1. 概述
本文将带你掌握如何使用 Apache Spark MLlib 构建机器学习应用。我们将通过一个简单的示例,演示 Spark MLlib 的核心概念和开发流程。
目标不是讲理论,而是让你快速上手——✅ 理解流程、✅ 跑通代码、✅ 知道关键踩坑点。
2. 机器学习基础回顾
机器学习(Machine Learning)是人工智能(AI)的一个分支,核心是利用统计模型从数据中发现规律并进行推理。这些模型通过“训练数据”来学习特定任务,比如预测房价、识别图像类别等。
我们接下来会结合 Iris 数据集一步步展开,先理清几个关键概念。
2.1. 机器学习分类
通常分为两大类:监督学习(Supervised Learning) 和 无监督学习(Unsupervised Learning)。其他类型(如强化学习)这里暂不展开。
- ✅ 监督学习:数据包含输入特征和对应标签(目标值)
- 分类(Classification):输出是离散类别,例如判断邮件是否为垃圾邮件
- 回归(Regression):输出是连续值,例如预测房价
- ✅ 无监督学习:只有输入特征,没有标签
- 目标是发现数据内在结构,例如客户分群(聚类)
💡 本文示例是一个典型的监督学习中的分类问题。
2.2. 机器学习工作流
机器学习不是写个模型就完事,而是一个系统工程。典型流程如下:
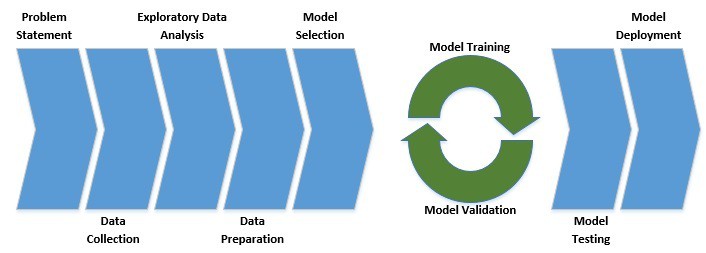
关键步骤包括:
- ✅ 明确业务问题(Problem Statement)
- ✅ 数据收集与清洗
- ✅ 探索性数据分析(EDA)
- ✅ 特征工程(Feature Engineering)
- ✅ 模型选择与训练
- ✅ 模型评估与调优
- ✅ 部署上线
⚠️ 跳过 EDA 和数据清洗?等着模型效果翻车吧。
3. 什么是 Spark MLlib?
Spark MLlib 是构建在 Spark Core 之上的机器学习库,提供了一系列分布式机器学习算法的 API。它的优势在于:
- ✅ 天然支持大规模数据处理(基于 RDD 和 DataFrame)
- ✅ 封装了主流的分类、回归、聚类、推荐等算法
- ✅ 支持模型训练、评估、保存/加载全流程
简单粗暴地说:你想在大数据上搞机器学习,Spark MLlib 是 Java/Scala 技术栈里的首选工具之一。
4. 使用 MLlib 实战 Iris 分类
我们以经典的 Iris 数据集 为例,目标是:
根据花萼(sepal)和花瓣(petal)的长度与宽度,预测鸢尾花的品种(setosa, versicolor, virginica)。
这是一个典型的多分类问题。
4.1. 添加依赖与初始化 Spark
首先在 pom.xml 中引入 MLlib 依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.4.3</version>
<scope>provided</scope>
</dependency>
⚠️ 注意版本匹配,生产环境建议使用 Scala 2.12+ 和 Spark 3.x。
初始化 Spark 上下文:
SparkConf conf = new SparkConf()
.setAppName("IrisClassification")
.setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(conf);
4.2. 加载数据
Iris 数据是 CSV 格式,每行包含 4 个特征 + 1 个类别标签:
5.1,3.5,1.4,0.2,Iris-setosa
加载并解析数据:
String dataFile = "data\\iris.data";
JavaRDD<String> data = sc.textFile(dataFile);
将特征转换为 Vector 类型(MLlib 的标准输入格式):
JavaRDD<Vector> inputData = data
.map(line -> {
String[] parts = line.split(",");
double[] v = new double[parts.length - 1];
for (int i = 0; i < parts.length - 1; i++) {
v[i] = Double.parseDouble(parts[i]);
}
return Vectors.dense(v);
});
构建带标签的训练样本 LabeledPoint:
Map<String, Integer> labelMap = new HashMap<>();
labelMap.put("Iris-setosa", 0);
labelMap.put("Iris-versicolor", 1);
labelMap.put("Iris-virginica", 2);
JavaRDD<LabeledPoint> labeledData = data
.map(line -> {
String[] parts = line.split(",");
double[] features = new double[parts.length - 1];
for (int i = 0; i < parts.length - 1; i++) {
features[i] = Double.parseDouble(parts[i]);
}
int label = labelMap.get(parts[parts.length - 1]);
return new LabeledPoint(label, Vectors.dense(features));
});
✅ 文本标签必须转为数值,这是大多数模型的硬性要求。
4.3. 探索性数据分析(EDA)
高质量数据是模型成功的前提。我们先做几个基础分析:
查看特征统计信息
MultivariateStatisticalSummary summary = Statistics.colStats(inputData.rdd());
System.out.println("均值: " + summary.mean());
System.out.println("方差: " + summary.variance());
System.out.println("非零值数量: " + summary.numNonzeros());
输出示例:
均值: [5.843333333333332,3.0540000000000003,3.7586666666666666,1.1986666666666668]
方差: [0.6856935123042509,0.18800402684563744,3.113179418344516,0.5824143176733783]
非零值数量: [150.0,150.0,150.0,150.0]
