1. 概述
在机器学习领域,数学无处不在:输入输出数据是数学对象,学习和预测的算法也是。但当我们面对语言单位(如“单词”)时,该如何建模为数学表示?答案就是:将它们转换为向量!
本文将介绍将单词向量化的主要技术及其优缺点,帮助我们在实际场景中合理选择使用。
2. One-Hot 向量
2.1. 描述
One-Hot 向量是一种最基础的词向量化方法,每个单词在向量中对应一个唯一的位置,其余位置为 0。
举个例子:
(1) John likes to watch movies. Mary likes movies too.
(2) Mary also likes to watch football games.
构建的词表为:
V = {John, likes, to, watch, movies, Mary, too, also, football, games}
对应的 One-Hot 向量如下图所示:

单词 “likes” 的向量表示为:

而单词 “watch” 的向量表示为:
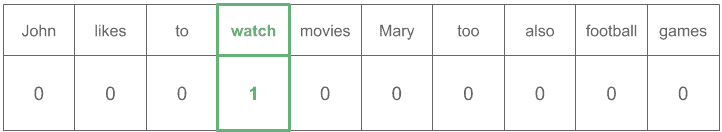
构建词表的方式多种多样,选择合适的策略对系统性能和速度有直接影响。
2.2. 停用词过滤
停用词是指那些对任务无意义的高频词,如 "the"、"in"、"a" 等。
✅ 优点:
- 减少词表大小
- 降低维度
❌ 缺点:
- 有可能丢失语义信息(如在情感分析中,“not”是关键词)
2.3. 词形归一化
常用技术包括 词干提取(Stemming) 和 词形还原(Lemmatization)。
词干提取(Stemming)
- 将词截断为一个“词干”(stem)
- 词干可能不是真实存在的词
例如:

词形还原(Lemmatization)
- 将词还原为字典中的标准形式(lemma)
- lemma 是真实存在的词
例如:

2.4. 小写处理
统一将所有单词转为小写,有助于减少词表大小,但:
⚠️ 如果大小写对任务有语义影响(如地名、人名),应保留原样。
2.5. 处理未知词(OOV)
常见策略:
- 报错并重新构建词表
- 忽略该词(视为停用词)
- 引入特殊标记 “UNK” 表示未知词
2.6. 优缺点
✅ 优点:
- 实现简单
- 计算快
- 分布式计算友好
- 可解释性强
❌ 缺点:
- 向量维度极高且稀疏
- 无法表达语义相似性
3. 词嵌入(Word Embeddings)
3.1. 描述
词嵌入是实数向量表示单词,通常能捕捉上下文、语义相似性和与其他词的关系。
3.2. 词向量的算术性质
词嵌入的一大亮点是可以进行语义运算。例如:
king - man + woman ≈ queen
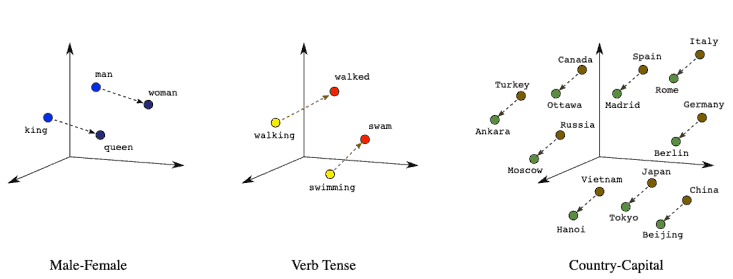
语义差值(如性别、职业)在向量空间中具有可解释性。
例如,“king” 与 “man” 的差值 ≈ “queen” 与 “woman” 的差值:
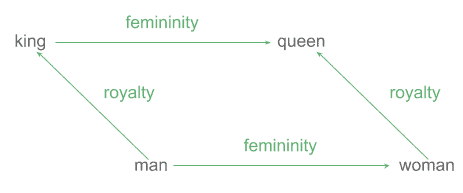
甚至可以通过向量运算近似得到:
v(queen) - v(woman) + v(man) ≈ v(king)

