1. 引言
本文将深入探讨 Apache Iceberg——当前大数据领域最流行的开放表格式之一。我们将通过实际操作案例,解析 Iceberg 的核心架构和关键特性,帮助开发者快速掌握这一技术。
2. Apache Iceberg 的起源
Iceberg 由 Netflix 的 Ryan Blue 和 Dan Weeks 于 2017 年左右发起。它的诞生主要源于 Hive 表格式的局限性,其中最致命的问题是缺乏稳定的原子事务保证,无法确保数据一致性。
Iceberg 的设计目标直击痛点,提供三大核心改进:
- ✅ 支持 ACID 事务,保障数据正确性
- ✅ 通过文件级细粒度操作提升性能
- ✅ 简化并自动化表维护流程
后来 Iceberg 开源并捐赠给 Apache 基金会,2020 年成为顶级项目。如今 Apache Iceberg 已成为事实上的开放表格式标准,几乎所有主流大数据厂商都提供支持。
3. Apache Iceberg 架构解析
Iceberg 的关键架构决策是通过跟踪文件列表而非目录结构管理数据,这种设计带来显著优势,比如大幅提升查询性能。
整个架构分为三层,核心在于元数据层的设计:
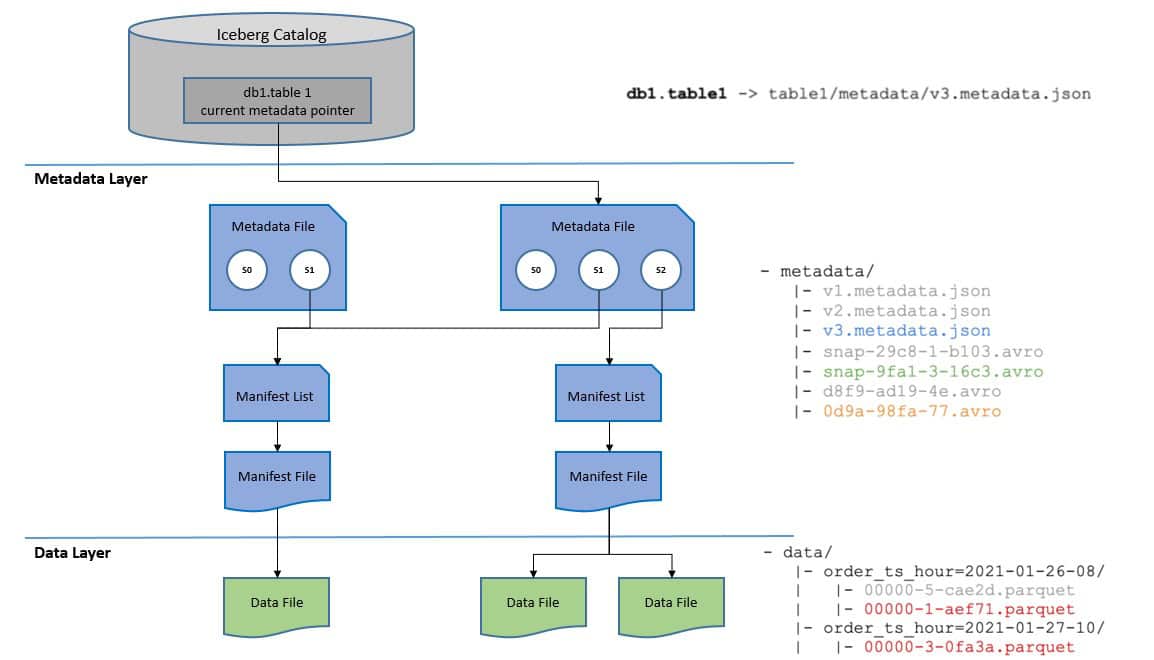
当读取 Iceberg 表时,系统通过当前快照(s1)加载元数据。更新操作会乐观地创建新元数据文件并生成新快照(s2)。随后原子性地更新当前元数据指针指向新文件。若更新基于的快照(s1)已失效,则写入操作必须中止。
3.1. 目录层(Catalog Layer)
目录层核心功能是存储当前元数据指针的位置。任何计算引擎操作 Iceberg 表时,都必须先访问目录获取该指针。
目录层还支持原子操作更新元数据指针,这是实现 Iceberg 表原子事务的基础。不同目录提供的功能各异,例如 Nessie 提供了 Git 风格的数据版本控制能力。
3.2. 元数据层(Metadata Layer)
元数据层包含文件层级结构:顶层是存储 Iceberg 表元数据的元数据文件,它记录表结构、分区配置、自定义属性、快照列表及当前快照。
元数据文件指向清单列表(manifest list),后者包含构成快照的所有清单文件信息(如位置和所属快照)。最终,清单文件(manifest file)跟踪数据文件并提供额外细节,使 Iceberg 能在文件级别管理数据,显著提升读取效率。
3.3. 数据层(Data Layer)
数据层存放实际数据文件,通常位于 AWS S3 等云对象存储服务。Iceberg 支持多种文件格式:
- Apache Parquet(默认)
- Apache Avro
- Apache ORC
Parquet 作为默认格式,采用列式存储,优势在于:
- ✅ 高效压缩和编码方案
- ✅ 针对宽表特定列查询的优化访问
- ✅ 显著的存储效率提升
4. Apache Iceberg 核心特性
Iceberg 提供事务一致性,允许多个应用协同处理同一数据集。其标志性特性包括快照、完整模式演进和隐藏分区。
4.1. 快照(Snapshots)
Iceberg 表元数据维护快照日志记录所有变更,每个快照代表表的特定时间状态。基于快照可实现:
- 读取隔离
- 时间旅行查询
快照生命周期管理通过分支(branches)和标签(tags)实现——它们是快照的命名引用:
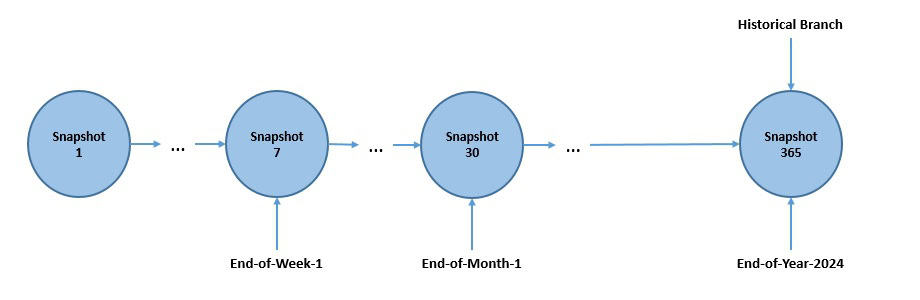
