1. 概述
本文将带你深入了解 Transformer 模型的内部结构,特别是它是如何表示文本的。接着我们还会介绍一个非常流行的衍生模型 BERT,并讲解如何使用它来获取更丰富的文本向量表示。
要理解以下内容,你需要具备一定的深度学习和循环神经网络(RNN)的基础知识。
让我们开始吧!
2. 什么是 Transformer?
Transformer 是一种基于编码器-解码器结构的大规模模型,能够通过一种复杂的注意力机制处理整个序列。
在 Transformer 出现之前,最先进的结构是使用 LSTM 或 GRU 的循环神经网络(RNN)。这些结构存在以下问题:
- 难以处理非常长的序列(尽管使用了 LSTM 和 GRU)
- 训练效率低,因为它们的顺序处理方式无法并行化
而 Transformer 的工作方式完全不同:
- 它可以处理整个序列,从而更好地捕捉长距离依赖关系
- 部分结构可以并行处理,使得训练速度大幅提升
Transformer 最早出现在论文 Attention Is All You Need 中,这个名字来源于它提出的新注意力机制。
3. Transformer 内部结构解析
3.1 整体架构
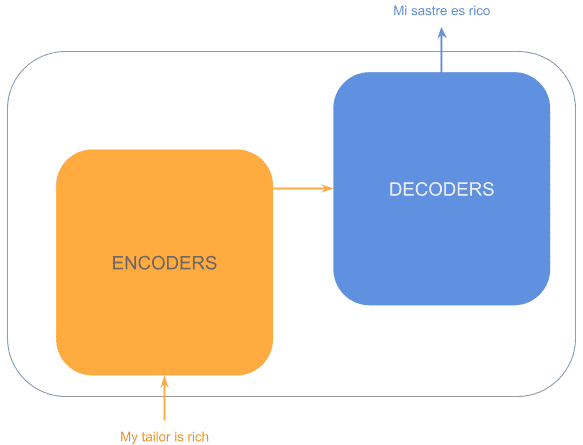
假设我们要将 “My tailor is rich” 从英文翻译成西班牙语。Transformer 的整体结构如下:

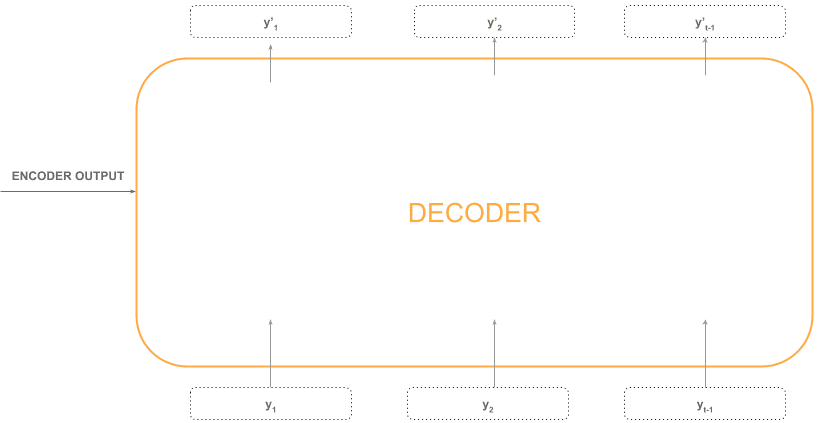
正如你所见,它是一个典型的编码器-解码器结构。输入序列首先经过一个编码器块,生成每个 token 的丰富嵌入,然后这些嵌入被传入解码器块生成输出。
结构可以简化为:
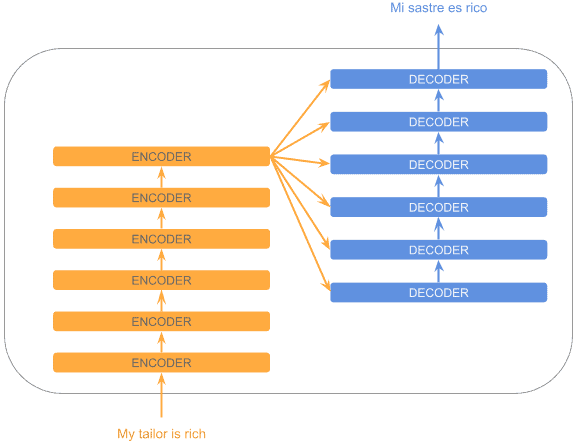
每个编码器/解码器块内部其实是由多个相同的子模块堆叠而成。这样设计的好处是:
- 浅层捕捉更基础的模式
- 深层能识别更复杂的语义关系,类似于卷积网络
如下图所示,最后一个编码器的输出会被所有解码器使用:
3.2 输入处理
编码器不能直接处理原始文本,需要先将文本转换为向量。
处理流程如下:
- 将文本切分为 token,这些 token 来自一个固定的词汇表
- 使用预训练的词向量模型(如 word2vec)将每个 token 转换为向量
由于 Transformer 是一次性处理整个序列,如何表示 token 的位置信息?