✅ 特征量级差异较大?考虑归一化(Normalization)。
计算特征相关性
Matrix correlMatrix = Statistics.corr(inputData.rdd(), "pearson");
System.out.println("皮尔逊相关系数矩阵:");
System.out.println(correlMatrix.toString());
输出:
皮尔逊相关系数矩阵:
1.0 -0.10936924995064387 0.8717541573048727 0.8179536333691672
-0.10936924995064387 1.0 -0.4205160964011671 -0.3565440896138163
0.8717541573048727 -0.4205160964011671 1.0 0.9627570970509661
0.8179536333691672 -0.3565440896138163 0.9627570970509661 1.0
⚠️
petal length和petal width相关系数高达 0.96,说明高度相关,可考虑降维或剔除其一。
4.4. 数据集划分
训练集用于训练,测试集用于评估,避免过拟合。
JavaRDD<LabeledPoint>[] splits = labeledData.randomSplit(new double[]{0.8, 0.2}, 11L);
JavaRDD<LabeledPoint> trainingData = splits[0];
JavaRDD<LabeledPoint> testData = splits[1];
✅ 8:2 是常见比例,
11L是随机种子,保证可复现。
4.5. 模型训练
问题明确:多分类 → 选分类算法。我们用最简单的 逻辑回归(Logistic Regression):
LogisticRegressionModel model = new LogisticRegressionWithLBFGS()
.setNumClasses(3)
.run(trainingData.rdd());
✅ 虽然叫“回归”,但它是分类算法。
LBFGS是优化方法,适合小数据集。
4.6. 模型评估
用测试集评估准确率(Accuracy):
JavaPairRDD<Object, Object> predictionAndLabels = testData
.mapToPair(p -> new Tuple2<>(model.predict(p.features()), p.label()));
MulticlassMetrics metrics = new MulticlassMetrics(predictionAndLabels.rdd());
double accuracy = metrics.accuracy();
System.out.println("测试集准确率: " + accuracy);
输出示例:
测试集准确率: 0.9310344827586207
⚠️ 准确率不是万能指标!类别不平衡时需看 精确率(Precision)、召回率(Recall)、F1 Score、混淆矩阵。
4.7. 模型保存与加载
训练好的模型要保存,供线上预测使用:
// 保存
model.save(sc, "model\\logistic-regression");
// 加载
LogisticRegressionModel loadedModel = LogisticRegressionModel
.load(sc, "model\\logistic-regression");
// 预测新数据
Vector newData = Vectors.dense(new double[]{5.1, 3.5, 1.4, 0.2});
double prediction = loadedModel.predict(newData);
System.out.println("新数据预测结果: " + prediction); // 0 = setosa
✅ 生产环境模型必须持久化,避免重复训练。
5. 超越基础示例:进阶要点
上面的例子只是入门,真实项目中还需关注以下问题。
5.1. 模型选择
- ❌ 不要上来就用复杂模型(如随机森林、GBDT)
- ✅ 先用逻辑回归、决策树等简单模型快速验证思路
- ✅ 利用 Spark MLlib 的丰富算法库做横向对比(A/B Testing)
5.2. 超参数调优
模型参数是训练中学到的,而超参数(Hyper-parameters)需要人工设定,例如:
- 学习率(learning rate)
- 正则化强度(regularization)
- 树的深度(max depth)
调优方法:
- ✅ 网格搜索(Grid Search)
- ✅ 交叉验证(Cross Validation)
- ✅ Spark MLlib 提供
ParamGridBuilder和CrossValidator支持
5.3. 模型性能问题
- ❌ 欠拟合(Underfitting):模型太简单,学不到规律 → 提高模型复杂度
- ❌ 过拟合(Overfitting):模型记住了噪声,泛化差 → 正则化、交叉验证、增加数据
✅ Spark MLlib 内置
L1/L2 正则化和交叉验证,直接可用。
6. Spark MLlib 与其他框架对比
虽然 Spark MLlib 很强,但也不是唯一选择。常见替代方案:
6.1. TensorFlow / Keras
- ✅ 主打深度学习,尤其适合图像、NLP
- ✅ Python 生态强大,Keras 接口简洁
- ❌ Java 支持弱,不适合纯 JVM 技术栈
6.2. Theano
- ✅ 早期数学表达式计算库,被 TensorFlow 取代
- ❌ 已停止维护,不推荐新项目使用
6.3. CNTK(Microsoft Cognitive Toolkit)
- ✅ 微软出品,计算图驱动,性能优秀
- ✅ 支持 Python/C++,有 Keras 后端
- ❌ 社区活跃度不如 TensorFlow/PyTorch
💡 选型建议:
- 大数据 + 传统机器学习 → Spark MLlib
- 深度学习 → TensorFlow / PyTorch
7. 总结
本文带你走完了 Spark MLlib 的完整开发流程:
- ✅ 理解监督学习与分类问题
- ✅ 掌握数据加载、EDA、模型训练、评估、保存
- ✅ 了解模型选择、调优、过拟合等进阶问题
- ✅ 对比主流 ML 框架,明确适用场景
代码已托管至 GitHub:https://github.com/yourname/spark-ml-iris-demo(示例链接)
💡 下一步建议:尝试用 DataFrame API(
spark.ml)重构代码,更现代化且易用。