1. 简介
本文将介绍强化学习的基础知识以及如何在其中结合使用神经网络。我们将通过一个简单的示例应用,逐步讲解核心概念,帮助理解强化学习的基本流程与实现方式。
2. 基础概念
2.1. 机器学习与强化学习
机器学习是一类能够通过经验自动改进的算法集合,是人工智能的一个重要分支。根据反馈机制,我们可以将机器学习大致分为三类:
- 监督学习(Supervised Learning):通过带有标签的数据集学习输入到输出的映射关系。
- 无监督学习(Unsupervised Learning):通过探索数据中未被发现的模式,不依赖标签。
- 强化学习(Reinforcement Learning):智能体在环境中通过采取行动以最大化累积奖励,平衡探索与利用。
2.2. 神经网络与深度学习
神经网络是一种受人类大脑结构启发的计算模型,由多个相互连接的节点组成,通常以层的形式组织。通过前向传播和反向传播,网络学习连接权重。
当神经网络的层数和节点数增加到一定程度时,我们称之为深度学习(Deep Learning)。将深度学习应用于强化学习时,通常称为深度强化学习(Deep Reinforcement Learning)。
3. 强化学习基础
强化学习的核心思想是:智能体通过在环境中采取行动,不断学习以最大化长期累积奖励。
3.1. 示例:训练宠物
我们可以把宠物看作一个智能体,在客厅中训练它取回球。环境的状态是球被扔出的位置,动作是宠物跑过去取回,奖励可以是抚摸,惩罚可以是忽略。
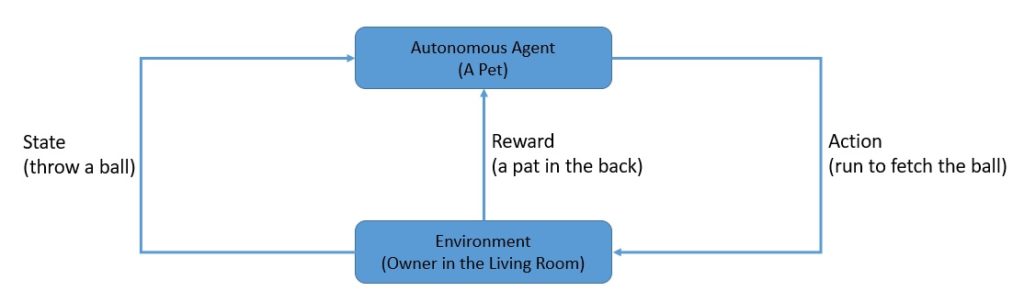
这种奖励可以是即时的,也可以延迟,但通常未来的奖励会打折扣。
3.2. 环境类型
- 确定性环境(Deterministic):相同的动作在相同状态下总是导致相同的结果。
- 随机性环境(Stochastic):状态转移和奖励具有随机性,重复动作可能导致不同结果。
3.3. 强化学习类型
- 基于模型(Model-Based):智能体构建环境的内部模型(状态转移与奖励函数),并据此选择动作。
- 无模型(Model-Free):智能体直接学习策略或价值函数,不依赖环境模型。
3.4. 价值函数与策略
强化学习的目标是最大化累积奖励,我们称之为价值(Value)。智能体遵循的策略称为策略(Policy),最优策略是能最大化价值的策略。
价值函数形式如下:

右侧是著名的贝尔曼方程(Bellman Equation),用于描述动态规划中的最优条件。
3.5. Q值与Q学习
Q值表示在某个状态下采取某个动作的长期回报。Q学习是一种无模型强化学习方法,其核心是评估动作的价值。
Q值函数如下:

4. Q学习实现
我们以 OpenAI 的 Gym 库中的 FrozenLake 环境为例,演示 Q学习的实现。
4.1. 测试环境:FrozenLake
FrozenLake 是一个 4x4 的网格世界,包含起点(S)、终点(G)、安全格子(F)和危险格子(H)。目标是让智能体从起点走到终点,避开危险格子。
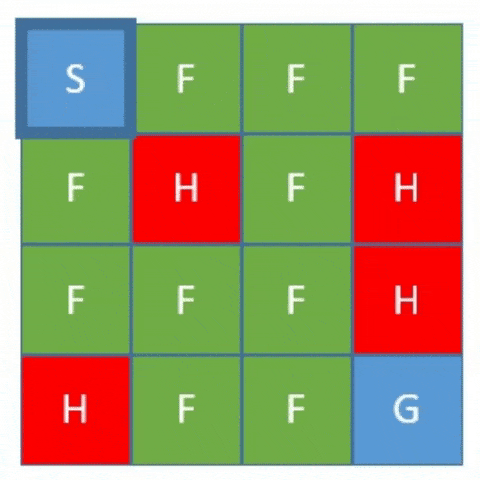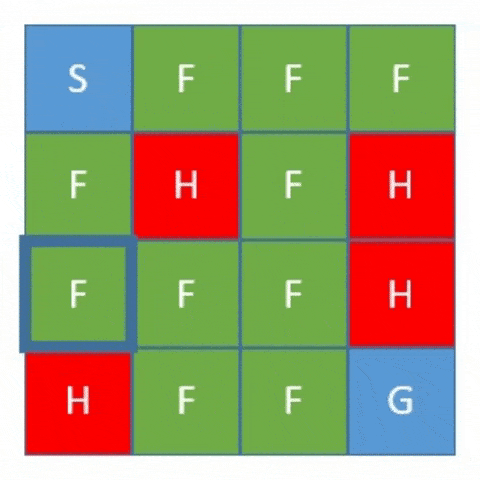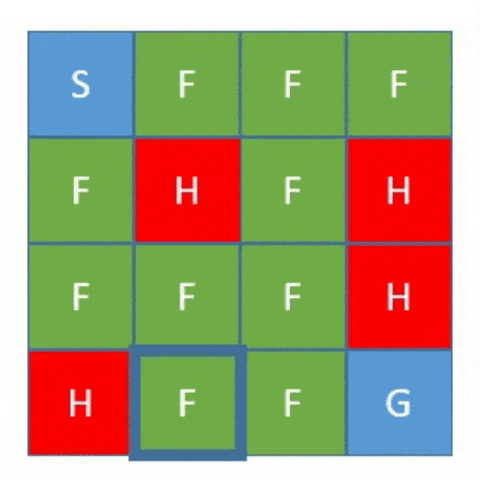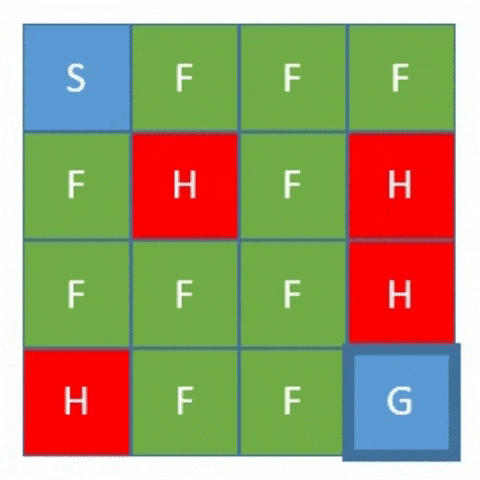