解决方案是:在每个 token 的 embedding 上加上位置编码(positional encoding)向量,这样每个 token 的向量就包含了位置信息。
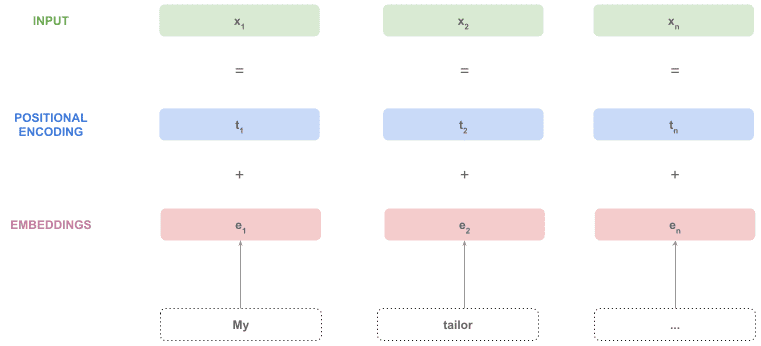
这些向量就可以输入到编码器中了。
3.3 编码器栈
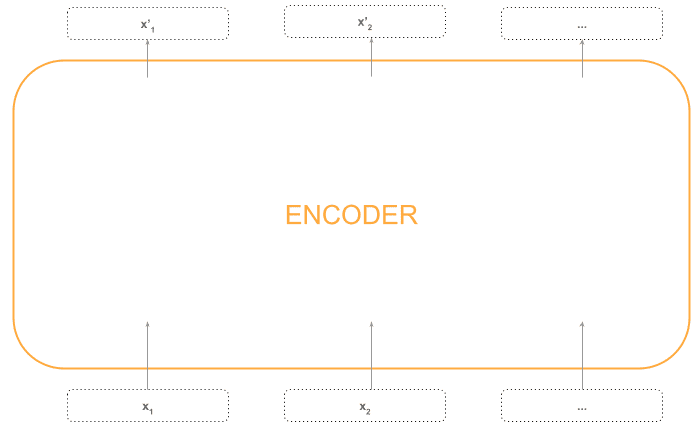
编码器接收一个 token 序列的向量表示:

并返回一个同样长度的输出向量序列:

可以理解为:编码器把每个 token 的输入向量“增强”为包含更丰富信息的输出向量。
简化结构如下图:
接下来我们打开这个黑盒,看看里面到底做了什么。
自注意力机制(Self-Attention)
这是编码器中最核心的部分,能捕捉序列中任意两个 token 之间的关系,无论它们相隔多远。
举个例子:“The cat is on the mat. It ate a lot of food.” 中的 “It” 应该指向 “cat” 而不是 “mat”。注意力机制会在这一步赋予 “cat” 更高的权重。
