1. 概述
鸡尾酒排序(Cocktail Sort),又名鸡尾酒摇床排序(Cocktail Shake Sort)、双向冒泡排序(Bidirectional Bubble Sort),是冒泡排序的一种扩展版本。它与冒泡排序的主要区别在于:排序过程是双向的,即从左到右和从右到左交替进行比较和交换。
虽然鸡尾酒排序与冒泡排序在时间复杂度上并没有本质区别,但它的双向特性在某些特定场景下能略微提升性能,因此在教学中常被提及,实际开发中较少使用。
2. 算法原理
鸡尾酒排序的核心思想是:在每次遍历中,先从左向右进行冒泡排序(将较大的元素逐步向右移动),然后再从右向左进行冒泡排序(将较小的元素逐步向左移动)。这样可以加快排序的收敛速度。
2.1 示例说明
以下图为例,初始数组为 [5, 1, 4, 2]:
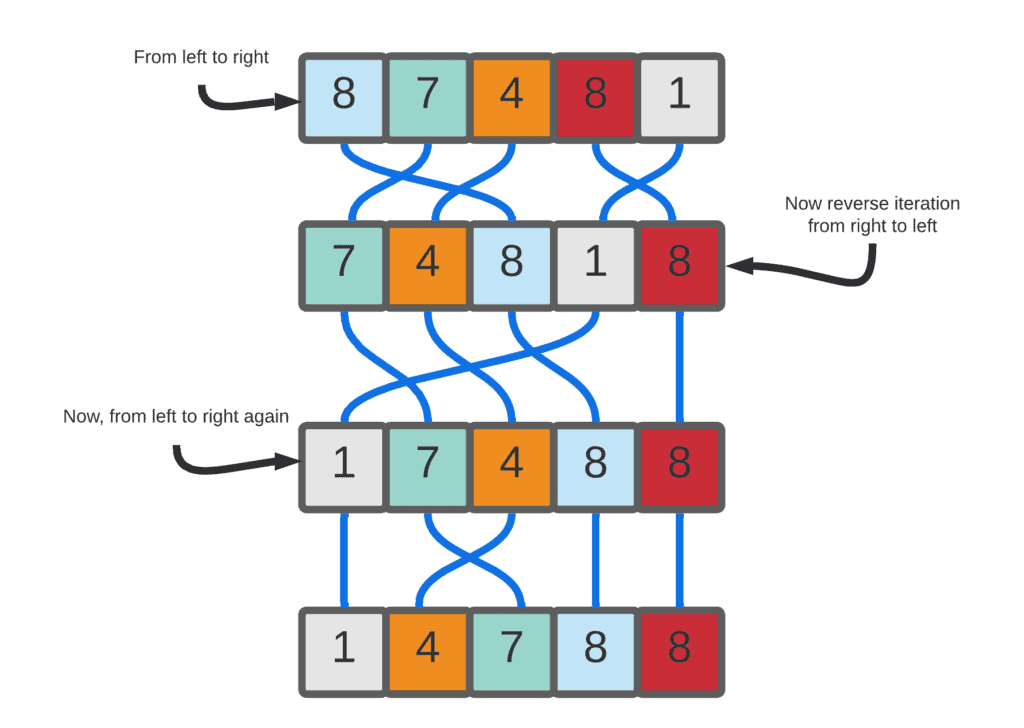
- 第一轮从左到右遍历,比较相邻元素并交换,结果为
[1, 4, 2, 5]。 - 第二轮从右到左遍历,比较相邻元素并交换,结果为
[1, 2, 4, 5]。 - 第三轮再次从左到右遍历,此时没有发生任何交换,说明数组已排序完成。
✅ 小贴士: 这种“来回”遍历的方式就像鸡尾酒调制时的摇晃动作,因此得名“鸡尾酒排序”。
2.2 伪代码实现
algorithm CocktailSort(A):
// INPUT
// A = the array to sort
// OUTPUT
// The array A is sorted
swapped <- true
while swapped:
swapped <- false
for i <- 0 to (length(A) - 2):
if A[i] > A[i + 1]:
swap(A[i], A[i + 1])
swapped <- true
if not swapped:
break
swapped <- false
for i <- (length(A) - 2) to 0:
if A[i] > A[i + 1]:
swap(A[i], A[i + 1])
swapped <- true
上述伪代码中,我们使用 swapped 标志位来判断是否还需要继续遍历。每次遍历分为两个方向:
- 从左到右:将较大元素“冒泡”到右边;
- 从右到左:将较小元素“冒泡”到左边。
只有当某次遍历中没有发生任何交换时,才认为排序完成。
3. 时间与空间复杂度分析
鸡尾酒排序的时间复杂度与冒泡排序相同:
- 最坏情况与平均情况:
O(n^2) - 最佳情况(已接近有序):
O(n) - 特殊情况(元素偏移量较小):
O(kn),其中k是最大偏移量
空间复杂度为 O(1),因为它是原地排序算法,无需额外存储空间。
❌ 注意: 虽然鸡尾酒排序在某些情况下性能略优于冒泡排序,但其复杂度并没有本质提升,因此不适用于大规模数据排序。
4. 与冒泡排序的区别
| 特性 | 冒泡排序 | 鸡尾酒排序 |
|---|---|---|
| 遍历方向 | 单向(从左到右) | 双向(左右交替) |
| 交换方向 | 仅向右 | 向右再向左 |
| 性能提升 | 无 | 略有提升 |
| 时间复杂度 | O(n²) |
O(n²) |
| 是否原地排序 | ✅ | ✅ |
鸡尾酒排序的主要优势在于减少无效遍历次数,尤其在数组中存在“尾部小元素”或“头部大元素”的情况下效果更明显。
5. 总结
鸡尾酒排序是冒泡排序的双向改进版本,通过交替方向进行冒泡操作,可以略微提升排序效率。尽管它在时间复杂度上与冒泡排序相同,但在教学中具有一定的参考价值。
📌 适用场景:
- 小规模数据排序
- 教学演示或算法练习
❌ 不推荐用于:
- 大数据量排序
- 实际生产环境
✅ 优点:
- 实现简单
- 原地排序
- 比冒泡排序略快
⚠️ 踩坑提醒:
- 不要误以为双向遍历能显著提升性能,其复杂度仍为
O(n²)。 - 实际项目中应优先选择
O(n log n)的排序算法,如Merge Sort、Quick Sort或TimSort。