, right);
// 将等于 pivot 的元素移到两端
if (input[left] == partitioningValue) {
swap(input, begin + leftEqualKeysCount, left);
leftEqualKeysCount++;
}
if (input[right] == partitioningValue) {
swap(input, right, end - rightEqualKeysCount);
rightEqualKeysCount++;
}
left++;
right--;
}
// 将左端的相等元素移到中间
right = left - 1;
for (int k = begin; k < begin + leftEqualKeysCount; k++, right--) {
if (right >= begin + leftEqualKeysCount)
swap(input, k, right);
}
// 将右端的相等元素移到中间
for (int k = end; k > end - rightEqualKeysCount; k--, left++) {
if (left <= end - rightEqualKeysCount)
swap(input, left, k);
}
return new Partition(right + 1, left - 1);
}
演示:
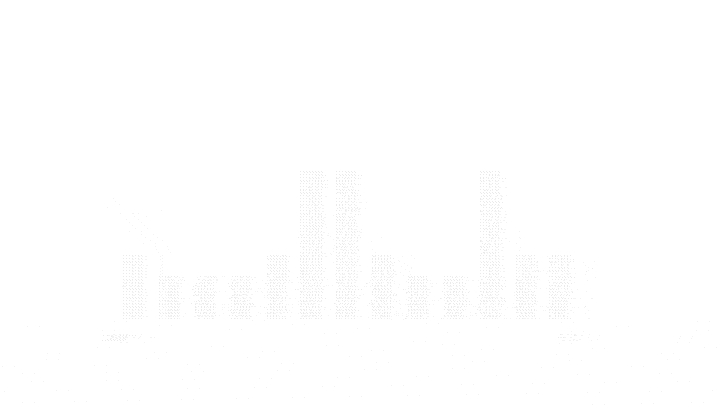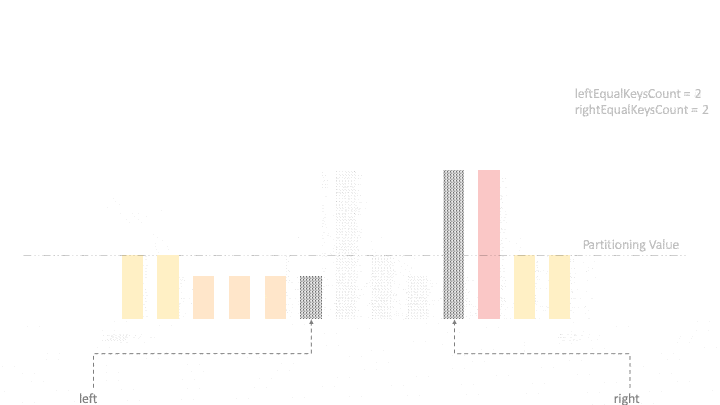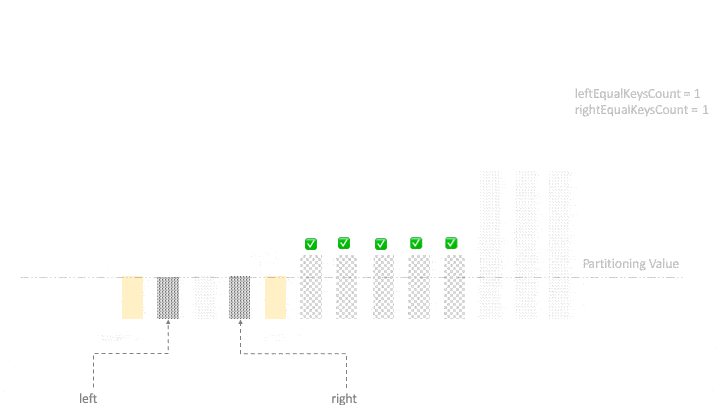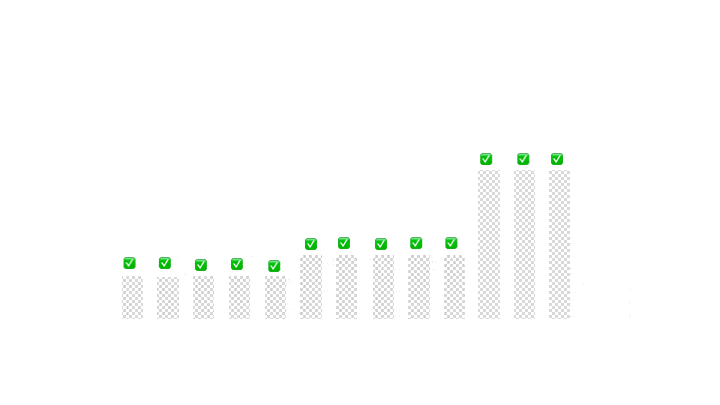
6. 算法分析
| 方案 | 平均复杂度 | 最坏复杂度 | 重复元素影响 |
|---|---|---|---|
| 标准单轴心 | O(n log n) | O(n²) | ❌ 密集重复时退化 |
| Dijkstra 三路 | O(n log n) | O(n log n) | ✅ O(n) 最佳情况 |
| Bentley-McIlroy | O(n log n) | O(n log n) | ✅ O(n) 最佳情况,开销更智能 |
关键洞察:
- 三路分区将“等于”区域一次性归位,避免了无效递归。
- 当所有元素相等时,三路快排可在 O(n) 时间内完成,这是巨大的优化。
- Dijkstra 方法的开销固定,对无重复数组不友好。
- ⚠️ Bentley-McIlroy 的开销与重复元素数量正相关,更具适应性,是更优选择。
7. 总结
本文剖析了标准快排在处理重复数据时的性能瓶颈,并介绍了 Dijkstra 和 Bentley-McIlroy 两种三路分区方案。
核心收获:
- 识别场景:当输入数据包含大量重复键值时,应优先考虑三路快排。
- 选择策略:Bentley-McIlroy 变体通常更优,因其开销与数据特性自适应。
- 性能飞跃:最佳情况下,时间复杂度从 O(n log n) 降至 O(n),效果简单粗暴。
完整 Java 源码可在 GitHub 获取:https://github.com/tech-lead-java/tutorials/tree/master/algorithms-sorting-2