1. 概述
本文将探讨流式平台中的消息传递语义。首先,我们快速梳理事件在流式平台核心组件中的流转过程,接着分析数据丢失和重复的常见原因,然后重点介绍三种主要的传递语义。
我们将讨论如何在流式平台中实现这些语义,以及它们如何解决数据丢失和重复问题。每种传递语义中,都会简要说明在Apache Kafka中实现相应保证的方法。
2. 流式平台基础
简单来说,像Apache Kafka和Apache ActiveMQ这样的流式平台,会实时或准实时地处理来自一个或多个生产者(Producer)的事件,并将其传递给一个或多个消费者(Consumer)进行后续处理、转换、分析或存储。
生产者和消费者通过代理(Broker)解耦,这实现了系统的可扩展性。
流式应用的典型场景包括:电商网站中大规模用户行为追踪、金融交易的实时欺诈检测、需要实时处理的自主移动设备等。
消息传递平台有两个关键考量因素:
- 准确性
- 延迟
在分布式实时系统中,我们经常需要在延迟和准确性之间做出权衡,具体取决于系统的核心需求。这就需要理解流式平台原生提供的传递保证,或通过消息元数据和平台配置来实现所需的保证。
接下来,我们简要分析流式平台中的数据丢失和重复问题,这将引出我们讨论传递语义的必要性。
3. 数据丢失与重复的可能场景
为理解流式平台中的数据丢失和/或重复问题,我们先快速回顾事件在流式平台中的高层流程:
