1. 简介
在任何企业级系统中,与多个系统集成的能力都是一个核心需求。大型组织通常会拥有多个专业化的系统,它们之间需要高效通信;而在微服务架构中,这种集成能力显得尤为重要。
本文将介绍 Alpakka,一个用于 Java 和 Scala 的流行集成框架。
2. 关于 Alpakka
Alpakka 是一个相对较新的 企业集成框架,它遵循 Reactive Streams 的原则,构建于 Akka 和 Akka Streams 之上。与其他大多数集成框架不同,Alpakka 原生支持流式处理和响应式编程。自诞生以来,它已经对集成系统的构建方式产生了积极影响。
3. 与 Camel 的对比
Apache Camel 是目前业界公认的集成框架首选,支持超过 300 种不同的系统,许多大型企业应用都在使用它。
而 Alpakka 则提供了另一种选择。虽然它还比较年轻,但已经获得了广泛的关注和认可。
相比 Camel,Alpakka 的优势包括:
✅ 更强的类型安全性
✅ 原生支持流式处理和背压(back-pressure)
✅ 针对异步编程提供了更友好的 DSL
4. 示例场景
本文将构建一个简单的集成管道,用于处理来自车辆 IoT 设备的数据。
为了简化场景,我们假设这些设备生成的数据被持续写入一个平面文件(flat file)。当然,实际中也可以是使用 MQTT 协议的设备,或者 Kafka 等复杂的消息系统。
我们将编写一个 Alpakka 连接器,从文件中读取数据并将其写入 MongoDB 数据库。
下图展示了这个集成连接器的概览:
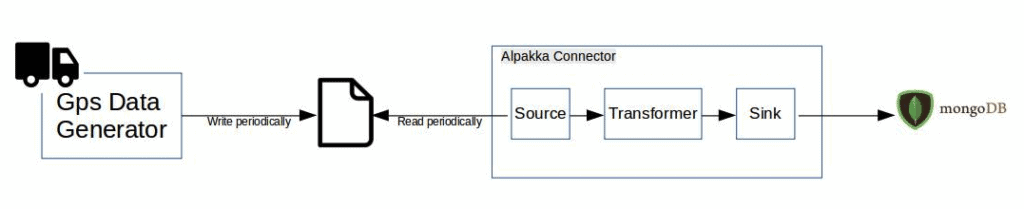
5. 构建 Alpakka 连接器
现在我们开始构建 Alpakka MongoDB 连接器。
5.1. 依赖配置
首先,在 build.sbt 中添加所需的依赖项:
libraryDependencies ++= Seq(
"com.lightbend.akka" %% "akka-stream-alpakka-mongodb" % "5.0.0",
"com.typesafe.akka" %% "akka-stream" % "2.8.0",
"org.mongodb.scala" %% "mongo-scala-driver" % "5.0.0",
"com.lightbend.akka" %% "akka-stream-alpakka-file" % "5.0.0"
)
5.2. 编写连接器逻辑
首先,创建 MongoDB 的数据库连接:
final val client = MongoClients.create("mongodb://localhost:27019")
final val db = client.getDatabase("vehicle-tracker")
接着,定义相关的 case class 以及 codec registry。MongoDB 驱动会使用它来完成 case class 和 BSON 对象之间的转换:
final case class GPSLocation(lat: Double, lng: Double)
final case class VehicleData(vehicleId: Long, location: GPSLocation)
val vehicleCodec = fromRegistries(fromProviders(classOf[VehicleData], classOf[GPSLocation]), DEFAULT_CODEC_REGISTRY)
然后,使用 db 实例创建 MongoCollection:
val vehicleDataCollection: MongoCollection[VehicleData] =
db.getCollection(classOf[VehicleData].getSimpleName, classOf[VehicleData])
.withCodecRegistry(CodecRegistry.vehicleCodec)
我们使用平面文件作为数据源(Alpakka Source),MongoDB 作为数据目标(Alpakka Sink)。FileTailSource 是 Alpakka 提供的持续读取文件内容的组件。
现在,我们可以从文件中读取车辆数据,并将其写入 MongoDB:
val fs = FileSystems.getDefault
def init() = {
FileTailSource.lines(
path = fs.getPath(filePath),
maxLineSize = 8192,
pollingInterval = 100.millis
).map(s => {
val v = s.split(",")
VehicleData(v(0).toLong, GPSLocation(v(1).toDouble, v(2).toDouble))
}).runWith{
MongoSink.insertOne(vehicleCollection)
}
}
在上面这段代码中,FileTailSource 会持续读取文件内容。连接器会按照我们设置的 pollingInterval 定期检查文件是否有新内容。
⚠️ maxLineSize 是每行数据的最大字节数限制。如果某一行数据超过这个限制,整个流会失败。
Akka Streams 的 flow 会将读取到的文件内容转换为 VehicleData 类型的实例,然后由 MongoSink 将其插入 MongoDB。
仅仅用了不到十行代码,我们就构建了一个基于流的集成管道,是不是有点简单粗暴?
6. 其他 Alpakka Source 和 Sink
在上面的例子中,我们使用了 FileTailSource。实际上,我们可以轻松替换为其他 Source,而无需修改 Flow 和 Sink 的逻辑。
比如,我们可以使用一个简单的 Akka Stream Source 来从一个 List 中读取数据:
val simpleSource = Source(List(
"1, 70.23857, 16.239987",
"1, 70.876, 16.188",
"2, 17.87, 77.71443",
"3, 55.7712, 16.9088"
))
然后替换之前的 FileTailSource,其余代码保持不变:
simpleSource.map(s => {...}).runWith{...}
类似地,我们也可以根据实际需求选择其他 Source 或 Sink。
7. 流式处理与背压机制
正如前文所述,Alpakka 天生支持流式处理。由于它构建于 Akka Streams 之上,因此天然支持背压(back-pressure)机制。
在我们的示例中,当 MongoSink 处理速度较慢时,它会减少向上游发送“请求更多数据”的信号。这样,上游的 FileTailSource 也会相应地减缓读取速度,避免内存溢出或系统过载。
✅ 这种机制使得处理大文件或高并发数据成为可能,而不会带来额外的性能负担。
8. 总结
在本文中,我们介绍了 Alpakka,并展示了如何使用它来构建健壮的集成管道。
一如既往,本文中的代码示例可以在 GitHub 上找到。