1. Introduction
Capsule Networks, introduced by Geoffrey Hinton and his team in 2017, represent a novel approach to building neural networks that can better understand spatial relationships within data. Unlike traditional convolutional neural networks (CNNs), which rely heavily on pooling layers, Capsule Networks aim to preserve more of the structural information within data, such as the position, orientation, and hierarchy of objects or features.
In this tutorial, we’ll explore their architectures, discover how they work and analyze their advantages and drawbacks.
2. From CNNs to Capsule Networks
CNNs are effective in image recognition but struggle with spatial hierarchies and object relationships due to the use of max pooling, which simplifies data and loses important spatial details. This limits their ability to recognize objects from different viewpoints or in complex scenarios, like rotated or partially occluded objects.
Geoffrey Hinton proposed capsule networks, which address these issues by using “capsules,” which capture both the existence and spatial properties of features. Capsules communicate via “dynamic routing,” allowing them to better understand hierarchical relationships. Therefore, Capsule Networks are more robust than CNNs, with great potential in applications requiring complex spatial understanding despite some remaining challenges.
The architecture of CapsNet, which introduces capsule networks:
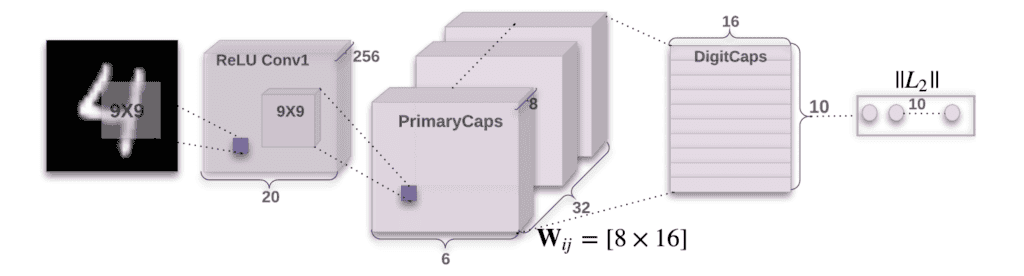
3. Background Concepts
3.1. Limitations of Convolutional Neural Networks (CNNs)
CNNs are powerful for image recognition but struggle with spatial relationships and viewpoints. Their reliance on pooling reduces computational load but also loses crucial spatial details. As a result, CNNs often misinterpret objects or fail when they appear in different orientations. Tasks requiring detailed spatial understanding, like 3D recognition or medical imaging, highlight these CNN limitations:
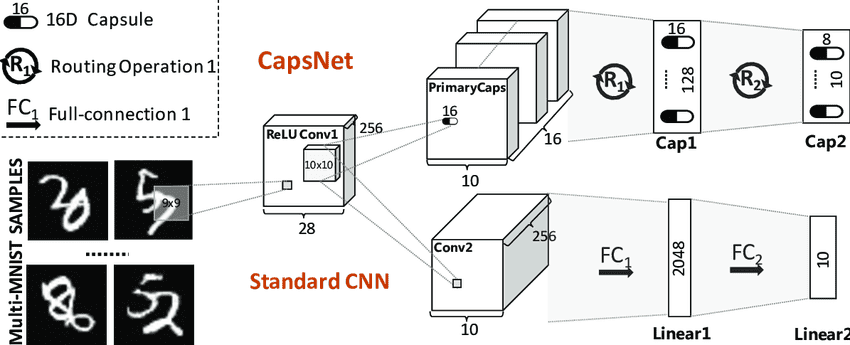
Capsule Networks address these by preserving more spatial information.
3.2. Hierarchical Relationships in Data
Recognizing objects involves understanding how parts relate to each other. For example, the specific arrangement of eyes, mouth, and other features defines a face. CNNs detect individual features but often miss these spatial relationships. Capsule Networks solve this by encoding spatial hierarchies, allowing them to understand how parts fit together and recognize objects from various perspectives.
4. Core Concepts of Capsule Networks
4.1. What Is a Capsule?
A capsule is a small group of neurons within a neural network that captures multiple properties of a feature, such as its presence, position, orientation, and scale. Unlike traditional CNNs, which rely heavily on pooling layers, Capsule Networks, in contrast, aim to preserve more of the structural information within data, such as the position, orientation, and hierarchy of objects or features. This means a capsule can encode not only whether a feature exists but also how it appears within the data.
4.2. The Role of Capsules in Modeling Spatial Hierarchies
Capsules are structured to preserve spatial hierarchies and relationships, which CNNs lose through pooling. When a capsule detects a feature, it communicates information on how this feature relates spatially to other features in the data. For example, a capsule might recognize an eye within an image and pass information about its orientation and position relative to other facial features. This allows Capsule Networks to maintain a consistent understanding of objects, even as their appearance shifts.
4.3. Dynamic Routing
Dynamic routing is the process by which capsules communicate with each other. Instead of connecting to all possible parent capsules equally, each capsule selectively routes its output to higher-level capsules based on how well the higher-level capsules “agree” with its representation.