这部分是顺序处理的,因为注意力机制需要整个序列。
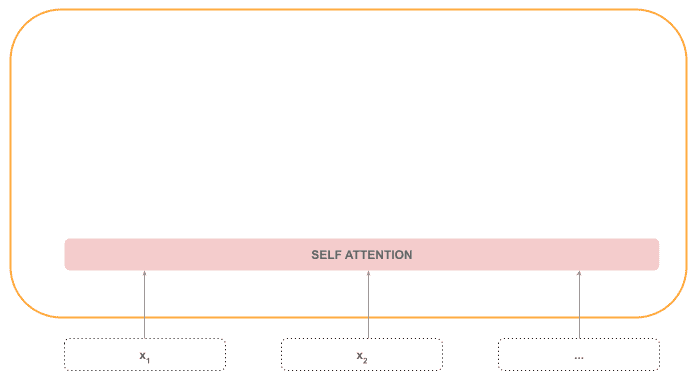
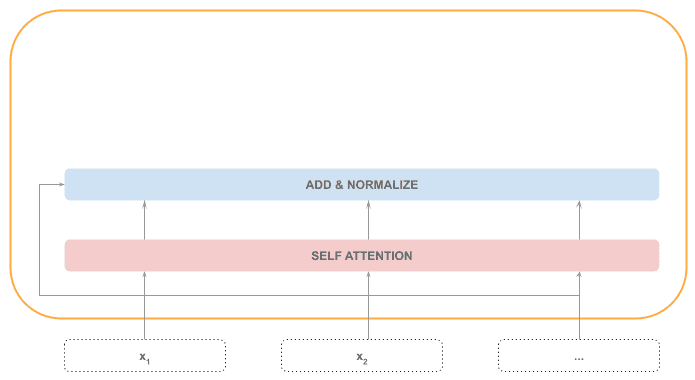
Add & Normalize
将自注意力的输出与输入相加,并做归一化处理。这一步也是顺序处理的,因为归一化需要整个序列的信息。
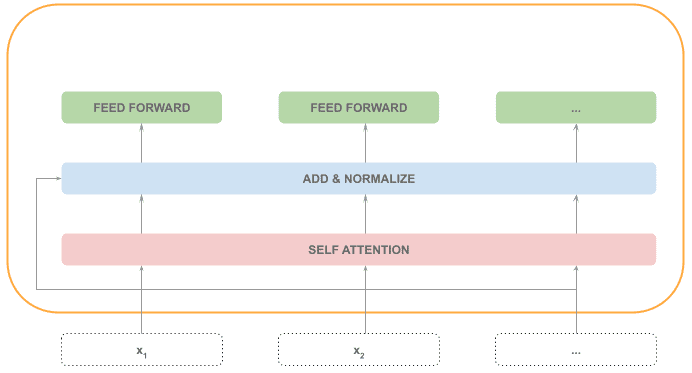
前馈网络(Feed Forward)
每个 token 独立通过一个全连接神经网络,这部分可以并行处理。
再次 Add & Normalize
将前馈网络的输出与输入相加,并再次归一化。
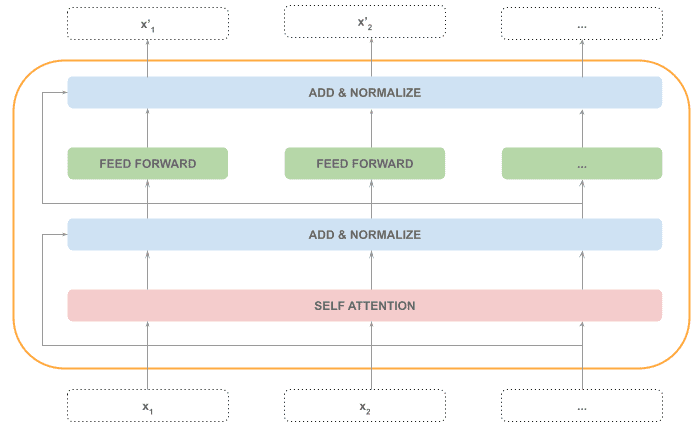
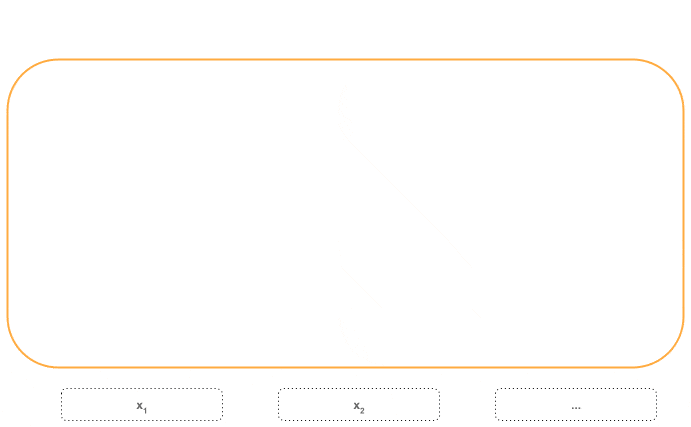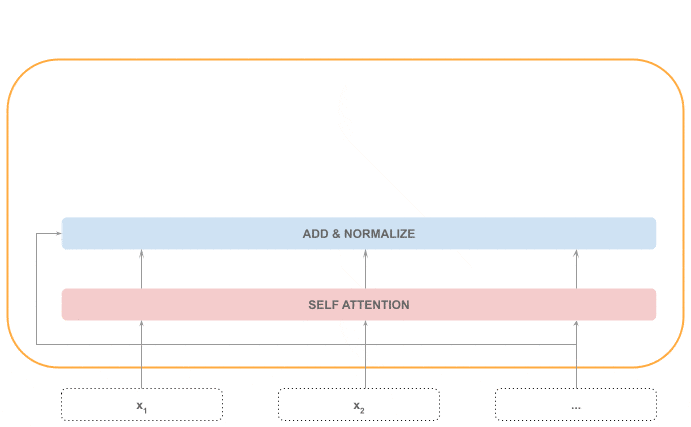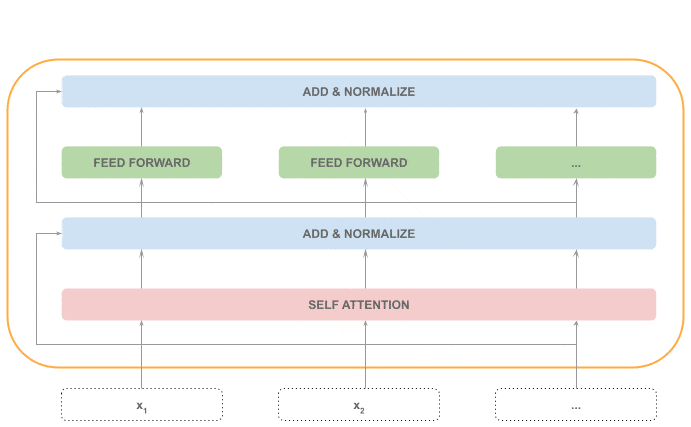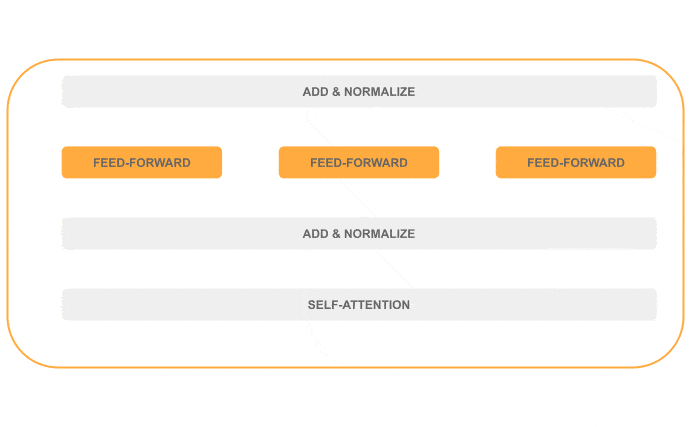
