1. 概述
AI 技术已成为现代开发的核心技能。本文将构建一个 RAG Wiki 应用,它能基于存储的文档回答用户问题。
我们将使用 Spring AI 集成 MongoDB 向量数据库 和 LLM。
2. RAG 应用
当自然语言生成需要依赖上下文数据时,我们使用 检索增强生成(RAG) 应用。RAG 应用的核心组件是 向量数据库,它在高效管理和检索数据中扮演关键角色:
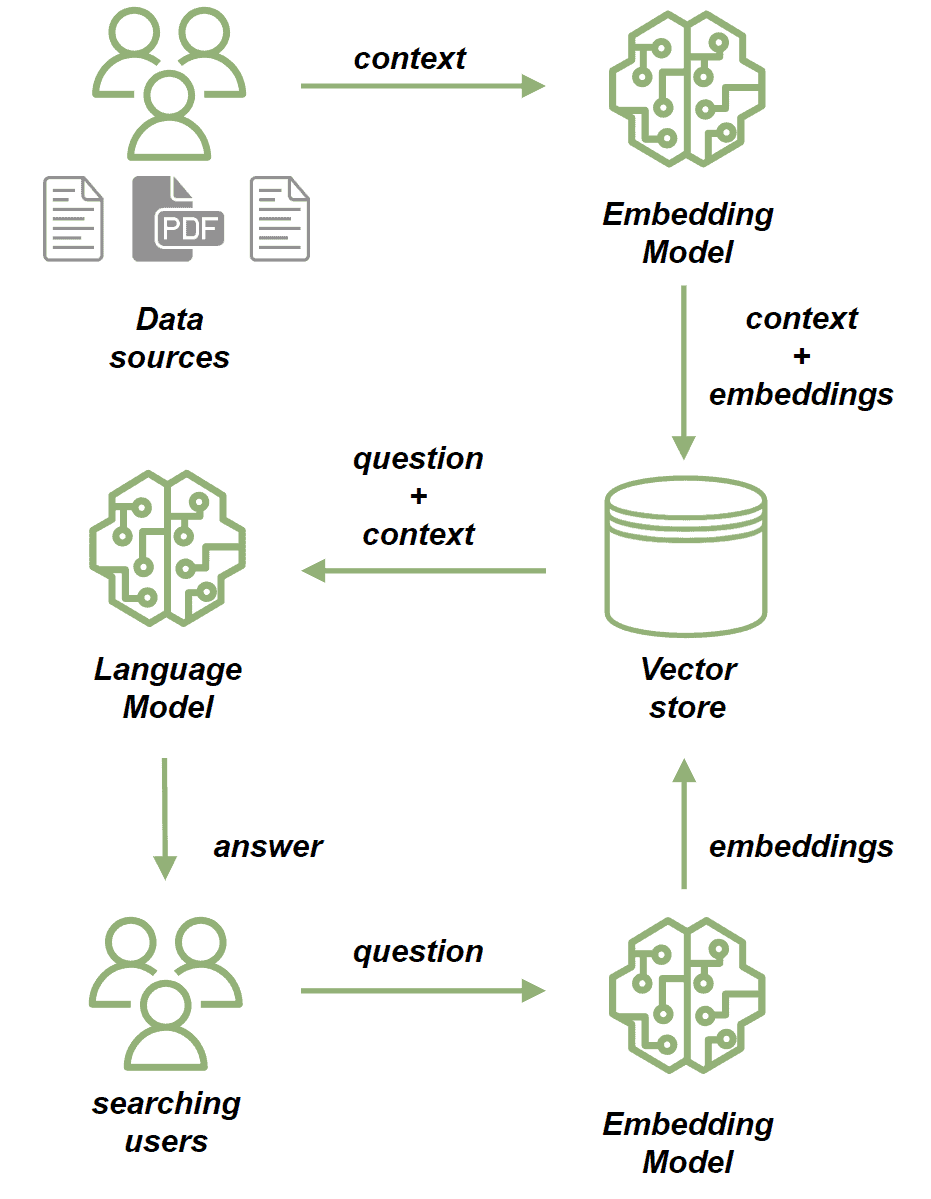
我们使用 嵌入模型 处理源文档。该模型将文档文本转换为高维向量。这些向量捕获内容的语义含义,使我们能基于上下文而非仅关键词匹配来比较和检索相似内容。然后将文档存储在向量存储中。
保存文档后,我们可以通过以下方式基于它们发送提示:
- 首先用嵌入模型处理问题,将其转换为捕获语义含义的向量
- 接着执行相似性搜索,将问题向量与向量存储中的文档向量比较
- 从最相关文档中构建问题的上下文
- 最后将问题和上下文发送给 LLM,生成与查询相关且被上下文丰富化的回答
3. MongoDB Atlas 向量搜索
本教程使用 MongoDB Atlas Search 作为向量存储。它提供的 向量搜索 功能能满足项目需求。为测试环境设置本地 MongoDB Atlas Search 实例,我们使用 mongodb-atlas-local Docker 容器。创建 docker-compose.yml 文件:
version: '3.1'
services:
my-mongodb:
image: mongodb/mongodb-atlas-local:7.0.9
container_name: my-mongodb
environment:
- MONGODB_INITDB_ROOT_USERNAME=wikiuser
- MONGODB_INITDB_ROOT_PASSWORD=password
ports:
- 27017:27017
4. 依赖与配置
首先添加必要依赖。由于应用提供 HTTP API,引入 spring-boot-starter-web 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>LATEST_VERSION</version>
</dependency>
为连接 LLM 添加 OpenAI API 客户端 依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>LATEST_VERSION</version>
</dependency>
最后添加 MongoDB Atlas Store 依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mongodb-atlas-store-spring-boot-starter</artifactId>
<version>LATEST_VERSION</version>
</dependency>
现在添加应用配置属性:
spring:
data:
mongodb:
uri: mongodb://wikiuser:password@localhost:27017/admin
database: wiki
ai:
vectorstore:
mongodb:
collection-name: vector_store
initialize-schema: true
path-name: embedding
indexName: vector_index
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-3.5-turbo
我们指定了 MongoDB URL 和数据库名,并通过设置集合名称、嵌入字段名和向量索引名配置向量存储。得益于 initialize-schema 属性,Spring AI 框架会自动创建这些资源。
最后添加 OpenAI API 密钥 和 模型版本。
5. 将文档保存到向量存储
现在添加数据保存流程。应用将基于现有文档回答用户问题——本质上充当 Wiki。
添加存储文件内容和路径的模型:
public class WikiDocument {
private String filePath;
private String content;
// 标准 getter/setter
}
下一步添加 WikiDocumentsRepository。该仓库封装所有持久化逻辑:
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
@Component
public class WikiDocumentsRepository {
private final VectorStore vectorStore;
public WikiDocumentsRepository(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public void saveWikiDocument(WikiDocument wikiDocument) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("filePath", wikiDocument.getFilePath());
