1. Introduction
In this tutorial, we’ll explain how data lakehouse forms the basis of modern open data architecture.
Further, we’ll explain table format as the underlying technology behind data lakehouses and discuss some of the popular open table formats in the industry.
2. Evolution of Big Data Technologies
Data has always been at the center of decision-making. In the early days, data was largely structured and predictable in volume and velocity. However, the velocity and volume of data saw tremendous growth in the Internet age, not to mention the variety of structured, semi-structured, and unstructured data.
One of the earliest big data architectures was a data warehouse, a unified data repository that brought together large volumes of data from various sources within an organization. However, data warehouses had high implementation and maintenance costs and struggled with semi-structured and unstructured data.
This led to the popularity of Apache Hadoop as an open-source distributed data processing technology for building data lakes. A data lake is a centralized repository that stores large volumes of structured and unstructured data in its raw form. However, data lakes lacked some of the key attributes of a data warehouse.
A data lakehouse combines the key benefits of data lakes and warehouses:
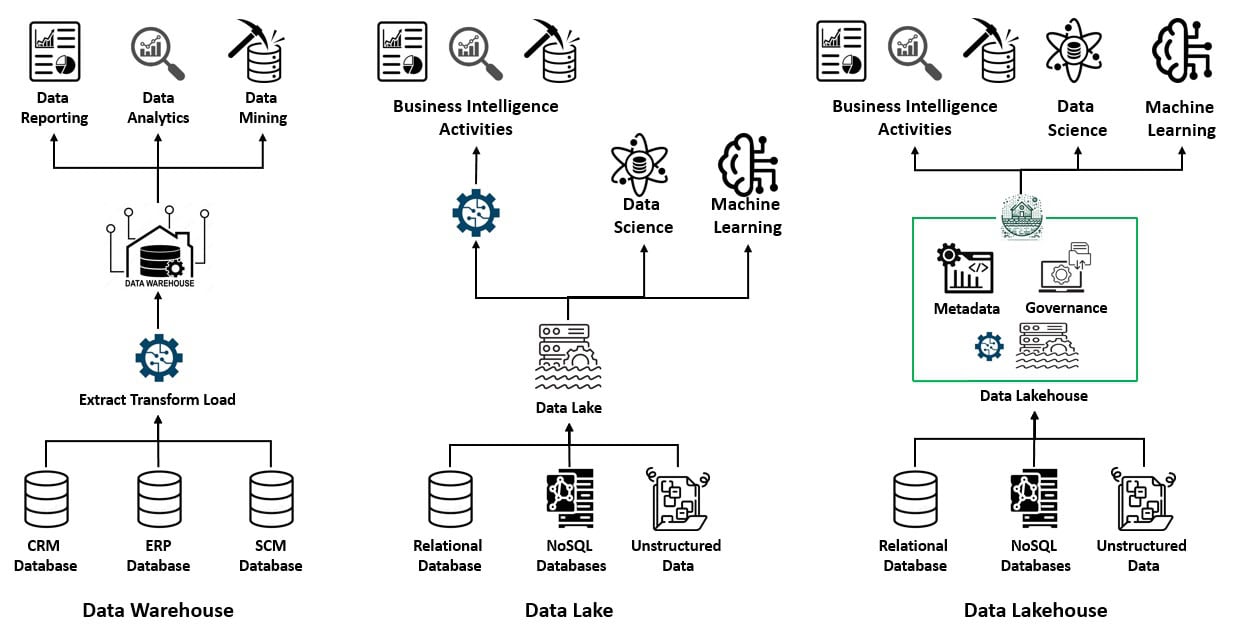
It typically starts as a data lake containing all data types. Then, the lakehouse adds metadata and governance layers on top to bring the management features. Data lakehouses support ACID transactions, allowing multiple parties to read and write data concurrently, typically using SQL.
3. Table Format in Data Lakehouse?
A data lakehouse is the underlying technology of the modern open data architecture, which is built around open standards for storage and communication. One key advantage of a data lakehouse is that it decouples compute from the underlying storage, enabling much higher scalability. Further, it offers attributes like schema enforcement and governance.
