1. 概述
ELK Stack 是用于日志收集、分析与可视化的经典技术组合,广泛应用于生产环境监控。本文将介绍 ELK 的核心组件及其工作原理,并通过一个 Docker 实践示例帮助你快速上手。
ELK 是 Elasticsearch、Logstash 和 Kibana 三个工具的合称。它们分别承担数据存储、数据处理与数据展示的职责,协同工作以实现日志的全链路管理。
2. ELK 架构解析
ELK 架构如下图所示:
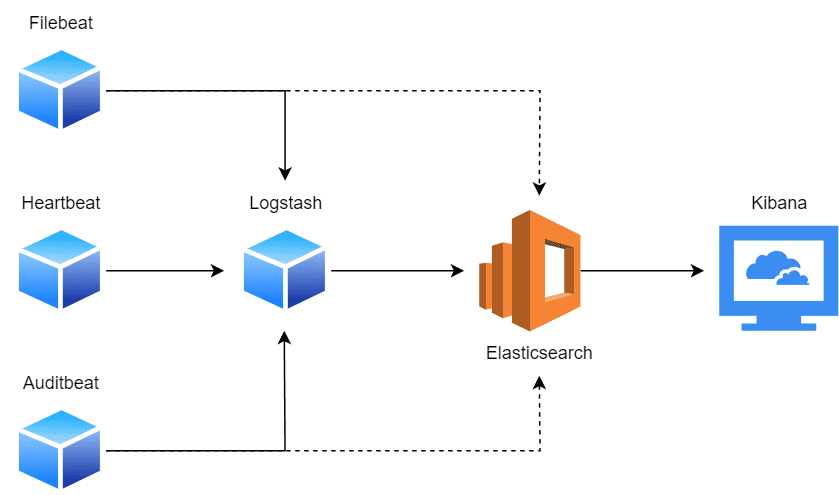
各组件职责如下:
- Elasticsearch:作为分布式搜索引擎,用于存储结构化和非结构化数据,并提供高效的全文检索能力。
- Logstash:是一个数据处理流水线,负责从多种来源收集、过滤和转换日志数据,再发送到 Elasticsearch。
- Kibana:提供可视化界面,支持对 Elasticsearch 中的数据进行查询、图表展示及仪表盘构建。
通常,多个 Logstash 实例部署在不同节点上,将日志收集后统一发送至 Elasticsearch 集群。也可以使用 Beats(轻量级数据采集器)作为替代方案,将数据直接发送到 Logstash 或 Elasticsearch。
3. 搭建 ELK 环境
我们使用 Docker Compose 快速搭建一个 ELK 环境:
version: '3.7'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.15.0
container_name: elasticsearch
environment:
- discovery.type=single-node
- cluster.name=kernel-logs
- node.name=node-1
- xpack.security.enabled=false
ports:
- "9200:9200"
volumes:
- esdata:/usr/share/elasticsearch/data
networks:
- elk
logstash:
image: docker.elastic.co/logstash/logstash:8.15.0
container_name: logstash
depends_on:
- elasticsearch
ports:
- "5044:5044"
volumes:
- ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml
- ./logstash/pipeline:/usr/share/logstash/pipeline
- /var/log/syslog:/var/log/syslog:ro
networks:
- elk
kibana:
image: docker.elastic.co/kibana/kibana:8.15.0
container_name: kibana
depends_on:
- elasticsearch
ports:
- "5601:5601"
networks:
- elk
volumes:
esdata:
networks:
elk:
driver: bridge
启动服务:
$ docker compose up -d
验证 Elasticsearch 状态:
$ curl -X GET "localhost:9200/_cluster/health?pretty"
输出为 status: green 表示集群健康,可以继续后续操作。
4. Elasticsearch 简介
Elasticsearch 是基于 Apache Lucene 构建的分布式搜索引擎,适用于结构化与非结构化数据的快速全文检索。
4.1. 核心优势
✅ 高性能:支持毫秒级响应
✅ 易扩展:可横向扩展节点以处理更大规模数据
✅ REST API:提供丰富的 API 接口,便于集成
4.2. Lucene 查询语法示例
Elasticsearch 使用 Lucene 查询语法,支持复杂条件组合:
"Spring Boot" AND (training OR tutorial) NOT kotlin AND date:[2024-01-01 TO 2024-09-01]
该查询将匹配包含 “Spring Boot”、包含 “training” 或 “tutorial” 的文档,同时排除含 “kotlin” 的文档,并限定在指定日期范围内。
5. Logstash 数据处理
Logstash 是一个强大的数据处理工具,支持从多种来源采集数据、过滤、转换并输出到目标系统(如 Elasticsearch)。
5.1. Beats 采集器
- Filebeat:用于采集日志文件
- Metricbeat:用于采集系统指标(如 CPU、内存等)
通常,Beats 部署在各节点上,将原始数据发送到 Logstash 进行预处理,再写入 Elasticsearch。
5.2. 配置 Logstash 管道
创建 Logstash 配置文件:
$ mkdir -p ./logstash/pipeline && touch ./logstash/pipeline/logstash.conf
配置内容如下:
input {
file {
path => "/var/log/syslog"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
if [path] =~ "syslog" {
grok {