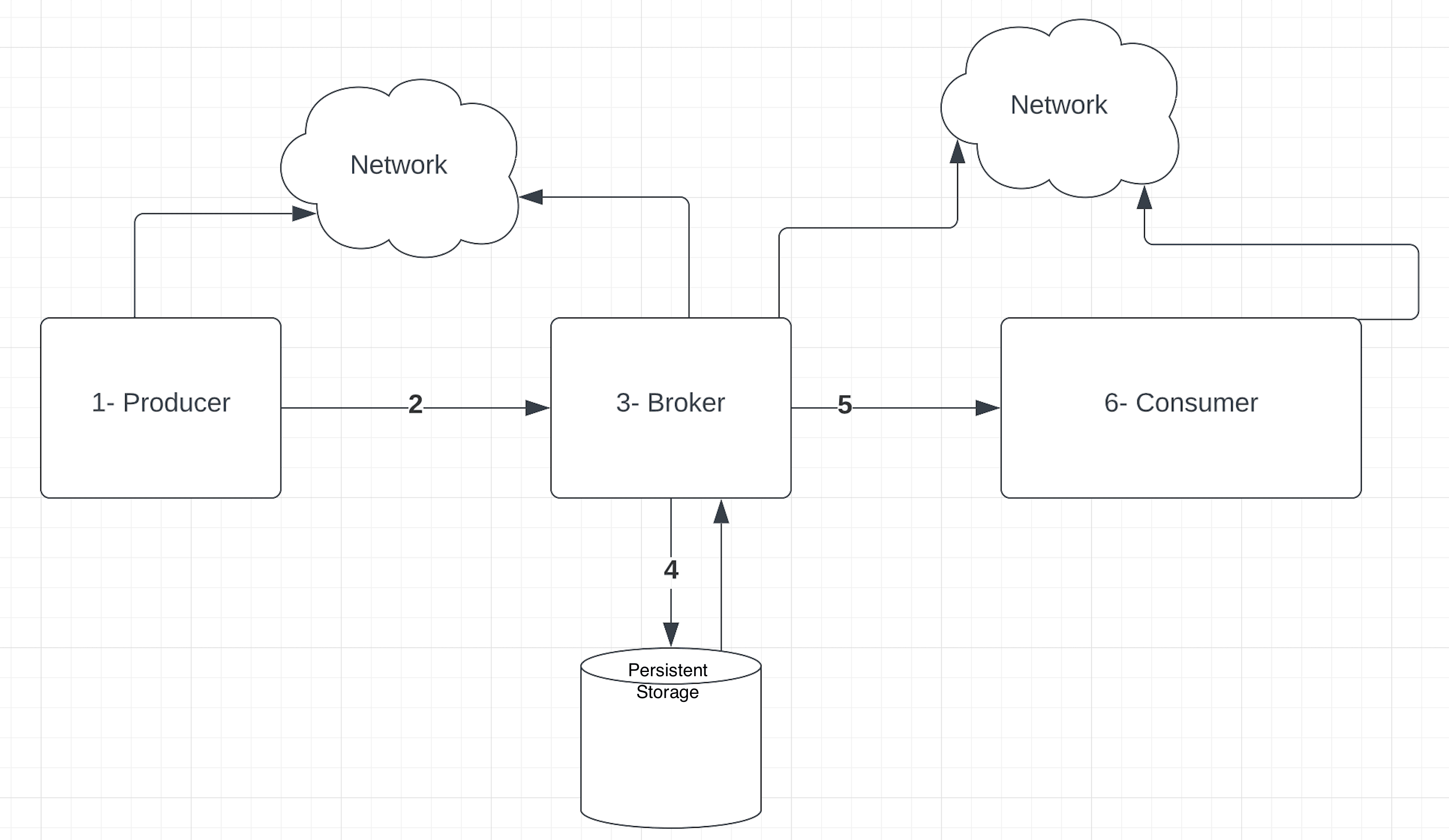
从图中可见,从生产者到消费者的整个流程中存在多个潜在故障点,这通常会导致数据丢失、延迟滞后或消息重复等问题。
让我们逐一分析图中各组件可能出现的故障及其后果:
3.1 生产者故障
生产者故障可能导致:
- 消息生成后,在发送前发生故障 ⚠️ 导致数据丢失
- 等待代理确认时发生故障,恢复后重发消息 ⚠️ 导致代理端数据重复
3.2 生产者与代理间的网络问题
网络故障可能导致:
- 消息因网络问题未送达代理
- 代理已接收消息并发送确认,但生产者未收到确认
这两种情况都会导致生产者重发消息,造成代理端数据重复 ⚠️
3.3 代理故障
代理故障同样可能引发重复:
- 消息持久化后、发送确认前代理故障 ⚠️ 导致生产者重发
- 代理在提交消费者已读消息信息前故障 ⚠️ 导致消费者重复读取
3.4 消息持久化问题
内存状态写入磁盘时发生故障 ⚠️ 导致数据丢失
3.5 消费者与代理间的网络问题
网络故障可能导致:
- 代理已发送消息但消费者未收到
- 消费者已发送确认但代理未收到
这两种情况都会导致代理重发消息,造成消费者端数据重复 ⚠️
3.6 消费者故障
消费者故障可能导致:
- 处理消息前故障
- 记录处理状态前故障
- 记录处理状态后、发送确认前故障
这些情况都会导致消费者重新请求消息,造成数据重复。
接下来,我们探讨流式平台中用于解决这些问题的传递语义。
4. 传递语义