4.3. Q学习流程
Q值存储在一个 Q表(Q-table)中,其维度与环境中状态和动作的数量一致。初始时,Q表为全零。
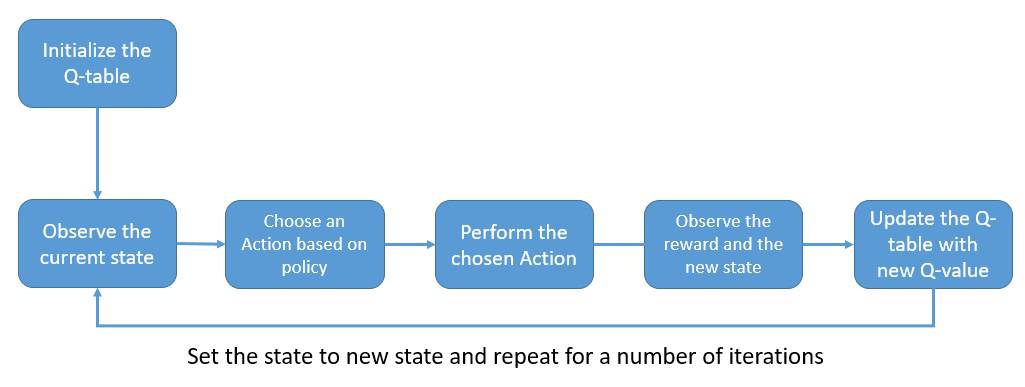
流程如下:
- 根据 Q表选择动作(初期随机,后期基于最大 Q值)。
- 执行动作,获得奖励和新状态。
- 使用贝尔曼方程更新 Q表。
- 重复,直到收敛。
4.4. 动作选择策略:ε-greedy
为了避免过早陷入局部最优,采用 ε-greedy 策略:
- 随机数 < ε:随机选择动作(探索)
- 否则:选择当前 Q值最大的动作(利用)
4.5. Q值更新公式
Q值更新基于贝尔曼方程:

其中:
α:学习率(0~1)γ:折扣因子(未来奖励的权重)
4.6. 初始化 Q学习参数
import gym
import numpy as np
env = gym.make('FrozenLake-v0')
discount_factor = 0.95
eps = 0.5
eps_decay_factor = 0.999
learning_rate = 0.8
num_episodes = 500
q_table = np.zeros([env.observation_space.n, env.action_space.n])
4.7. 实现 Q学习算法
for i in range(num_episodes):
state = env.reset()
eps *= eps_decay_factor
done = False
while not done:
if np.random.random() < eps or np.sum(q_table[state, :]) == 0:
action = np.random.randint(0, env.action_space.n)
else:
action = np.argmax(q_table[state, :])
new_state, reward, done, _ = env.step(action)
q_table[state, action] += learning_rate * (
reward + discount_factor * np.max(q_table[new_state, :]) - q_table[state, action]
)
state = new_state
✅ 该算法通过不断更新 Q表,最终能够预测出最优动作。
5. 使用神经网络的强化学习
对于状态和动作数量庞大的实际环境,使用 Q表变得低效甚至不可行。此时,我们可以使用神经网络来预测 Q值。
5.1. 神经网络结构
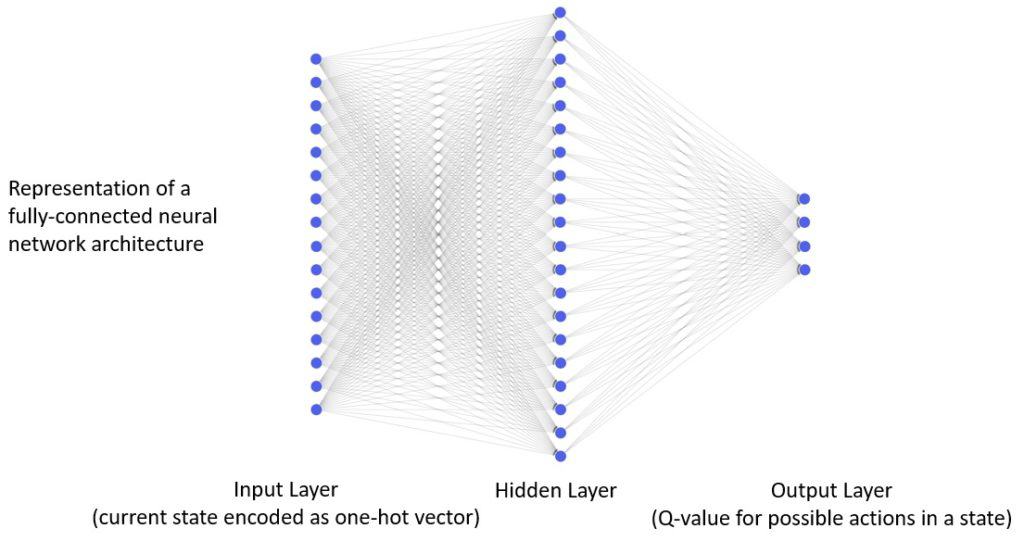
神经网络结构如下:
- 输入层:16 个节点,对应 16 个状态
- 隐藏层:20 个节点,ReLU 激活
- 输出层:4 个节点,对应 4 个动作,线性激活
5.2. 激活函数选择
- 隐藏层:ReLU(引入非线性)
- 输出层:线性(保持 Q值范围)
