1. 简介
在机器学习中,Accuracy(准确率)和AUC(曲线下面积)是两个常用的模型评估指标。它们都用于衡量分类模型的性能,但各有优劣,适用场景也不同。
本文将从以下几个方面进行讲解:
- Accuracy 的定义与特点
- AUC 的定义、ROC 曲线与计算方式
- Accuracy 与 AUC 的对比分析
- 实际场景中如何选择使用哪一个指标
2. Accuracy(准确率)
Accuracy 是分类模型中最直观、最常用的评估指标之一。
其计算公式如下:
$$ accuracy = \frac{正确预测的样本数}{总样本数} $$
✅ 优点:
- 简单直观,容易理解和实现
- 对于类别分布均衡的数据集表现良好
❌ 缺点:
- 无法反映模型预测的概率置信度
- 在类别不平衡时容易产生误导
举个例子:假设我们训练一个垃圾邮件分类器,数据集中 99% 是正常邮件,1% 是垃圾邮件。如果模型总是预测为“正常邮件”,那么它的 Accuracy 会高达 99%,但实际上这个模型没有任何实际意义。
所以,Accuracy 更适合类别分布均衡、且不关心预测概率置信度的场景。
3. AUC(Area Under the Curve)
AUC 全称是 Area Under the ROC Curve,即“ROC 曲线下面积”。
3.1. ROC 曲线与 TPR/FPR
ROC 曲线是以 FPR(False Positive Rate) 为横轴,TPR(True Positive Rate) 为纵轴绘制的曲线。
定义如下:
$$ TPR = \frac{TP}{P} \quad,\quad FPR = \frac{FP}{N} $$
其中:
- TP:真正例(预测为正,实际为正)
- FP:假正例(预测为正,实际为负)
- P:所有正样本
- N:所有负样本
ROC 曲线通过改变分类阈值(例如 0.2、0.5、0.8),计算不同阈值下的 TPR 和 FPR,并绘制出曲线。
3.2. AUC 的含义与取值范围
AUC 值代表的是 ROC 曲线下面积,取值范围为 [0, 1]:
- AUC = 1:完美分类器
- AUC = 0.5:随机猜测(无区分能力)
- AUC < 0.5:比随机还差,模型预测方向可能相反
✅ AUC 的优势:
- 利用预测概率,能更全面地反映模型性能
- 不受分类阈值影响,具有更强的稳定性
- 在类别不平衡时仍能提供合理评估
3.3. AUC 示例图解
下图展示了一个 AUC 为 0.5 的 ROC 曲线,表示模型无区分能力:
下图则展示了一个 AUC 为 0.84 的模型,曲线更接近左上角,说明模型具有较好的区分能力:
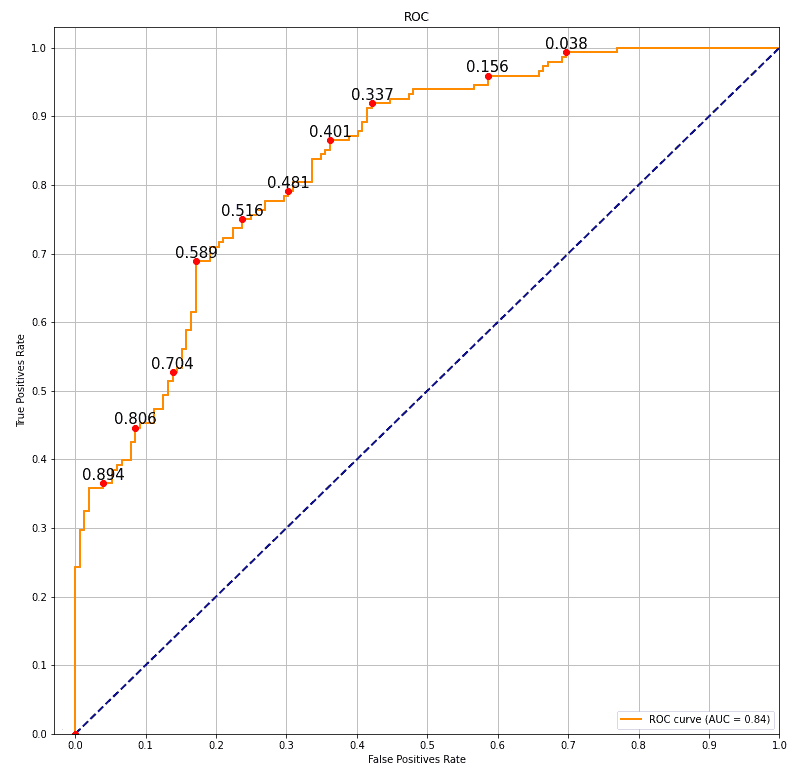
图中红色圆点表示不同阈值下的 TPR 和 FPR,数字表示对应的概率阈值。
4. Accuracy vs AUC 对比分析
4.1. 可解释性与直观性
- ✅ Accuracy 更直观,适合非技术人员理解
- ❌ AUC 更复杂,需要理解 TPR、FPR 和 ROC 曲线,适合技术背景较强的用户
4.2. 类别不平衡问题
- ❌ Accuracy 在类别不平衡时容易失真
- ✅ AUC 能较好应对类别不平衡问题
踩坑提醒:如果你的训练数据中负样本远多于正样本(如 99:1),用 Accuracy 评估模型很容易“看起来很好”,但实际上模型可能毫无用处。
4.3. 模型输出概率的利用
- ❌ Accuracy 只看预测结果是否正确,不关心预测概率
- ✅ AUC 利用预测概率,能更精细地评估模型的置信度和区分能力
举个例子:
两个模型 Accuracy 都是 95%,但一个模型预测正确的样本平均概率是 60%,另一个是 90%。显然后者更值得信赖。
因此,如果你想评估模型预测的“信心”或进行阈值调优,AUC 是更好的选择。
5. 总结
| 对比维度 | Accuracy | AUC |
|---|---|---|
| 是否利用概率 | ❌ 否 | ✅ 是 |
| 是否适合类别不平衡 | ❌ 否 | ✅ 是 |
| 可解释性 | ✅ 高 | ❌ 较低 |
| 是否依赖阈值 | ✅ 是(依赖默认 0.5) | ❌ 否 |
| 适用场景 | 类别均衡、简单任务 | 类别不均衡、需要概率评估的场景 |
✅ 建议:
- 对于类别均衡、结果只需要“是/否”的简单任务,可以使用 Accuracy。
- 如果你关注模型预测的置信度、类别分布不均衡、或者需要调整分类阈值,推荐使用 AUC。