It allows us to create a more flexible and highly composable data platform. An open data platform is typically built on a cloud platform like Amazon S3. It offers more flexible, scalable, and affordable storage at petabytes scale. Further, data lakehouses rely on open-source components like file formats, table formats, and compute engines:
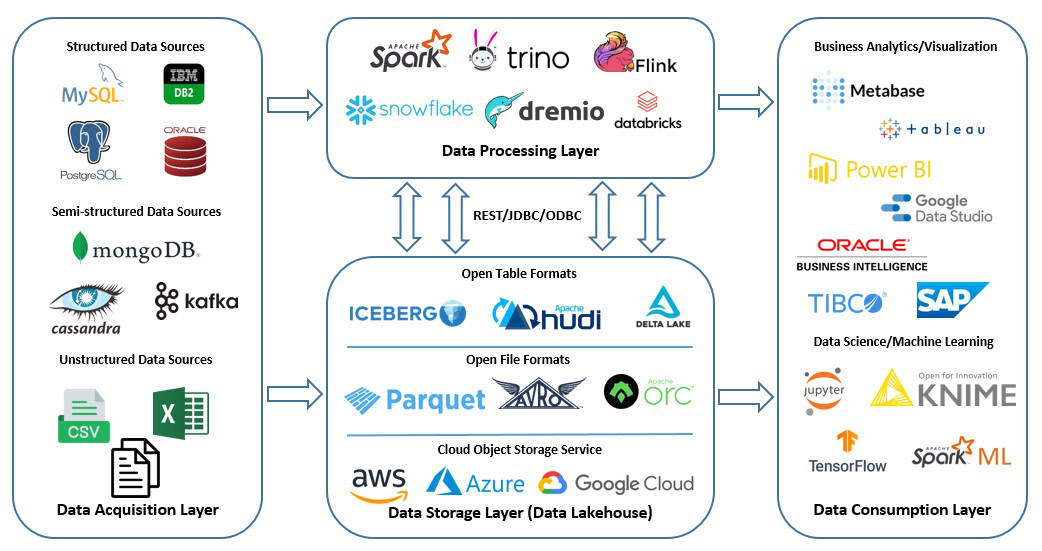
A file format specifies how data is written to storage. Columnar file formats, for instance, provide efficient data storage and enhance query performance. Some popular columnar file formats include Apache Parquet, Apache Avro, and Apache ORC. However, we need a management layer on top of the file format.
This is a table format, a metadata layer that interprets underlying data in the data lake. It defines the schema and partitions of every table and describes the files they contain. So, a table format incorporates columns, rows, data types, and relationships on top of multiple underlying data files.
4. Popular Open Table Formats
A table format does much more than organize data files, abstract their structure, and make data more accessible. It provides transactional support, row-level upserts and deletes, schema evolution, and time travel. Several open-source standard table formats exist today, which are generally referred to as Open Table Formats (OTFs).
Within the big data space, Apache Hive was one of the first table formats to exist. It served well to simplify data usage from the Hadoop Distributed File System (HDFS). However, with increasing scale and complexity, it fell short of expectations. This led to the development of many popular open table formats, such as Apache Hudi, Delta Lake, and Apache Iceberg.
4.1. Apache Hudi
Apache Hudi is a unified data lake platform built around a database kernel. It comprises several software components that form the Hudi Stack. One of the central components in this stack is the table format that sits within the transactional database layer:
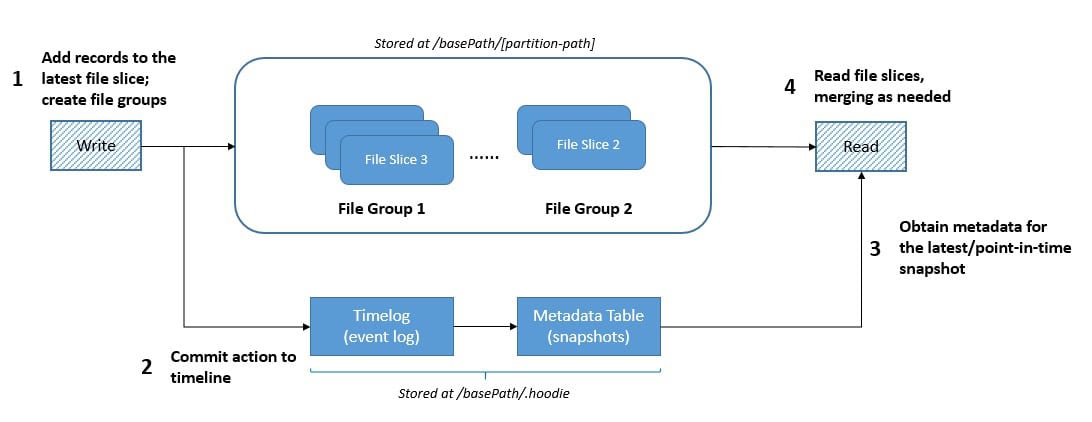
Hudi table format organizes files within a table or partition into File Groups. Then, updates to these File Groups are captured in Log Files tied to them. File Groups comprise the Base and Log files and are split into multiple File Slices.
Further, Hudi’s table format contains Timeline, an event log recording table actions in an ordered manner. It also has a Metadata Table, which efficiently handles quick updates and low write amplification by leveraging the HFile format for quick and indexed key lookups
4.2. Delta Lake
Delta Lake is an open-source project that enables building a lakehouse architecture on top of data lakes.