传递语义定义了流式平台如何保证事件从源头到目标的传递。主要有三种传递语义:
- 最多一次(At-Most-Once)
- 至少一次(At-Least-Once)
- 精确一次(Exactly-Once)
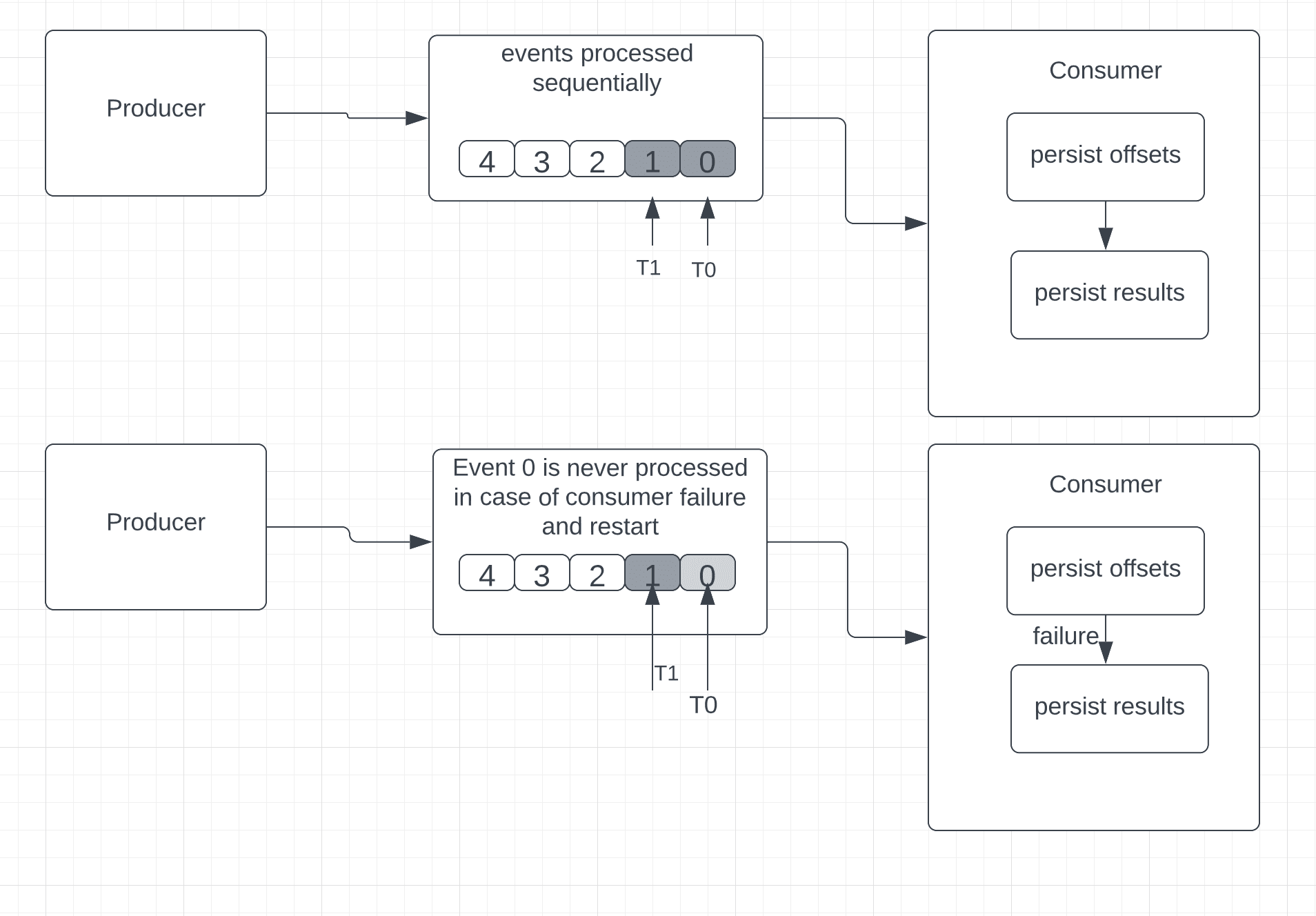
4.1 最多一次传递
核心逻辑:消费者先保存最后接收事件的位置,再处理事件。
简单来说,如果处理过程中发生故障,重启后无法回退读取旧事件。因此无法保证所有事件都被成功处理。
✅ 适用场景:允许少量数据丢失、准确性要求不高的场景
以Apache Kafka为例(使用偏移量定位消息),最多一次保证的执行顺序为:
- 持久化偏移量
- 持久化处理结果
在Kafka中启用最多一次语义:需将消费者端的enable.auto.commit设置为true。
故障重启后,消费者从最后持久化的偏移量开始读取。由于偏移量在事件处理前已保存,无法确定所有事件是否被成功处理,可能导致部分事件丢失。
可视化流程:
4.2 至少一次传递
核心逻辑:消费者先处理事件,持久化结果,最后保存事件位置。
与最多一次不同,故障发生时消费者可以回退重读旧事件。但这也可能导致数据重复——例如消费者在处理并保存事件后、保存位置前故障,重启后会重复处理已成功处理的事件。
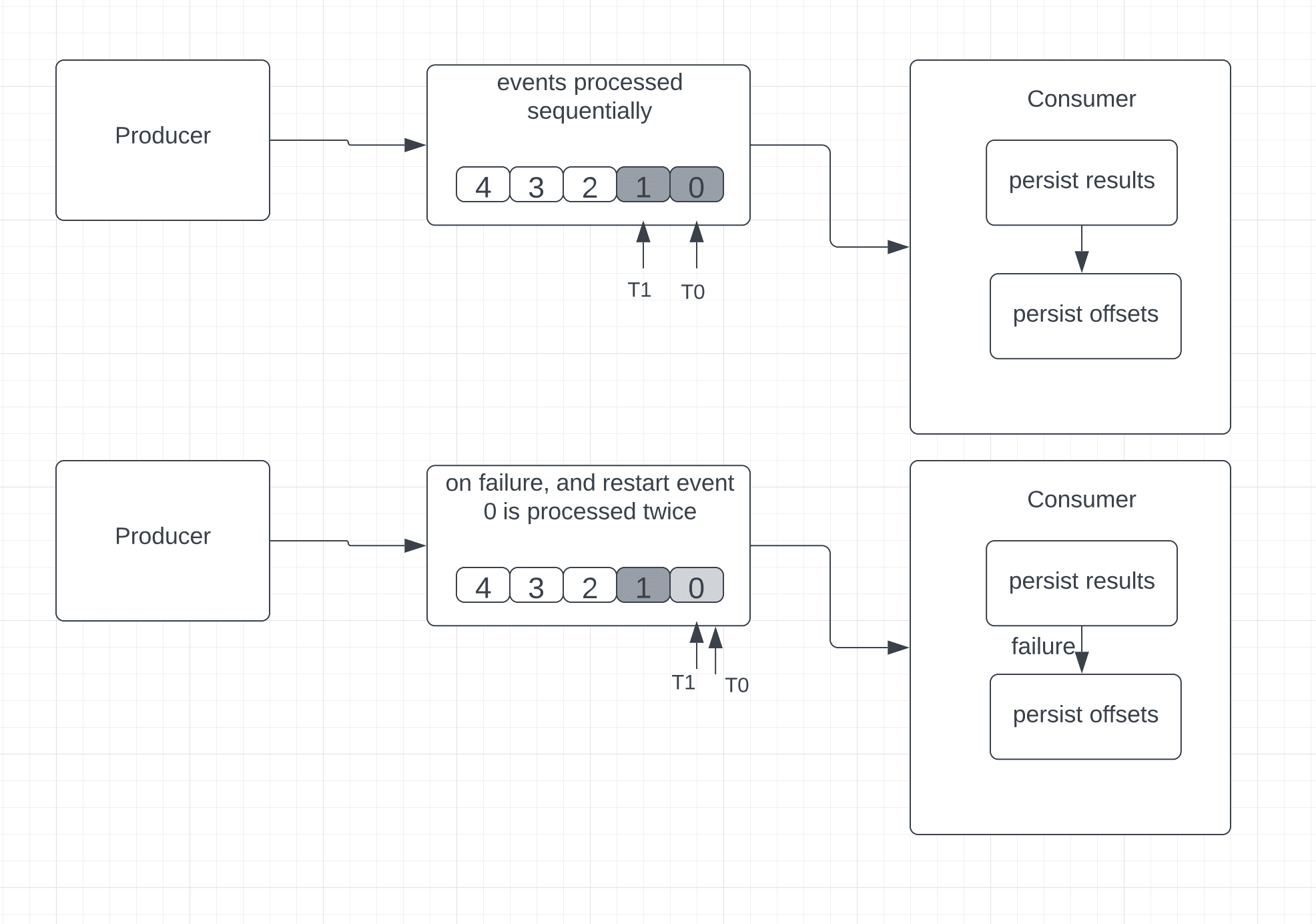
