1. 简介
在本教程中,我们将介绍一种常用于处理序列数据的递归神经网络(RNN)——长短期记忆网络(LSTM)。LSTM 是目前应用最广泛的 RNN 之一。
我们会先简要介绍神经网络和循环神经网络的基本概念,然后深入讲解 LSTM 的结构,并重点说明 双向 LSTM(Bidirectional LSTM, BiLSTM) 与 单向 LSTM(Unidirectional LSTM) 的区别。最后,我们会列举两种网络结构的典型应用场景。
2. 神经网络简介
神经网络是受生物神经网络启发设计的一种算法。其核心是神经元之间的互联结构。最初的目标是构建一个类似人脑运作机制的人工系统。
常见的神经网络类型包括:
- 前馈神经网络(Feedforward Neural Networks)
- 卷积神经网络(Convolutional Neural Networks, CNN)
- 循环神经网络(Recurrent Neural Networks, RNN)
它们之间的主要区别在于神经元的连接方式以及信息在网络中的流动方式。
在本教程中,我们主要关注 循环神经网络(RNN),尤其是 LSTM 网络。
3. 循环神经网络(RNN)
不同于前馈神经网络中每个输入分量拥有独立权重,RNN 中的每个输入分量共享相同的权重。这种共享机制使得 RNN 能处理长度不固定的序列数据,并显著减少了模型参数的数量。
RNN 的基本思想是:当前步的输出不仅依赖于当前输入,还依赖于前一步的状态信息。这种机制使得 RNN 能够捕捉序列中的时间依赖关系。
最简单的 RNN 单元可以表示为如下公式:
(1)
$$
\begin{align*}
a^{
其中:
- $ x^{
} $:第 $ t $ 步的输入 - $ a^{
} $:第 $ t $ 步的隐藏状态(hidden state) - $ \hat{y}^{
} $:第 $ t $ 步的输出 - $ W_{aa}, W_{ax}, W_{ya} $:权重矩阵
- $ b_{a}, b_{y} $:偏置向量
- $ f_1, f_2 $:激活函数(如 tanh、ReLU、sigmoid、softmax)
RNN 的基本结构如下图所示:

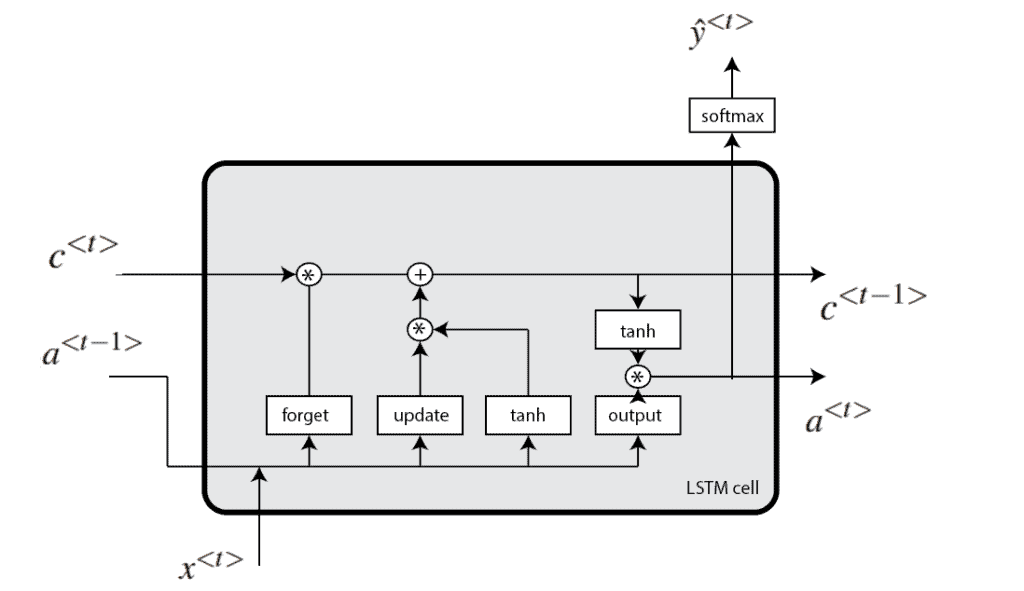
4. LSTM 网络
LSTM(Long Short-Term Memory)是一种特殊的 RNN,设计用于解决 梯度消失/爆炸 问题,并能更好地捕捉序列中的长距离依赖关系。
LSTM 的核心机制是引入了 门控机制(Gates),包括三种门:
- 遗忘门(Forget Gate):决定保留多少上一时刻的记忆
- 输入门(Input Gate):决定当前输入对记忆的影响
- 输出门(Output Gate):决定当前记忆对输出的影响
LSTM 单元的数学表达如下:
(2)
$$
\begin{align*}
\Gamma_{u} &= \sigma(W_{uu}a^{
其中:
- $ \Gamma_{u} $:输入门
- $ \Gamma_{f} $:遗忘门
- $ \Gamma_{o} $:输出门