A Delta table is a transactional table optimized for large-scale data processing. It stores data in a columnar format like Parquet that enables efficient querying and processing:

A Delta log records every operation performed on the Delta table. It provides consistency and durability while supporting features like versioning and rollbacks. Here, the log is a sequence of JSON objects that store log records and checkpoints.
Each log record contains a series of actions to apply to the previous version of the table to generate the next one. Delta Lake compresses the log periodically into the Parquet checkpoint files to achieve better performance. Checkpoints store all nonredundant actions up to a specific log.
4.3. Apache Iceberg
Apache Iceberg is an open table format for huge analytics datasets. Iceberg supports several features that deliver a consistent user experience, like schema evolution, hidden partitioning, partition layout evolution, time travel, and version rollback:
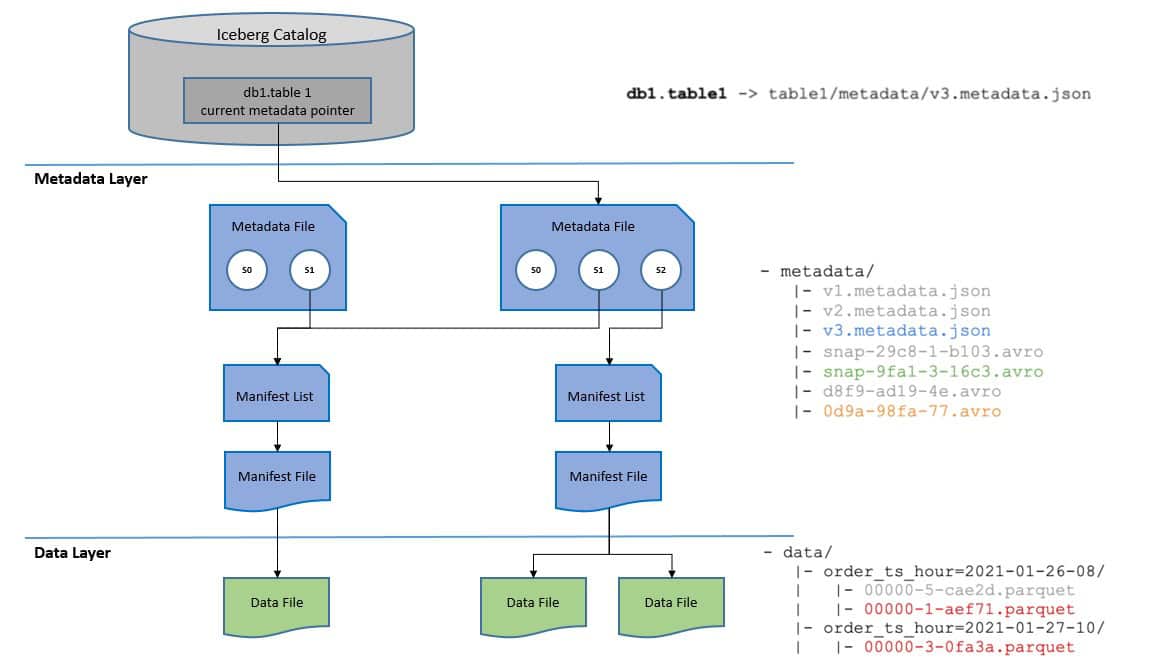
An Iceberg table consists of three layers:
- Catalog layer
- Metadata layer
- Data layer
The catalog stores the current metadata pointer for Iceberg tables. The metadata files store metadata about a table, such as its schema, partition information, and snapshots.
Finally, the manifest list is a list of manifest files. These files track data files and provide additional details and statistics about each file. As a result, Iceberg can track data at the data file level. The manifest files also specify the file format of the data file, like Parquet, Avro, or ORC.
5. A Note on Metadata Catalog
As we’ve seen, a table format like Iceberg is a format for managing data as tables, but it needs a way to keep track of these tables by name. This is where metadata catalogs come into the picture.
A metadata catalog serves as a metastore that tracks tables and their metadata.
A catalog manages a collection of tables that are usually grouped into namespaces. It also serves as the source of truth for a table’s current metadata location. Compute engines can use it to execute catalog operations like creating, dropping, or renaming tables.
Databricks supports this function in its Unity catalog. Iceberg has several out-of-the-box catalog implementations like REST, Hive Metastore, JDBC, and Nessie. Interestingly, the REST catalog decouples the catalog clients from the implementation details of a REST catalog.
There are also many industry-developed catalogs, like Tabular (recently acquired by Databricks) and Polaris (recently open-sourced by Snowflake). Plans are also in place to merge Polaris with Project Nessie, a metadata catalog developed by Dremio for Iceberg.
6. Conclusion
The modern big data architecture largely relies on open standards like open file formats and open table formats. This allows the architecture to decouple storage from compute, shaping the modern data lakehouse architecture.