如图所示,我们为重要快照打上“end-of-week”、“end-of-month”等标签用于审计保留。分支和标签的典型场景包括:
- 保留审计所需的历史快照
- 实现数据版本控制
- 支持实验性数据处理流程
⚠️ 注意:表模式在所有分支间保持一致,但查询标签时使用快照自身的模式。
4.2. 分区(Partitioning)
Iceberg 在写入时按相似行分组实现分区。例如按日期分区日志事件,将同日期数据归集到同一文件。这样查询时可跳过无关日期文件,大幅提升性能。
Iceberg 的杀手锏是隐藏分区——自动处理分区值生成这个繁琐易错的任务。用户无需了解分区细节,分区布局可随需求灵活调整。这与 Hive 等早期格式形成鲜明对比:
- ❌ Hive:需手动提供分区值,查询与分区方案强耦合
- ✅ Iceberg:分区演进不影响现有查询
4.3. 演进(Evolution)
Iceberg 支持“原地表演进”,无需重写数据或迁移表即可:
- 修改表结构(包括嵌套字段)
- 调整分区布局适应数据量变化
底层实现仅通过元数据变更完成模式演进,不涉及数据文件重写。分区更新同样灵活:
- 旧数据保持原有分区规范
- 新数据采用新分区规范
- 各分区版本元数据独立维护
5. Apache Iceberg 实战指南
作为开放社区标准,Iceberg 与现代数据架构高度兼容。本节我们将部署基于 Minio 存储的 Iceberg REST 目录,使用 Trino 作为查询引擎。
5.1. 环境搭建
使用 Docker 部署组件(推荐 Docker Desktop 或 Podman)。首先创建 Docker 网络:
docker network create data-network
部署带持久化存储的 Minio(挂载主机 data 目录):
docker run --name minio --net data-network -p 9000:9000 -p 9001:9001 \
--volume .\data:/data quay.io/minio/minio:RELEASE.2024-09-13T20-26-02Z.fips \
server /data --console-address ":9001"
部署 Iceberg REST 目录(基于 [Tabular](https://www.tabular.io/blog/introducing-tabular/)贡献的镜像):
docker run --name iceberg-rest --net data-network -p 8181:8181 \
--env-file ./env.list \
tabulario/iceberg-rest:1.6.0
环境变量文件 env.list 内容:
CATALOG_WAREHOUSE=s3://warehouse/
CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
CATALOG_S3_ENDPOINT=http://minio:9000
CATALOG_S3_PATH-STYLE-ACCESS=true
AWS_ACCESS_KEY_ID=minioadmin
AWS_SECRET_ACCESS_KEY=minioadmin
AWS_REGION=us-east-1
部署 Trino 并配置连接:
docker run --name trino --net data-network -p 8080:8080 \
--volume .\catalog:/etc/trino/catalog \
--env-file ./env.list \
trinodb/trino:449
目录配置文件 catalog/iceberg.properties:
connector.name=iceberg
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http://iceberg-rest:8181/
iceberg.rest-catalog.warehouse=s3://warehouse/
iceberg.file-format=PARQUET
hive.s3.endpoint=http://minio:9000
hive.s3.path-style-access=true
环境变量文件 env.list(与之前相同):
AWS_ACCESS_KEY_ID=minioadmin
AWS_SECRET_ACCESS_KEY=minioadmin
AWS_REGION=us-east-1
⚠️ 注意:hive.s3.path-style-access 是 Minio 特需配置,AWS S3 不需要。
5.2. 数据操作实战
通过 Trino CLI 操作数据(进入容器):
docker exec -it trino trino
查看可用目录:
trino> SHOW catalogs;
Catalog
---------
iceberg
system
(2 rows)
创建 Schema(对应 Iceberg 的命名空间):
trino> CREATE SCHEMA iceberg.demo;
CREATE SCHEMA
创建表:
trino> CREATE TABLE iceberg.demo.customer (
-> id INT,
-> first_name VARCHAR,
-> last_name VARCHAR,
-> age INT);
CREATE TABLE
插入测试数据:
trino> INSERT INTO iceberg.demo.customer (id, first_name, last_name, age) VALUES
-> (1, 'John', 'Doe', 24),
-> (2, 'Jane', 'Brown', 28),
-> (3, 'Alice', 'Johnson', 32),
-> (4, 'Bob', 'Williams', 26),
-> (5, 'Charlie', 'Smith', 35);
INSERT: 5 rows
查询验证:
trino> SELECT * FROM iceberg.demo.customer;
id | first_name | last_name | age
----+------------+-----------+-----
1 | John | Doe | 24
2 | Jane | Brown | 28
3 | Alice | Johnson | 32
4 | Bob | Williams | 26
5 | Charlie | Smith | 35
(5 rows)
简单粗暴的结论:用标准 SQL 就能操作这个为海量数据设计的开放表格式!