- $ c^{
} $:记忆单元状态 - $ a^{
} $:隐藏状态 - $ \odot $:Hadamard 积(逐元素相乘)
LSTM 单元的结构如下图所示:
5. 双向 LSTM(Bidirectional LSTM)
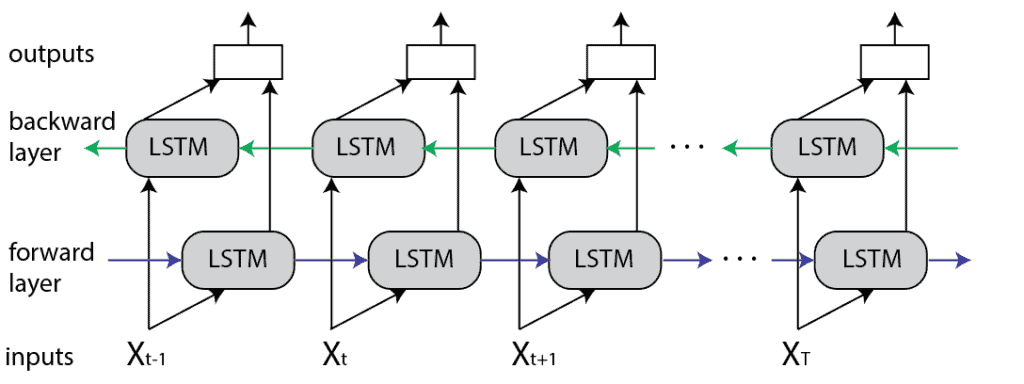
双向 LSTM(BiLSTM)是一种扩展的 LSTM 结构,主要用于自然语言处理(NLP)任务。与单向 LSTM 不同的是,BiLSTM 同时从两个方向处理输入序列:一个方向是正向处理(从前往后),另一个方向是反向处理(从后往前)。
BiLSTM 的核心思想是:当前词的表示不仅依赖于前面的上下文,也依赖于后面的上下文。这种双向信息融合使得 BiLSTM 在理解上下文语义方面更具优势。
具体实现上,BiLSTM 包含两个独立的 LSTM 层:
- 一个按原始顺序处理输入
- 另一个按反向顺序处理输入
最后,将两个方向的输出进行拼接(concatenate)、加权平均、相乘或相加等方式合并。
下图展示了 BiLSTM 的展开结构:
5.1. 优势与应用场景
✅ 优势:
- 能同时利用前后两个方向的上下文信息
- 在 NLP 任务中表现更优,如:
- 句子分类
- 机器翻译
- 实体识别(NER)
- 语音识别
- 手写识别
- 蛋白质结构预测
⚠️ 劣势:
- 模型结构更复杂,训练速度更慢
- 参数更多,需要更强的计算资源和更长的训练时间
5.2. 示例说明
考虑以下两个句子:
Apple is something that competitors simply cannot reproduce.
Apple is something that I like to eat.
在单向 LSTM 中,模型在处理“Apple”时只能看到前面的词,无法判断是指公司还是水果。
而 BiLSTM 则可以结合后面的上下文,从而更准确地理解“Apple”的语义,提升模型效果。
6. 总结
本文介绍了两种常见的 LSTM 网络结构:单向 LSTM 与 双向 LSTM(BiLSTM)。我们从 RNN 基础讲起,逐步深入到 LSTM 的内部机制,并重点分析了 BiLSTM 与单向 LSTM 的区别。
| 对比维度 | 单向 LSTM | 双向 LSTM (BiLSTM) |
|---|---|---|
| 信息流动方向 | 单向(前向) | 双向(前向+后向) |
| 上下文感知能力 | 仅前文 | 前文+后文 |
| 训练速度 | 较快 | 较慢 |
| 参数数量 | 少 | 多 |
| 应用场景 | 简单序列建模 | NLP、语音识别等需上下文感知的场景 |
✅ 建议使用 BiLSTM 的情况:
- 任务需要理解上下文语义(如 NER、机器翻译)
- 数据中后文信息对当前预测有帮助
- 有足够算力支持训练
❌ 不建议使用 BiLSTM 的情况:
- 实时性要求高(如在线语音识别)
- 数据量小,容易过拟合
- 计算资源有限
总之,选择单向还是双向 LSTM,取决于任务需求和资源条件。合理选择可以显著提升模型性能。