1. 概述
现实世界中,许多事件的发生往往由一个或多个原因驱动。人类天生好奇,当我们观察到某个结果时,常常希望反推背后的成因。为了实现这一目标,我们需要一种能够建模事件之间因果关系的工具。
贝叶斯网络(Bayesian Networks, BNs)正是这样一种建模和预测工具。它属于概率图模型(Probabilistic Graphical Models)的一种,通过图结构表示变量间的依赖关系,并结合概率理论进行推理。例如,朴素贝叶斯分类器(Naive Bayes Classifier)就是贝叶斯网络的一个简单实例。
本文将介绍贝叶斯网络的基本概念、结构特性、推理方法以及参数学习策略。
2. 背景与动机
假设我们有 n 个事件,每个事件有 m 个可能取值。最直观的建模方式是构建一个包含所有事件组合的联合概率表。但这种做法存在两个致命问题:
- 组合爆炸:n 个变量,每个 m 个取值,总共有 mⁿ 种组合。当 n 较大时,表格规模将变得不可控。
- 推理困难:即使构建出表格,从中提取变量间的关系、进行预测或推理也极其困难。
✅ 贝叶斯网络的价值:
它提供了一种紧凑的建模方式,通过有向无环图(DAG)结构表达变量之间的依赖关系,并利用概率法则(尤其是贝叶斯定理)进行高效推理。
3. 示例说明
我们以一个简单的安防系统为例,包含三个事件:
- 地震(Earthquake,e)
- 入室盗窃(Burglary,b)
- 报警器响(Alarm,a)
我们假设:
- 地震和盗窃是独立事件,各自发生概率为 ε
- 报警器响取决于地震或盗窃是否发生
3.1 联合概率表
| b | e | a | p(a|b,e) | |---|---|---|-----------| | 0 | 0 | 0 | 1 | | 0 | 0 | 1 | 0 | | 0 | 1 | 0 | 0 | | 0 | 1 | 1 | 1 | | 1 | 0 | 0 | 0 | | 1 | 0 | 1 | 1 | | 1 | 1 | 0 | 0 | | 1 | 1 | 1 | 1 |
基于这个表,我们可以回答诸如:
- 如果听到报警器响,发生盗窃的概率是多少?
- 盗窃的边缘概率是多少?
3.2 贝叶斯网络建模
我们可以用如下贝叶斯网络图来表示这三个事件之间的关系:
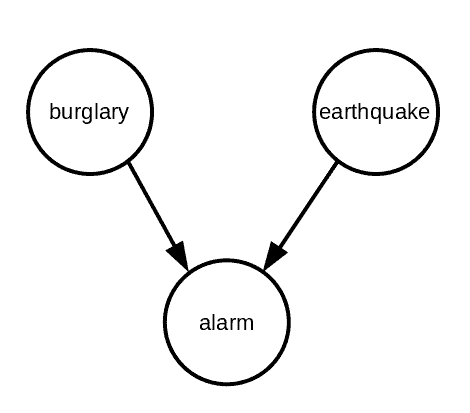
图中节点代表事件,边表示依赖关系。可以看到,报警器响(a)依赖于地震(e)和盗窃(b),因此从这两个节点分别指向报警器。
4. 贝叶斯网络定义与特性
4.1 定义
贝叶斯网络是一种概率图模型,由以下要素构成:
- 一个有向无环图(DAG):节点表示随机变量,边表示变量间的依赖关系
- 每个节点都有一个局部条件概率分布(Local Conditional Distribution)
整个网络的联合分布为所有局部条件分布的乘积:
$$ P(X_1, X_2, ..., X_n) = \prod_{i=1}^n p(x_i|x_{\text{parents}(i)}) $$
4.2 子网络一致性
BN 的一个重要特性是:如果一个节点的所有父节点都已知,那么该节点的分布是确定的。数学上表示为:
$$ \sum_{X_i} p(X_i | X_{\text{parents}(i)}) = 1 \quad \text{对每个} X_{\text{parents}(i)} $$
这意味着 BN 的子网络也是 BN,具有相同的性质。例如在上例中,如果我们对报警器事件求边缘分布:
$$ p(b, e) = \sum_a p(b, e, a) = \sum_a p(b)p(e)p(a|b, e) = p(b)p(e) $$
说明 burglary 和 earthquake 在没有报警器信息时是独立的。
4.3 解释抵消(Explaining Away)
BN 中一个有趣的特性是解释抵消(Explaining Away)现象。
仍以上例为例,地震和盗窃都可能导致报警器响。在不知道报警器状态时,地震和盗窃是独立的。但一旦我们知道报警器响了,知道其中一个事件(如地震)就会影响我们对另一个事件(盗窃)的判断。
示例计算:
设 ε = 0.05,则:
p(b) = p(e) = 0.05
报警器响的概率为: $$ p(a) = \epsilon (1 - \epsilon) + \epsilon (1 - \epsilon) + \epsilon^2 = \epsilon(2 - \epsilon) = 0.05 \times 1.95 = 0.0975 $$
