1. 决策树简介
决策树是一种通过检查对象属性来进行分类的模型。它以树形结构表示决策规则,每个节点代表一个属性判断,每个分支代表一个判断结果,每个叶子节点代表最终分类结果。
举个例子,下面是一个用于判断某天是否适合外出活动的决策树:
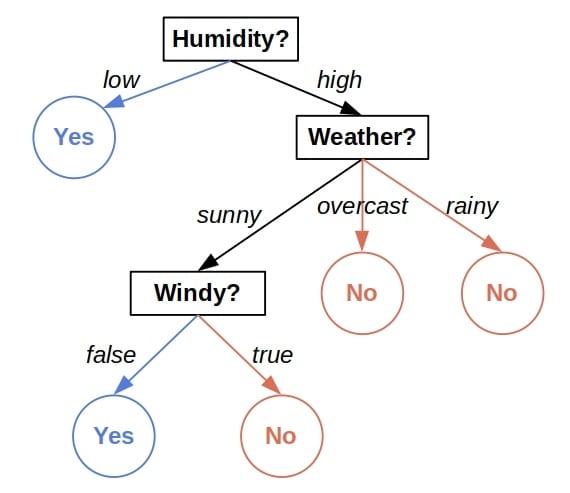
我们从树根开始,依次根据每个节点的属性值向下判断,直到到达叶子节点,得到最终结论。
2. 交叉验证概述
决策树有两个主要类型的参数:
- 训练过程中学习的参数:比如节点的分裂规则。
- 训练前设定的超参数(hyper-parameters):比如最大深度(max depth)、分裂质量评估函数(如 Gini 不纯度或信息增益)等。
这些超参数对模型性能影响显著。为了找到最优的超参数组合,我们通常使用 交叉验证(cross-validation) 方法。
2.1 网格搜索(Grid Search)
网格搜索是一种系统地尝试不同超参数组合的方法。例如,我们想测试两个参数:
d:最大深度(max depth),可选值为{4, 5}q:分裂质量评估函数,可选值为{Gini, Gain}
这样就形成了一个 4 个组合的网格:
[
[d=4, q=Gini],
[d=4, q=Gain],
[d=5, q=Gini],
[d=5, q=Gain]
]
我们对每个组合都进行训练和验证,最终选出表现最好的组合。
2.2 标准交叉验证流程
标准交叉验证通常包括以下步骤:
- 将数据集划分为训练集和测试集。
- 将训练集进一步划分为
m个子集(folds),例如 5 折交叉验证。 - 对于每个 fold:
- 使用除当前 fold 以外的所有 fold 训练模型。
- 使用当前 fold 进行验证。
- 对每个超参数组合,记录
m次验证得分。
最终,我们会得到一个 r x m 的得分矩阵(r 为组合数,m 为折数),例如使用准确率(accuracy)作为评估指标时:
[
[d=4, q=Gini, 0.85, 0.87, 0.87, 0.91, 0.85],
[d=4, q=Gain, 0.81, 0.82, 0.87, 0.85, 0.80],
[d=5, q=Gini, 0.93, 0.93, 0.89, 0.91, 0.95],
[d=5, q=Gain, 0.90, 0.91, 0.93, 0.89, 0.91]
]
2.3 选择最优组合
通常我们选择平均得分最高的组合。但也要注意得分的波动性:
✅ 推荐做法:同时观察平均值和标准差,避免只依赖平均值。
❌ 不推荐做法:直接选择平均值最高但标准差大的组合,可能不稳定。
例如:
(d=5, q=Gini)平均准确率 0.922(d=5, q=Gain)平均准确率 0.908
但如果两者置信区间有重叠,应优先选择更简单或计算更少的模型,比如更小的深度。
2.4 嵌套交叉验证(Nested Cross-Validation)
标准交叉验证的结果依赖于初始的训练/测试划分。为避免这种偏差,可以使用 嵌套交叉验证:
- 外层循环:划分训练集和测试集(outer loop)
- 内层循环:在每个训练集上进行网格搜索和交叉验证(inner loop)
例如,外层划分 3 次,内层每次划分 5 折,总共会有 15 次验证:
[
[split=1, d=4, q=Gini, 0.85, 0.87, 0.87, 0.91, 0.85],
...
]
嵌套交叉验证能更全面评估模型性能,但代价是计算量显著增加。
3. 交叉验证结果的解读
交叉验证的结果是多个训练/验证过程的平均得分。这些得分代表的是:
✅ 模型在特定超参数设置下,训练出的树族(tree family)的平均性能,而不是某一个具体树的表现。
对于嵌套交叉验证,结果还考虑了不同数据划分的影响,因此可以更可靠地估计模型在真实场景下的表现。
4. 小结
- 决策树的性能受超参数影响较大,需通过交叉验证选择最优组合。
- 网格搜索是系统尝试不同组合的有效方式。
- 标准交叉验证适用于大多数场景,但要注意训练/测试划分的影响。
- 嵌套交叉验证更准确,但计算成本更高。
- 结果应结合平均值与标准差综合分析,避免过度依赖单一指标。
✅ 踩坑提醒:不要盲目选择平均值最高的组合,要结合标准差、模型复杂度和实际业务需求综合判断。
✅ 进阶建议:可尝试使用 Pareto 前沿或统计检验进一步筛选最优组合。