5.3. 损失函数与优化器
- 损失函数:均方误差(MSE)
- 优化器:Adam(自适应动量估计)
5.4. 使用 Keras 构建模型
from keras.models import Sequential
from keras.layers import InputLayer, Dense
model = Sequential()
model.add(InputLayer(batch_input_shape=(1, env.observation_space.n)))
model.add(Dense(20, activation='relu'))
model.add(Dense(env.action_space.n, activation='linear'))
model.compile(loss='mse', optimizer='adam', metrics=['mae'])
5.5. 基于神经网络的 Q学习实现
for i in range(num_episodes):
state = env.reset()
eps *= eps_decay_factor
done = False
while not done:
if np.random.random() < eps:
action = np.random.randint(0, env.action_space.n)
else:
action = np.argmax(model.predict(np.identity(env.observation_space.n)[state:state + 1]))
new_state, reward, done, _ = env.step(action)
target = reward + discount_factor * np.max(model.predict(np.identity(env.observation_space.n)[new_state:new_state + 1]))
target_vector = model.predict(np.identity(env.observation_space.n)[state:state + 1])[0]
target_vector[action] = target
model.fit(np.identity(env.observation_space.n)[state:state + 1], target_vector.reshape(-1, env.action_space.n), epochs=1, verbose=0)
state = new_state
✅ 该实现通过神经网络替代 Q表,提升了对复杂状态空间的处理能力。
6. 总结
本文介绍了强化学习的基本概念,重点讲解了 Q学习的实现过程,并展示了如何将神经网络引入强化学习中,以应对复杂环境。
- ✅ Q学习适用于状态空间较小的场景。
- ❌ Q表在大规模状态空间中效率低下。
- ✅ 神经网络可以有效替代 Q表,提升泛化能力。
- ⚠️ 实际应用中需注意超参数调优与探索策略设计。
通过结合 Q学习与神经网络,我们迈入了深度强化学习的大门,为处理真实世界的复杂问题打下了基础。