This process involves ‘routing by agreement,’ where each capsule influences only those capsules that align with its perspective, helping the network build more accurate representations of complex objects.
Capsules typically calculate the agreement using a scalar product.
If we let  represent the input vector from capsule
represent the input vector from capsule  and
and  represent the output vector from capsule
represent the output vector from capsule  , the agreement
, the agreement  between capsules is given by:
between capsules is given by:
(1) 
Where,  is the input vector from capsule ,
is the input vector from capsule ,  is the output vector of capsule , and
is the output vector of capsule , and  and
and  are the norms (magnitudes) of the vectors.
are the norms (magnitudes) of the vectors.
4.4. Squashing Function
Capsule Networks use a squashing function to keep each capsule’s output vector between 0 and 1. This function compresses the length of each vector without altering its direction, making it easier for capsules to express confidence (or lack thereof) about the presence of features. Mathematically, the squashing function is:
(2) 
Where  is the input vector,
is the input vector,  is the squashed output.
is the squashed output.
5. How Does Capsule Network Work?
In Capsule Networks, capsules are organized in layers where lower-level capsules detect simple features (like edges) and higher-level ones combine these to recognize complex objects (like faces).
Each capsule outputs an activation vector, where the length reflects feature presence, and direction encodes spatial attributes, making the network robust to varying perspectives:
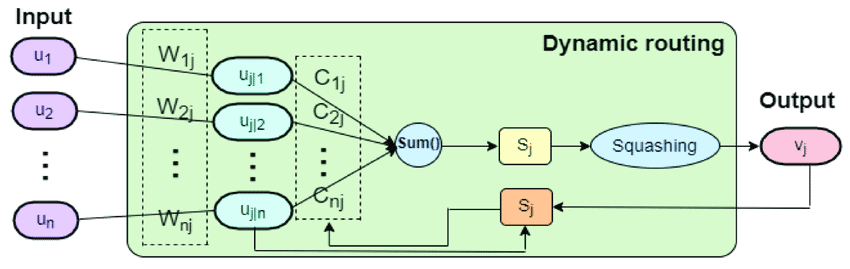
Capsules pass information selectively in a process called “routing by agreement,” connecting to higher-level capsules only if both “agree” on the feature. A squashing function ensures each vector is scaled between 0 and 1, expressing confidence while retaining spatial accuracy.
6. Architectures of Capsule Networks
6.1. Basic Capsule Network Architecture (CapsNet)
The original Capsule Network is called CapsNet. This architecture consists of two main parts: primary capsules and digit capsules. The primary capsules capture simple features and pass them to digit capsules, which detect more complex structures (such as whole objects). The digit capsules represent the network’s final output, each one identifying the presence and spatial properties of specific object classes. This setup enables CapsNet to recognize objects from various viewpoints and in different configurations, making it more robust than traditional CNNs in handling rotation and occlusion.
6.2. Matrix Capsules with EM Routing
After CapsNet, researchers introduced Matrix Capsules with EM Routing. Each capsule is represented as a matrix, not a vector. This allows capsules to store more detailed feature information, such as rotation, translation, and scaling. It also improves the network’s ability to generalize across different object viewpoints. The EM (Expectation-Maximization) routing mechanism in this architecture improves how capsules communicate, further refining the accuracy of object detection.
7. Advantages and Limitations
Capsule Networks offer several key benefits over traditional CNNs. They preserve spatial relationships, making them more robust to changes in object orientation or position. Unlike CNNs, which lose important information through pooling, Capsule Networks retain fine-grained spatial details, enabling better generalization.
Despite their advantages, Capsule Networks face several challenges. They require more computational resources than traditional CNNs, particularly in terms of processing power for dynamic routing. Scaling Capsule Networks to large datasets and complex tasks can be difficult, and training them efficiently remains an area of active research. Additionally, while Capsule Networks handle spatial relationships better, they are still not as widely adopted or understood as CNNs due to the complexity of their architecture:
Advantages
Challenges
Handles Spatial Hierarchies Better than CNN
High Computational Cost
Robustness to Input Transformations
Training Complexity & Scalability Issues
Dynamic Routing
Fewer standardized frameworks and implementations compared to CNNs
Improved Generalization
Lack of Standard Implementations & Limited Adaptation
8. Applications
Capsule Networks are used in tasks requiring complex object recognition, such as 3D image analysis, medical imaging, and autonomous vehicles. Their ability to understand spatial relationships makes them suitable for applications where traditional CNNs struggle, like recognizing objects from various angles or under occlusion. Additionally, they are being explored for tasks in robotics, where understanding spatial hierarchies is critical for object manipulation and navigation.
They also improve object recognition in scenarios with occlusion or variation in viewpoint, as capsules encode both parts and their hierarchical relationships. This makes Capsule Networks especially effective in complex tasks, such as 3D recognition and more precise image classification.
9. Conclusion
In this article, we explored Capsule Networks, analyzed their architecture, layers, and mechanisms, and examined their advantages, drawbacks, and applications.
Capsule Networks represent a promising evolution in neural network architecture, offering better spatial understanding and robustness than CNNs.