✅ 这种语义与几何的结合,使词嵌入在机器学习中特别有用。
3.3. 优缺点
✅ 优点:
- 能捕捉语义与句法关系
- 支持词义相似度计算
- 支持向量运算
❌ 缺点:
- 需要大量训练数据
- 计算较慢
- 可解释性差
4. Word2vec
Word2vec 是最流行的词嵌入生成技术之一。
核心思想来自语言学中的 分布假设:“在相同上下文中出现的词具有相似含义。”
Word2vec 包含两种模型:
- CBOW(Continuous Bag of Words):根据上下文预测目标词
- Skip-Gram:根据目标词预测上下文词
模型结构是一个三层浅层神经网络:输入层(One-Hot)、隐藏层(N 维)、输出层(One-Hot)
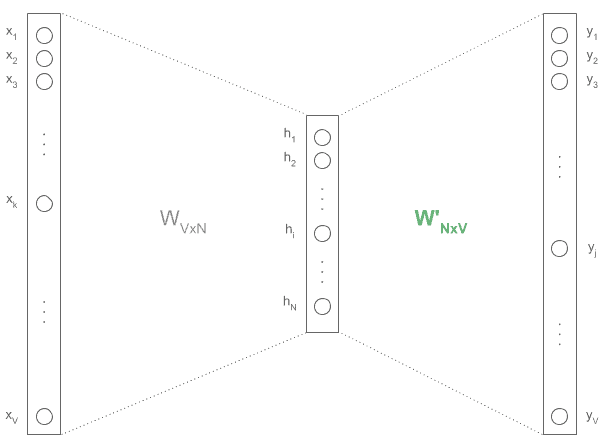
训练过程中,隐藏层权重矩阵(红色)即为词嵌入。
4.1. CBOW 架构
输入为上下文词(One-Hot),输出为目标词。
例如:
John _____ to → 预测 "likes"
likes _____ watch → 预测 "to"
...
训练示例:
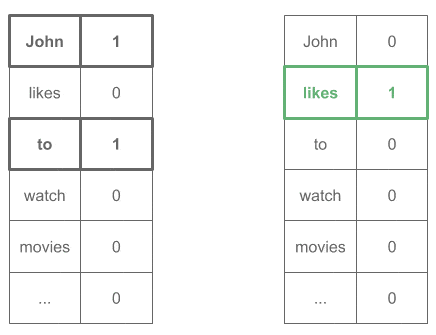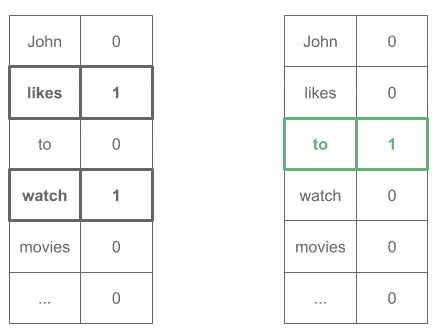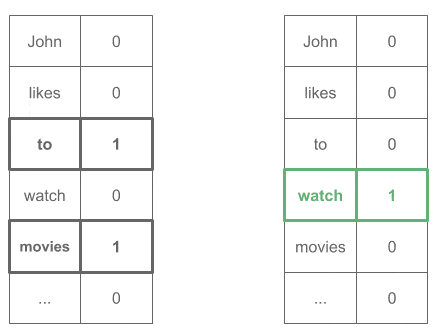
4.2. Skip-Gram 架构
输入为目标词,输出为上下文词。
例如:
"likes" → ["John", "to"]
"to" → ["likes", "watch"]
"watch" → ["to", "movies"]
...
One-Hot 输入输出示意图:
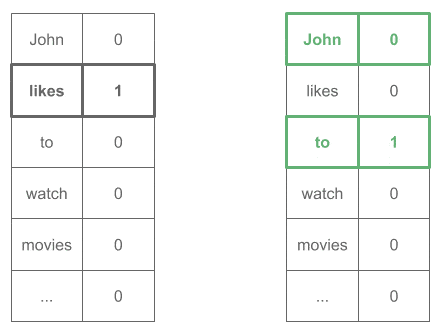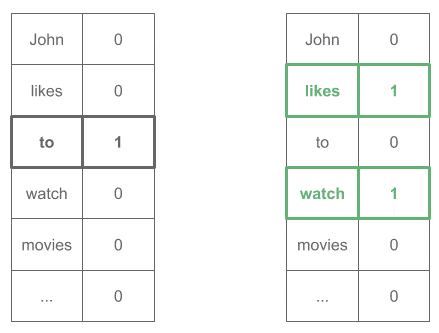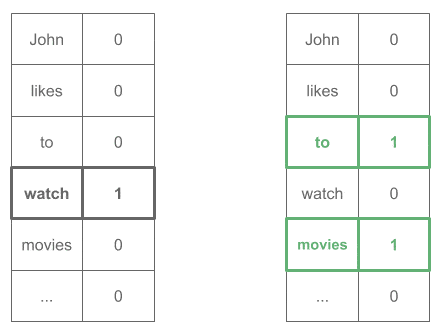
4.3. 实践建议
- 下采样:高频词可适当采样以加速训练
- 维度选择:100~1000 之间,常见 100、200、300
- 上下文窗口:Skip-Gram 推荐 10,CBOW 推荐 5
- 定制领域词嵌入:预训练词向量不一定适合特定领域,训练定制词嵌入可提升性能
5. 其他词嵌入方法
5.1. GloVe
由斯坦福提出,基于词共现概率训练词向量。
✅ 优点:
- 训练速度快于 Word2vec
- 在语义相关性任务中表现更好
❌ 缺点:
- 内存占用大,大规模语料处理吃力
5.2. FastText
FastText 是 Word2vec 的扩展,使用字符 n-gram 而非完整单词。
✅ 优点:
- 小数据集上也能训练
- 更好地处理短词和词缀
- 对未知词泛化能力强
❌ 缺点:
- 速度比 Word2vec 慢
- 内存需求大
- n 值选择敏感
5.3. ELMo
ELMo(Embeddings from Language Models)解决一词多义问题。
例如,“cell”在不同语境中含义不同:
- He went to the prison cell with his phone.
- He went to extract blood cell samples.
✅ 优点:
- 考虑词序和上下文
- 语义更准确
❌ 缺点:
- 使用时需加载模型,部署成本高
5.4. 其他方法
- BERT:双向 Transformer 模型,支持上下文感知
- PCA:用于降维
- t-SNE:用于可视化高维词向量
- Gensim:Python 库,支持多种词向量训练
6. 总结
本文介绍了将单词向量化的两种主要方法:
- One-Hot 向量:简单但稀疏,适合小规模任务
- 词嵌入(Word Embeddings):语义丰富,适合深度学习任务
并对比了不同技术的优缺点,包括 Word2vec、GloVe、FastText、ELMo 等。
在实际应用中,应根据任务需求、数据规模、语义复杂度等选择合适的词向量化方法。