5.3. 文件结构探秘
通过 Minio 控制台(http://localhost:9001)查看 warehouse/demo 目录结构:
-
data/:存放实际数据文件 -
metadata/:元数据文件
元数据目录内容:
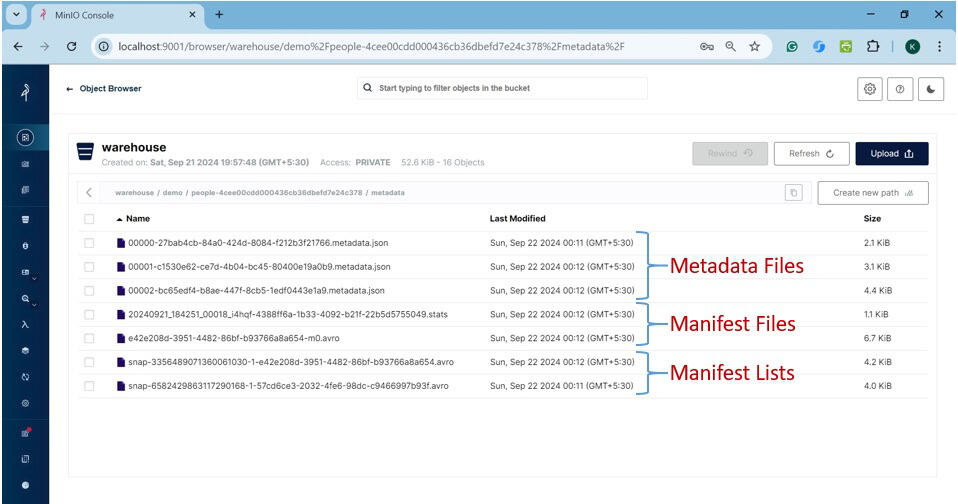
包含三类文件:
-
*.metadata.json:元数据文件 -
snap-*.avro:清单列表 -
*.avro和*.stats:清单文件及统计信息(用于查询优化)
数据目录内容:
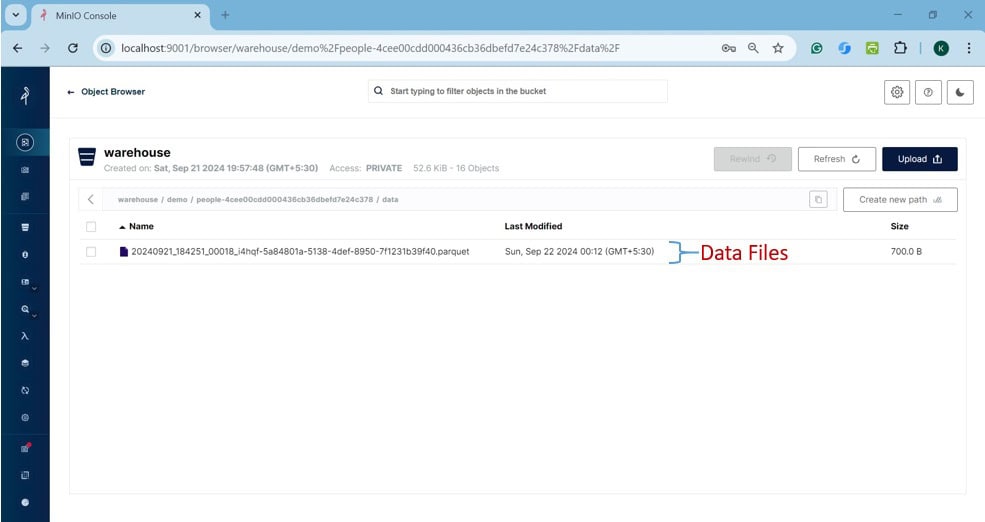
包含 Parquet 格式的数据文件,存储我们插入的实际数据。
6. 总结
Apache Iceberg 已成为实现数据湖仓架构的首选方案,其核心优势包括:
- ✅ 快照机制实现时间旅行查询
- ✅ 隐藏分区简化运维
- ✅ 原地表演进支持灵活架构
配合 REST 目录规范,Iceberg 正快速成为开放表格式的事实标准。对于需要处理海量数据的现代数据平台,Iceberg 提供了兼具性能与灵活性的解决方案。