整个编码器内部的顺序处理(灰色)和并行处理(橙色)分布如下:

编码器栈的每一层都会输出一个更新后的 token 序列:
→
最后一层编码器的输出将作为整个编码器栈的输出。
整个过程的动态演示如下:
3.4 解码器栈
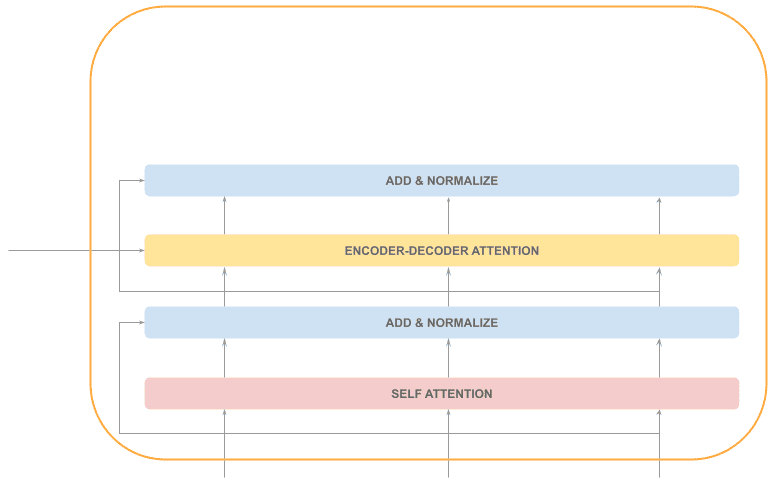
解码器结构与编码器类似,但多了一个编码器-解码器注意力层(Encoder-Decoder Attention)
每个解码器的输入包括:
- 已生成的序列
- 编码器的输出
简化结构如下:
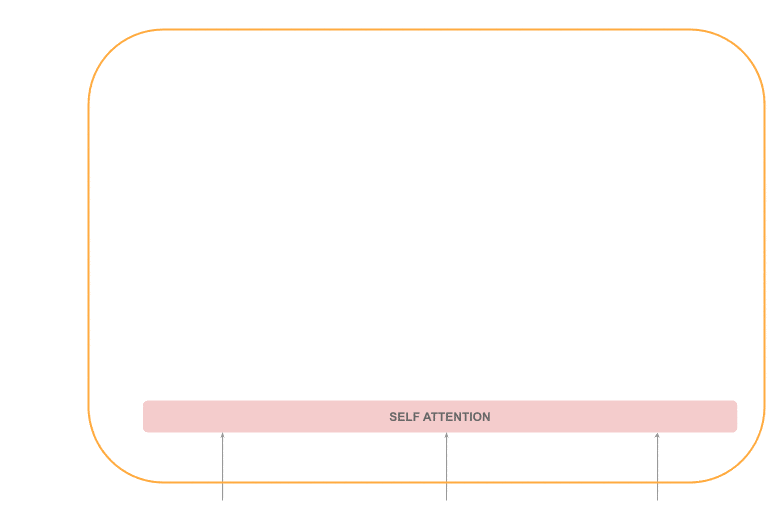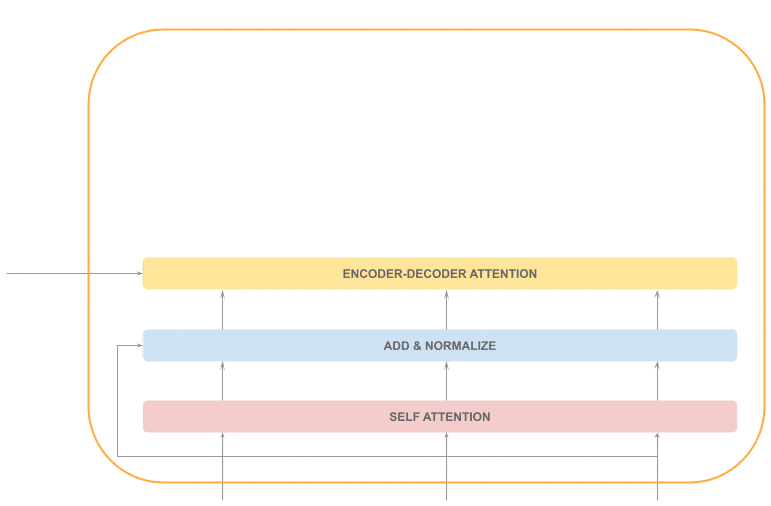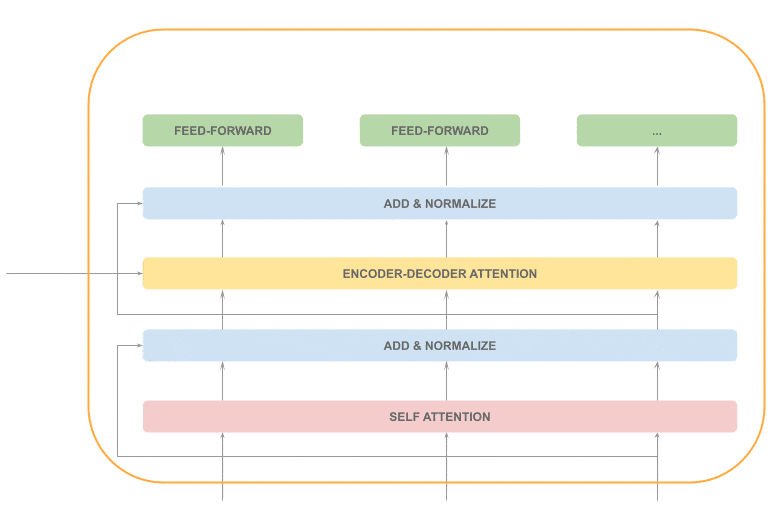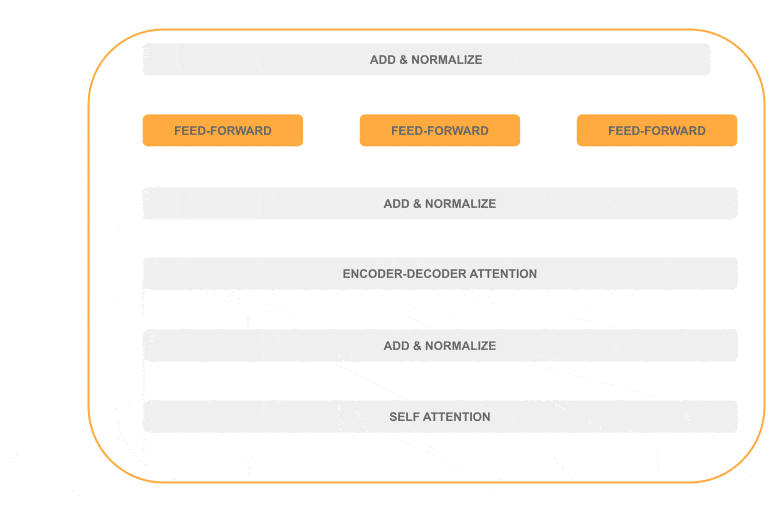
自注意力机制
与编码器的自注意力不同,解码器的自注意力只能看到已生成的部分序列:

这部分是顺序处理的。

Add & Normalize
和编码器一样,这部分也是顺序处理的。
编码器-解码器注意力层
这个注意力机制用于识别当前输出 token 对应的输入序列中哪些 token 更重要。
这部分也是顺序处理的。
前馈网络 + Add & Normalize
这部分可以并行处理。
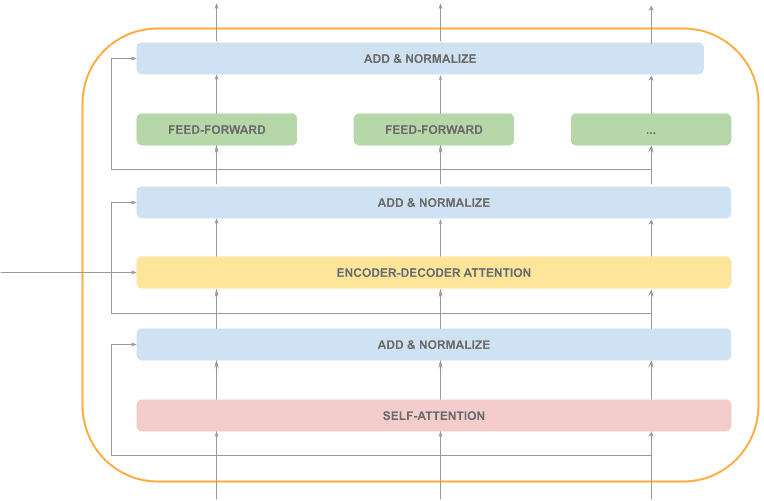
整个解码器的处理流程中,大部分是顺序处理(灰色),仅一层可并行(橙色):

每个解码器的输入是:

输出是:

这个输出会传给下一个解码器。最后一层解码器连接输出层,生成下一个 token。
这个过程会一直持续,直到生成一个特殊的“句尾”标记(EOS)
整个流程的动态演示如下:
3.5 输出处理
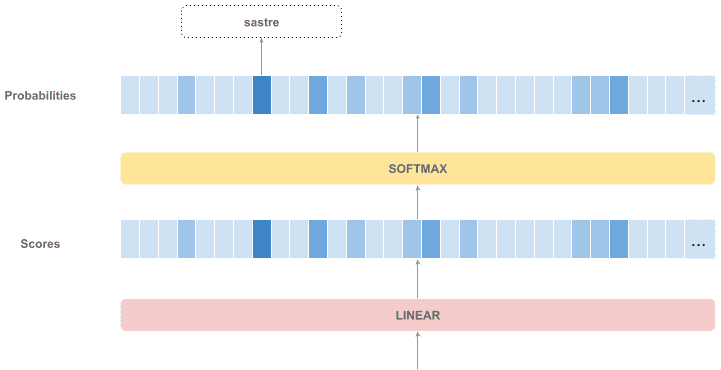
解码器输出的是当前已生成 token 的增强表示,下一步是如何生成下一个 token。
具体流程如下:
- 解码器输出一个 float 向量
- 通过一个全连接层(线性层)将其映射为一个词汇表大小的向量(logits)