Document document = new Document(wikiDocument.getContent(), metadata);
List<Document> documents = new TokenTextSplitter().apply(List.of(document));
vectorStore.add(documents);
}
}
这里注入了 VectorStore 接口 Bean,由 spring-ai-mongodb-atlas-store-spring-boot-starter 提供的 MongoDBAtlasVectorStore 实现。在 saveWikiDocument 方法中,创建 Document 实例并填充内容和元数据。
然后使用 TokenTextSplitter 将文档分割为小块并保存到向量存储。现在创建 WikiDocumentsServiceImpl:
@Service
public class WikiDocumentsServiceImpl {
private final WikiDocumentsRepository wikiDocumentsRepository;
// 构造函数
public void saveWikiDocument(String filePath) {
try {
String content = Files.readString(Path.of(filePath));
WikiDocument wikiDocument = new WikiDocument();
wikiDocument.setFilePath(filePath);
wikiDocument.setContent(content);
wikiDocumentsRepository.saveWikiDocument(wikiDocument);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
在服务层读取文件内容,创建 WikiDocument 实例并交由仓库持久化。
控制器中简单传递文件路径到服务层,成功保存时返回 201 状态码:
@RestController
@RequestMapping("wiki")
public class WikiDocumentsController {
private final WikiDocumentsServiceImpl wikiDocumentsService;
// 构造函数
@PostMapping
public ResponseEntity<Void> saveDocument(@RequestParam String filePath) {
wikiDocumentsService.saveDocument(filePath);
return ResponseEntity.status(201).build();
}
}
⚠️ 注意该接口的安全问题:用户可能通过此接口上传配置或系统文件等意外文件。解决方案是限制可上传文件的目录范围。现在启动应用测试流程。添加 Spring Boot 测试依赖以建立测试 Web 上下文:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>LATEST_VERSION</version>
</dependency>
启动测试应用实例并调用两个文档的 POST 接口:
@AutoConfigureMockMvc
@ExtendWith(SpringExtension.class)
@SpringBootTest
class RAGMongoDBApplicationManualTest {
@Autowired
private MockMvc mockMvc;
@Test
void givenMongoDBVectorStore_whenCallingPostDocumentEndpoint_thenExpectedResponseCodeShouldBeReturned() throws Exception {
mockMvc.perform(post("/wiki?filePath={filePath}",
"src/test/resources/documentation/owl-documentation.md"))
.andExpect(status().isCreated());
mockMvc.perform(post("/wiki?filePath={filePath}",
"src/test/resources/documentation/rag-documentation.md"))
.andExpect(status().isCreated());
}
}
