1. 概述
在本文中,我们将回顾二叉树(Binary Tree)的基本概念,并介绍它在实际开发中的一些常见应用场景。
二叉树是一种每个节点最多有两个子节点的树结构,通常称为左子节点和右子节点。最顶层的节点称为根节点,没有子节点的节点称为叶子节点。实际应用中,常常会使用二叉树的各种变体,比如二叉搜索树、B树、Trie树等。
在计算机科学中,二叉树主要用于搜索和排序,它提供了一种层次化的数据存储方式。常见的操作包括插入、删除和遍历等。
2. 路由表(Routing Tables)
在网络通信中,路由表(Routing Table)用于管理路由器之间的连接路径。它通常使用Trie树实现,这是一种基于二叉树的变体结构。
在这个结构中,路由器的IP地址会被编码为树中的路径。具有相似地址的路由器会被组织在同一子树下。当需要转发一个数据包时,路由器会根据目标地址的前缀去匹配路由表中的最长前缀路径,从而决定下一跳的路由器。
✅ 这种方式提高了查找效率,非常适合处理IP地址这类具有层次结构的数据。
3. 决策树(Decision Trees)
决策树是一种常用的监督学习(Supervised Learning)算法,它本质上是一种二叉树结构,用于模拟决策过程。
- 根节点(Root Node):表示整个数据集的起点。
- 内部节点(Internal Nodes):表示一个判断条件或特征。
- 分支(Branches):表示判断后的不同路径。
- 叶子节点(Leaf Nodes):表示最终的决策结果。
举个例子,我们想对水果进行分类,比如判断是否为苹果。构建的决策树可能如下图所示:
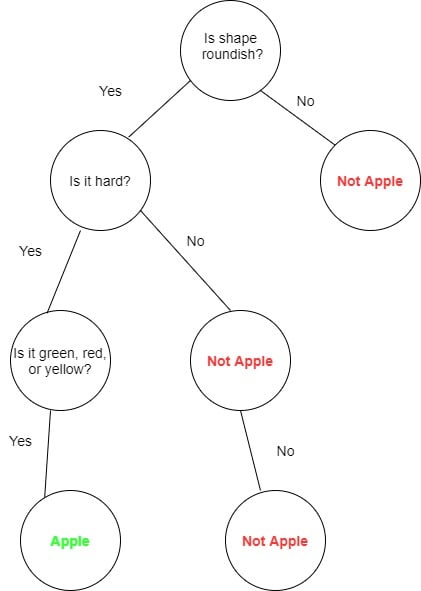
✅ 这种结构非常直观,易于理解和实现,是机器学习中常见的分类工具。
4. 表达式求值(Expression Evaluation)
二叉树也常用于数学表达式求值。在这种结构中:
- 叶子节点存放操作数
- 内部节点存放运算符
表达式通过从下往上递归计算完成。例如表达式 (3 + 5) * 2 的二叉树结构如下:
*
/ \
+ 2
/ \
3 5
计算过程就是从叶子节点向上逐步应用运算符。
✅ 这种方式非常适合处理嵌套表达式,是编译器设计中常见的中间表示形式。
5. 排序(Sorting)
二叉搜索树(Binary Search Tree, BST)是二叉树的一种变体,广泛用于排序算法中。
它的性质是:
- 左子节点的值 < 父节点的值
- 右子节点的值 > 父节点的值
排序过程如下:
- 将待排序数据插入到BST中
- 使用中序遍历(In-order Traversal)遍历树,即可得到有序序列
例如,插入序列 [5, 3, 7, 1, 4] 后,中序遍历结果为 [1, 3, 4, 5, 7]。
✅ 这种方法在平均情况下时间复杂度为 O(n log n),适合中等规模数据排序。
6. 数据库索引(Indices for Databases)
在数据库系统中,B树(B-Tree)是用于实现索引的核心数据结构之一。
虽然B树不是二叉树,但在某些情况下可以退化为二叉树。B树的每个内部节点保存数据的索引信息,而叶子节点保存实际的数据记录或指向数据的指针。
这种结构使得数据的查找、插入、删除等操作都非常高效,并且支持顺序访问。
⚠️ 注意:B树和B+树是现代数据库索引实现的核心,它们相比二叉搜索树更适合磁盘存储场景。
7. 数据压缩(Data Compression)
霍夫曼编码(Huffman Coding)是使用二叉树进行数据压缩的经典算法。
它的基本思想是:
- 根据字符出现的频率构建一棵二叉树
- 高频字符路径短,低频字符路径长
- 通过从根节点到叶子节点的路径生成编码
例如,字符串 "aabbc" 经过霍夫曼编码后,可能会生成如下结构:
(null)
/ \
b a
\
c
编码结果为:
- b: 0
- a: 10
- c: 11
✅ 这样可以显著减少存储空间,是压缩算法如GZIP、JPEG中常用的技术。
8. 总结
本文介绍了二叉树结构在多个领域的实际应用,包括:
| 应用场景 | 使用结构 | 用途说明 |
|---|---|---|
| 路由表 | Trie树 | 实现IP地址前缀匹配 |
| 决策树 | 二叉树 | 模拟分类决策过程 |
| 表达式求值 | 二叉树 | 构建运算结构 |
| 排序 | 二叉搜索树 | 快速排序实现 |
| 数据库索引 | B树/B+树 | 提高查询效率 |
| 数据压缩 | 霍夫曼树 | 减少存储空间 |
二叉树作为一种基础但强大的数据结构,在现代软件系统中扮演着至关重要的角色。掌握其原理和应用场景,对提升系统设计能力非常有帮助。