已知报警器响的情况下,盗窃的概率为: $$ p(b|a) = \frac{p(b)p(a|b)}{p(a)} = \frac{0.05 \times 1}{0.0975} \approx 0.51 $$
但如果同时知道地震发生了:
- p(b|a, e) = ε = 0.05
✅ 结论:一旦知道一个原因(地震),另一个原因(盗窃)的可能性就会下降。
4.4 马尔可夫毯(Markov Blanket)
对于一个节点,其马尔可夫毯包括:
- 父节点
- 子节点
- 子节点的父节点
马尔可夫毯将该节点与网络其余部分隔开,使得在已知马尔可夫毯的条件下,该节点与网络其余节点独立。
例如下图中,D 的马尔可夫毯为 {A, B, G, H, E}:

5. 贝叶斯网络中的推理算法
推理是指在给定部分观测值的前提下,对其他变量进行概率推断。常用的推理算法包括:
5.1 前向-后向算法(Forward-Backward Algorithm)
适用于隐马尔可夫模型(HMM)等序列建模场景。通过动态规划计算路径权重,进而推断隐藏状态。
前向权重: $$ F_i(h_i) = \sum_{h_{i-1}} F_{i-1}(h_{i-1})w(h_{i-1}, h_i) $$
后向权重: $$ B_i(h_i) = \sum_{h_{i+1}} B_{i+1}(h_{i+1})w(h_i, h_{i+1}) $$
路径权重: $$ S_i(h_i) = F_i(h_i) \cdot B_i(h_i) $$
5.2 粒子滤波(Particle Filtering)
用于近似推理,尤其适用于状态空间较大的情况。它包含三个步骤:
- 提出(Propose):根据转移概率扩展当前粒子
- 加权(Weight):根据观测值计算粒子权重
- 重采样(Resample):按权重概率进行采样,保留高概率粒子
✅ 优势:相比贪心的 Beam Search,粒子滤波更鲁棒,避免陷入局部最优。
5.3 吉布斯采样(Gibbs Sampling)
一种蒙特卡洛方法,用于从复杂联合分布中采样。其基本思想是:
- 对所有变量赋初始值
- 依次更新每个变量,保持其余变量不变
- 更新时选择使联合概率最大的值
- 重复直到收敛
Java 示例代码如下:
algorithm GibbsSampling(BayesianNet):
x <- a random complete assignment
for i <- 1 to n:
for each v:
Compute the weight of x + {X_i : v}
Choose x + {X_i : v} with the probability proportional to weights
return x
6. 贝叶斯网络中的参数学习
要进行推理,必须知道每个节点的条件概率分布。这些分布即为网络的参数,通常需要通过训练数据学习。
6.1 有监督学习
通过统计训练数据中各事件发生的频率,归一化后得到概率分布。
Java 示例代码如下:
algorithm SupervisedLearning(D_train):
// Count
for x in D_train:
for each x_i:
Increment count_d(x_Parents(i), x_i)
// Normalize
for each d and local assignment x_Parents(i):
p_d(x_i | x_Parents(i)) <- proportional to count_d(x_Parents(i), x_i)
return p_d
这相当于最大似然估计(MLE)。
6.2 拉普拉斯平滑(Laplace Smoothing)
为了避免某些事件在训练数据中未出现而导致概率为零,可以给所有可能的组合加上一个先验计数(λ),通常设为 1。
✅ 作用:防止过拟合,提升泛化能力。
6.3 使用 EM 算法的无监督学习
当数据中存在缺失值时,可以使用 EM 算法进行参数学习:
- E 步:使用推理算法估计缺失值
- M 步:使用最大似然估计更新参数(可结合拉普拉斯平滑)
EM 算法通常收敛到局部最优。为提高全局最优的可能性,可多次随机初始化运行。
7. 总结
本文系统介绍了贝叶斯网络的基本概念、结构特性、推理方法与参数学习策略:
- BN 提供了一种紧凑、概率化的建模方式,适用于因果推理
- 通过 DAG 表达变量依赖关系,结合概率法则进行推理
- 推理方法包括精确算法(如前向-后向)与近似算法(如粒子滤波、吉布斯采样)
- 参数学习包括有监督学习、拉普拉斯平滑与 EM 算法
贝叶斯网络在不确定性建模、诊断推理、决策支持系统等领域具有广泛应用,是现代 AI 中不可或缺的工具之一。