两次调用均应返回 201 状态码,表示文档已添加。使用 MongoDB Compass 确认文档成功保存到向量存储: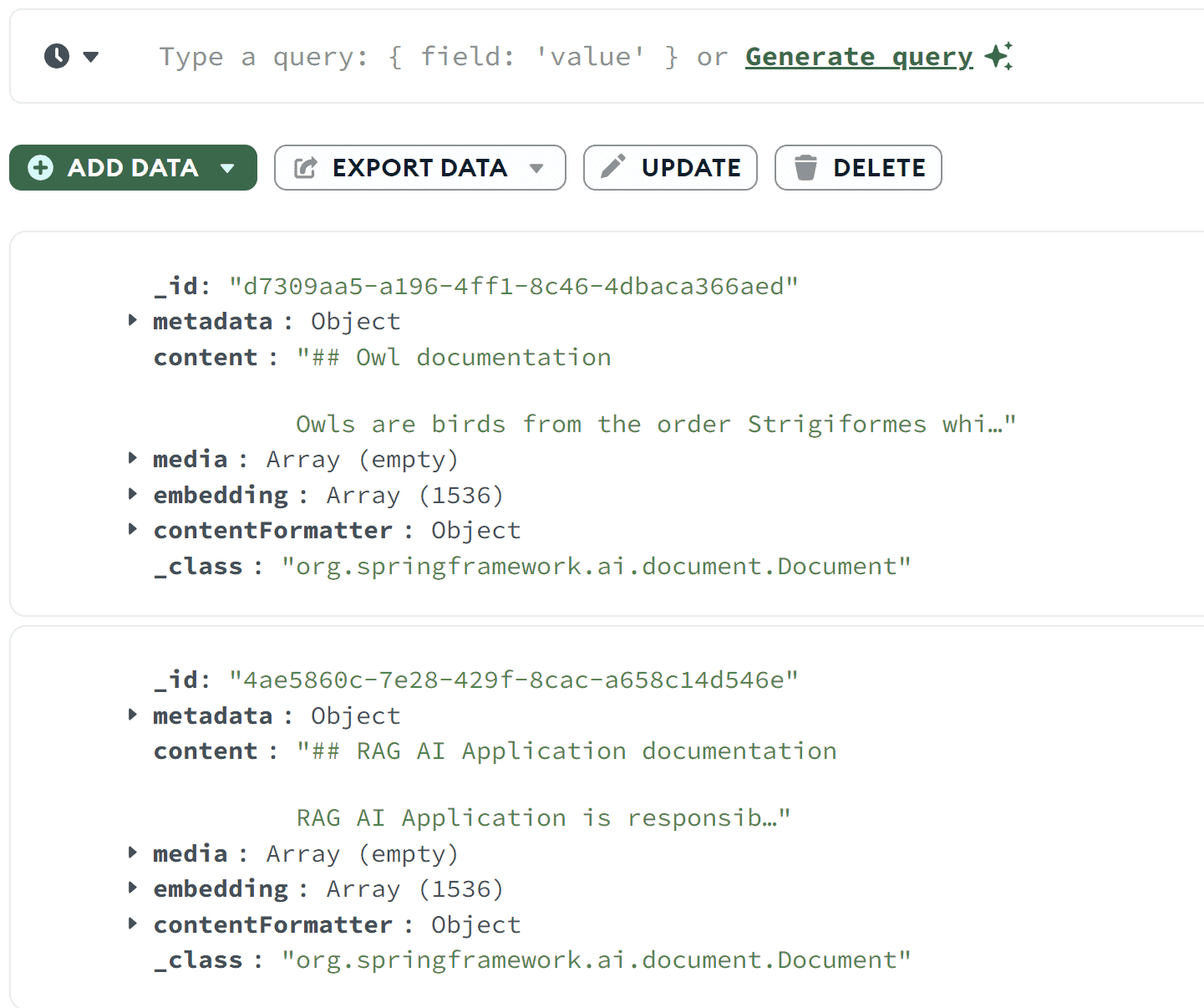
如你所见——两个文档均已保存。可以看到原始内容和嵌入数组。
6. 相似性搜索
添加相似性搜索功能。在仓库中添加 findSimilarDocuments 方法:
@Component
public class WikiDocumentsRepository {
private final VectorStore vectorStore;
public List<WikiDocument> findSimilarDocuments(String searchText) {
return vectorStore
.similaritySearch(SearchRequest
.query(searchText)
.withSimilarityThreshold(0.87)
.withTopK(10))
.stream()
.map(document -> {
WikiDocument wikiDocument = new WikiDocument();
wikiDocument.setFilePath((String) document.getMetadata().get("filePath"));
wikiDocument.setContent(document.getContent());
return wikiDocument;
})
.toList();
}
}
调用了 VectorStore 的 similaritySearch 方法。除搜索文本外,还指定了结果限制和相似性阈值。相似性阈值参数用于控制文档内容与搜索文本的匹配程度。
服务层代理仓库调用:
public List<WikiDocument> findSimilarDocuments(String searchText) {
return wikiDocumentsRepository.findSimilarDocuments(searchText);
}
控制器添加 GET 接口接收搜索文本参数:
@RestController
@RequestMapping("/wiki")
public class WikiDocumentsController {
@GetMapping
public List<WikiDocument> get(@RequestParam("searchText") String searchText) {
return wikiDocumentsService.findSimilarDocuments(searchText);
}
}
调用新接口测试相似性搜索:
@Test
void givenMongoDBVectorStoreWithDocuments_whenMakingSimilaritySearch_thenExpectedDocumentShouldBePresent() throws Exception {
String responseContent = mockMvc.perform(get("/wiki?searchText={searchText}", "RAG Application"))
.andExpect(status().isOk())
.andReturn()
.getResponse()
.getContentAsString();
assertThat(responseContent)
.contains("RAG AI Application is responsible for storing the documentation");
}
使用非完全匹配的搜索文本调用接口。但仍检索到相似内容的文档,并确认其包含 rag-documentation.md 文件中的文本。
7. 提示接口
开始构建提示流程——应用的核心功能。首先创建 AdvisorConfiguration:
@Configuration
public class AdvisorConfiguration {
@Bean
public QuestionAnswerAdvisor questionAnswerAdvisor(VectorStore vectorStore) {
return new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults());
}
}
创建 QuestionAnswerAdvisor Bean,负责构建提示请求(包括初始问题)。此外它会将向量存储的相似性搜索结果作为问题上下文附加。现在向 API 添加搜索接口:
@RestController
@RequestMapping("/wiki")
public class WikiDocumentsController {
private final WikiDocumentsServiceImpl wikiDocumentsService;
private final ChatClient chatClient;
private final QuestionAnswerAdvisor questionAnswerAdvisor;