- 通过 softmax 转换为概率分布
- 选择概率最高的 token 作为下一个输出
整个流程如下图所示:
4. BERT 简介
4.1 模型介绍
BERT 是一个预训练的 Transformer 编码器栈。
它是 NLP 领域的一项重大突破,因为它只需少量微调即可适应各种具体任务。
类似于图像识别中使用预训练模型(如 ResNet),BERT 通过大规模语料训练已经学习了大量基础语言特征,我们可以在此基础上进行微调,完成各种下游任务。
例如,我们可以在 BERT 的输出上加几层全连接层,构建一个分类器。虽然需要适应不同的词汇、语法等,但基础语义理解已经由 BERT 提供。
4.2 BERT 的运行方式
BERT 的输入需要满足以下条件:
- 使用两个特殊 token:
[CLS]和[SEP] - 输入长度固定(通常为 512)
输入格式如下:
- 开头必须是
[CLS](表示分类) - 结尾必须是
[SEP](表示分隔符)
如果输入序列长度不足,其余位置用 padding 填充,并通过 attention mask 标记有效 token。
如下图所示:
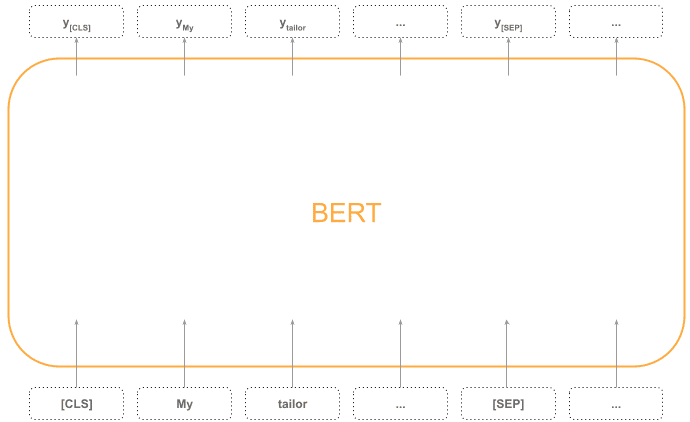
4.3 文本嵌入方式
如果需要获取每个 token 的向量表示,可以直接使用 BERT 编码器输出的对应向量(图中的 “y” 向量)。
如果需要整个句子的向量表示,有三种常用策略:
✅ 使用 [CLS] 的输出向量(最常用)
✅ 对所有 token 向量做平均池化(mean pooling)
✅ 对所有 token 向量做最大池化(max pooling)
一些论文指出 后两种方式在某些任务中效果更好,但默认推荐使用 [CLS] 向量。
5. 总结
本文我们学习了:
- Transformer 的基本结构及其优势
- 自注意力机制如何提升模型对长距离依赖的捕捉能力
- BERT 的基本原理及其作为预训练模型的优势
- 如何使用 BERT 获取文本的嵌入向量
Transformer 的出现彻底改变了 NLP 领域,BERT 等模型的广泛应用也证明了其强大的表达能力。掌握其原理,有助于我们更好地进行模型调优和应用开发。