match => { "message" => "^%{SYSLOGTIMESTAMP:timestamp} %{HOSTNAME:hostname} kernel: %{GREEDYDATA:kernel_message}" }
overwrite => [ "message" ]
}
if ![timestamp] {
drop {}
}
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "kernel-logs"
}
}
重启容器使配置生效:
$ docker compose restart
验证数据是否写入 Elasticsearch:
$ curl -X GET "localhost:9200/kernel-logs/_search?pretty"
返回结果中 hits 字段显示命中的日志条目,说明数据采集成功。
6. Kibana 可视化分析
Kibana 是 Elasticsearch 的可视化前端,支持通过图表、地图、表格等方式展示数据,并可构建交互式仪表盘。
6.1. 配置数据源
访问 Kibana 地址 http://localhost:5601,依次点击:
- Analytics → Discover
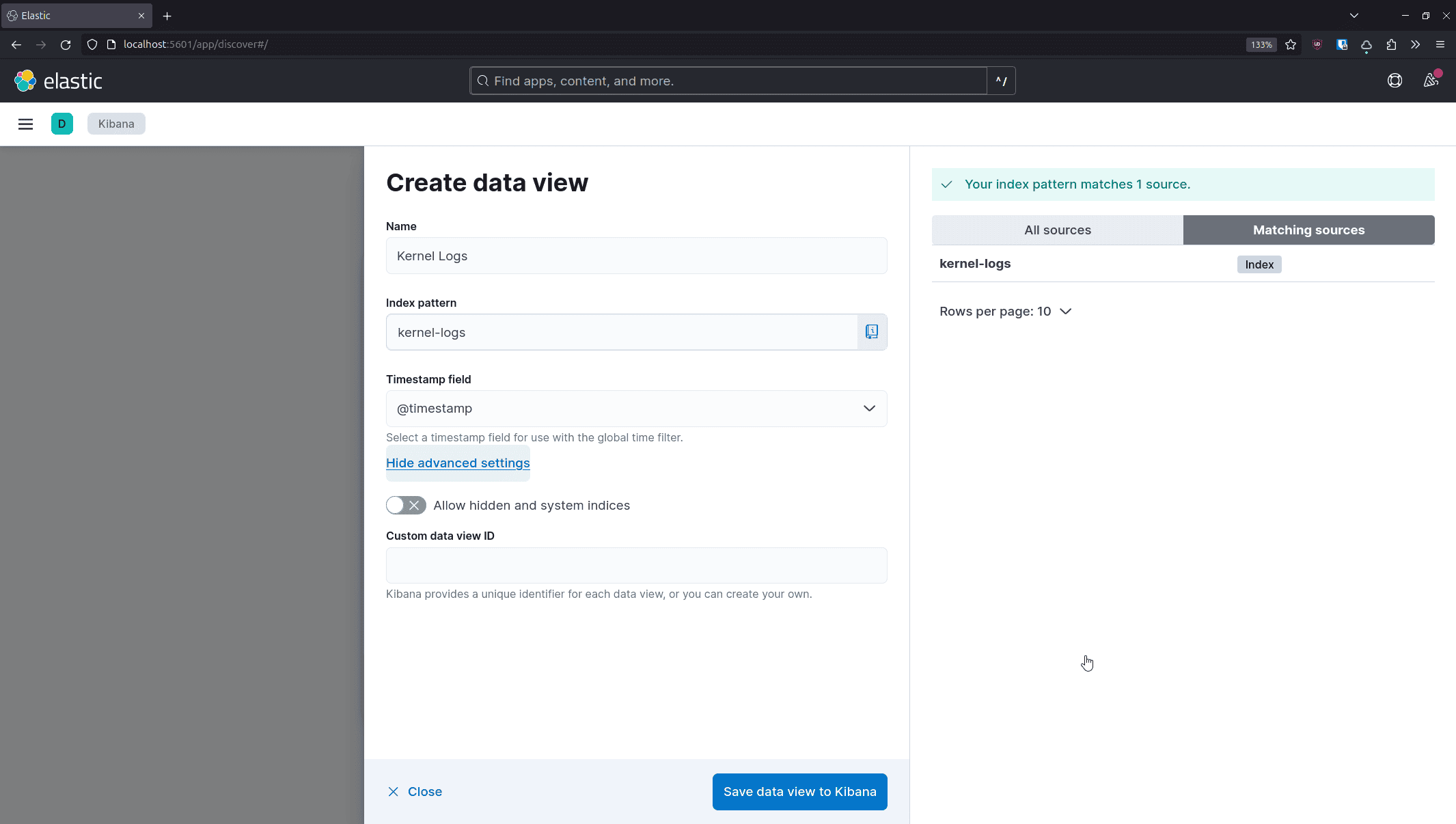
- Create data view
- 输入索引模式
kernel-logs - 保存为数据视图
完成后即可看到采集的日志数据。
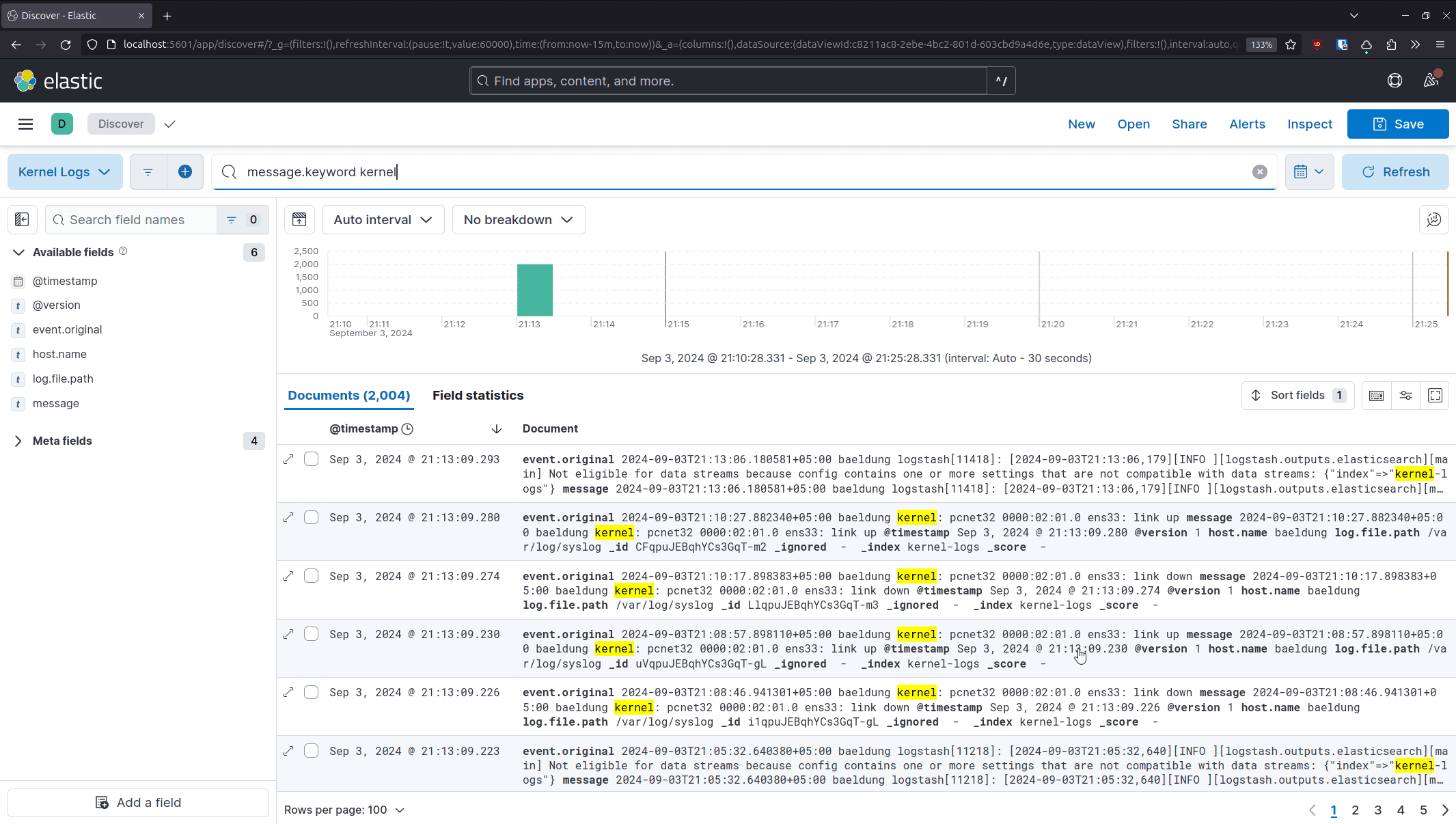
6.2. 使用 KQL 查询日志
Kibana 使用 KQL(Kibana Query Language)进行查询,语法简洁高效:
- 查询包含 "kernel" 的日志:
message.keyword kernel
- 查询包含 "kernel" 和 "bluetooth" 的日志:
message.keyword kernel and message.keyword bluetooth
- 查询最近两天的蓝牙内核日志:
message.keyword kernel and message.keyword bluetooth and @timestamp > now-2d
7. 总结
本文介绍了 ELK Stack 的核心组件及其协同工作机制,并通过 Docker Compose 快速搭建了一个完整的 ELK 环境,演示了从日志采集、处理到可视化的完整流程。
✅ ELK 适合用于日志集中管理、实时分析与监控场景
⚠️ 需注意 Logstash 配置的准确性,避免日志格式不匹配导致数据丢失
✅ Kibana 提供强大的可视化能力,适合构建运维监控看板
如需进一步扩展,可考虑引入 Filebeat 实现更轻量的日志采集,或使用 Elastic Stack 的安全模块(如 APM、SIEM)提升系统可观测性。