public WikiDocumentsController(WikiDocumentsServiceImpl wikiDocumentsService,
@Qualifier("openAiChatModel") ChatModel chatModel,
QuestionAnswerAdvisor questionAnswerAdvisor) {
this.wikiDocumentsService = wikiDocumentsService;
this.questionAnswerAdvisor = questionAnswerAdvisor;
this.chatClient = ChatClient.builder(chatModel).build();
}
@GetMapping("/search")
public String getWikiAnswer(@RequestParam("question") String question) {
return chatClient.prompt()
.user(question)
.advisors(questionAnswerAdvisor)
.call()
.content();
}
}
通过向提示添加用户输入并附加 QuestionAnswerAdvisor 构建提示请求。
最后调用接口查看关于 RAG 应用的回答:
@Test
void givenMongoDBVectorStoreWithDocumentsAndLLMClient_whenAskQuestionAboutRAG_thenExpectedResponseShouldBeReturned() throws Exception {
String responseContent = mockMvc.perform(get("/wiki/search?question={question}", "Explain the RAG Applications"))
.andExpect(status().isOk())
.andReturn()
.getResponse()
.getContentAsString();
logger.atInfo().log(responseContent);
assertThat(responseContent).isNotEmpty();
}
发送问题 "Explain the RAG applications" 并记录 API 响应:
b.s.r.m.RAGMongoDBApplicationManualTest : Based on the context provided, the RAG AI Application is a tool
used for storing documentation and enabling users to search for specific information efficiently...
接口返回了基于向量数据库中存储的文档的 RAG 应用信息。
现在尝试询问知识库中肯定不存在的内容:
@Test
void givenMongoDBVectorStoreWithDocumentsAndLLMClient_whenAskUnknownQuestion_thenExpectedResponseShouldBeReturned() throws Exception {
String responseContent = mockMvc.perform(get("/wiki/search?question={question}", "Explain the Economic theory"))
.andExpect(status().isOk())
.andReturn()
.getResponse()
.getContentAsString();
logger.atInfo().log(responseContent);
assertThat(responseContent).isNotEmpty();
}
询问经济理论后得到响应:
b.s.r.m.RAGMongoDBApplicationManualTest : I'm sorry, but the economic theory is not directly related to the information provided about owls and the RAG AI Application.
If you have a specific question about economic theory, please feel free to ask.
这次应用未找到相关文档,也未使用其他来源提供答案。
8. 总结
本文使用 Spring AI 框架成功实现了 RAG 应用,该框架是集成各种 AI 技术的绝佳工具。同时 MongoDB 被证明是处理向量存储的强大选择。
凭借这种强大组合,我们可以构建基于现代 AI 的各类应用,包括聊天机器人、自动化 Wiki 系统和搜索引擎。
代码已发布在 GitHub。