✅ 适用场景:更新仪表盘等可容忍重复的场景
❌ 不适用场景:需要精确聚合(如计数器)的场景,因为重复事件会导致错误结果
关键特性:保证不丢失数据,但可能重复处理事件
避免重复处理的方案:使用幂等消费者
幂等消费者可多次接收消息但只处理一次,实现方式:
- 生产者为每条消息分配唯一
messageId - 消费者在数据库中维护已处理消息记录
- 新消息到达时,检查
messageId是否已存在- 若存在:更新偏移量并发送确认(跳过处理)
- 若不存在:启动事务,插入新
messageId,处理业务逻辑,提交事务
在Kafka中启用至少一次语义:
- 生产者端:设置
ack=1(等待代理确认) - 消费者端:设置
enable.auto.commit=false(手动提交偏移量) - 启用幂等生产者:设置
enable.idempotence=true - 生产者为每条消息附加序列号和生产者ID
Kafka代理通过序列号和生产者ID识别并去重。
4.3 精确一次传递
核心逻辑:类似至少一次,但会自动丢弃重复事件。
执行顺序:
- 持久化处理结果
- 持久化偏移量
当消费者在处理后、保存偏移量前故障时,重启后重读的事件会被丢弃,确保只处理一次。
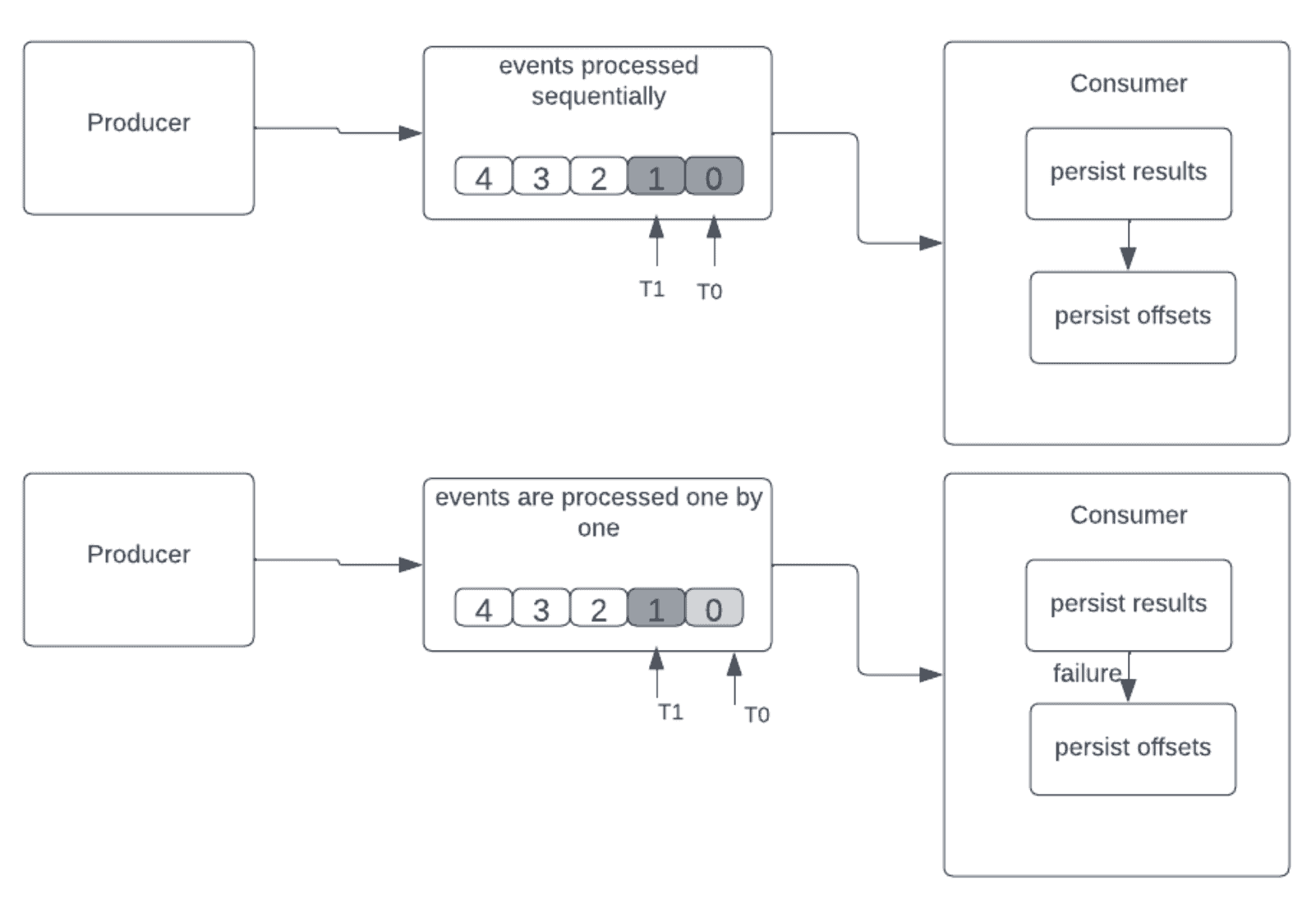
✅ 适用场景:需要精确计数的场景(如金融交易)
实现去重的两种方式:
- 幂等更新:基于唯一键保存结果,重复键存在则跳过更新
- 事务更新:批量处理时使用事务,提交失败则回滚,丢弃重复事件
在Kafka中启用精确一次语义:
- 生产者端:设置唯一
transaction.id启用幂等和事务功能 - 消费者端:设置
isolation.level=read_committed启用事务读取
5. 总结
本文分析了流式平台中三种传递语义的差异:
- 首先概述了事件流及数据丢失/重复问题
- 探讨了如何通过不同传递语义解决这些问题
- 详细介绍了至少一次语义,并对比了最多一次和精确一次语义
核心要点对比:
| 语义 | 数据丢失 | 数据重复 | 适用场景 | Kafka关键配置 |
|--------------|----------|----------|------------------------|-----------------------------------|
| 最多一次 | ⚠️ 可能 | ✅ 无 | 允许丢失数据 | enable.auto.commit=true |
| 至少一次 | ✅ 无 | ⚠️ 可能 | 可容忍重复 | ack=1, enable.idempotence=true |
| 精确一次 | ✅ 无 | ✅ 无 | 需要精确处理 | transaction.id, isolation.level=read_committed |
根据业务需求选择合适语义,是构建可靠流式系统的关键决策。