1. Introduction
Deciding which type of database to use isn’t always straightforward. Many developers are used to working with relational databases, document databases, and key-value stores.
In turn, graph databases are less talked about and usually overlooked. However, they address specific needs crucial in certain contexts, such as social networks, fraud detection, or recommendation engines, where path-like relationships between data points play a central role.
In this tutorial, we’ll examine the key differences between relational and graph databases to understand when to use which one.
2. Data Structures
2.1. Relational Model
In the relational data model, data is organized into tables, each a collection of rows.
The design is straightforward, with no nested structures. Each table represents an entity, and foreign keys define relationships between entities.
This highly structured model relies on a rigid schema, ensuring data integrity and consistency.
2.2. Graph Model
A graph has two kinds of objects: vertices (nodes) and edges (relationships).
While relational databases can effectively handle many-to-many relationships, it makes sense to consider a graph database when the data is dynamic; the schema must be flexible, and, most importantly, the relationships between data require deep traversal.
Graph databases usually don’t force us to have the same data structures for their nodes and connections.
So, we can mix various structures. For example, if we store information about a company’s organization, the nodes could represent people, events, offices, and locations.
3. Core Aspects
Let’s explore the core aspects of both databases, such as relationship structure, schema, and storage efficiency.
3.1. Relationships
Relational databases efficiently handle large volumes of data by handling relationships between records through joins and utilizing a predefined structure (schema).
Graph databases, on the other hand, store relationships explicitly at the record level, making them suitable for scenarios with complex and dynamic relationships. This flexibility allows graph databases to excel in queries requiring deep relationship traversal, such as finding the shortest path between nodes or analyzing social networks. This approach can also result in performance trade-offs when dealing with large datasets since querying often requires individually examining each node and its connections.
3.2. Schema
In relational databases, the data structure is predefined at the schema level. This allows the database to optimize query execution, especially when working with large datasets. Here’s a simple example of a relational database schema:
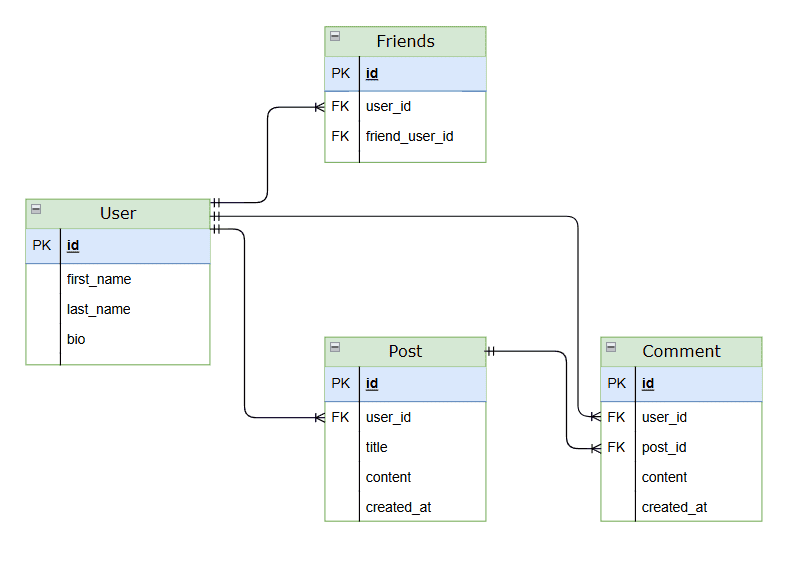
Most graph databases are considered schema-optional, meaning they don’t require a predefined schema before storing data. This allows users to create nodes, relationships, and properties upfront without defining a structure.
While some schema-optional graph databases allow users to introduce indexes and constraints later to optimize performance or enforce data consistency, the schema remains flexible and adaptable. Let’s check an example of a very simple possible graph database state:
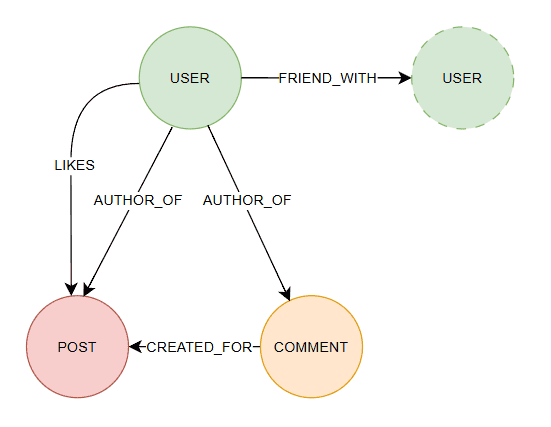
Schema-less databases, where there’s no concept of schema or structure, are very rare.
3.3. Storage Efficiency
Relational databases generally offer better storage efficiency. Foreign keys imply relationships, which are managed at the schema level. This reduces the need for additional storage, making relational databases suitable for large, structured datasets.
Graph databases explicitly store relationships (edges) as part of the data. Because of this, relationships are first-class entities that can have properties. Their physical existence on disk gives us efficient traversal but at increased storage costs.
4. Use Cases and Best Practices
Performance is often a critical factor when choosing between relational and graph databases; each type has strengths and weaknesses.
4.1. Relational Databases Are for Structured Data
Relational databases handle complex queries efficiently, especially when they involve filtering, grouping, or aggregating data within a single table or across tables with simple relationships.
However, performance can degrade when dealing with highly interconnected data because they rely heavily on join operations to link tables.
Although modern relational databases are optimized for joins, multiple joins can quickly become computationally expensive, leading to longer query times and increased resource usage. For instance, in a social network, finding friends of friends or exploring deep connections can result in costly joins.
Relational databases work best for applications with structured, predictable data, such as financial systems, e-commerce platforms, and CRM systems. They are often the preferred choice for the back end of simpler websites. Proper indexing can significantly boost query performance, while normalization reduces redundancy and maintains data integrity. Careful schema design is essential to support future growth and accommodate changes.
4.2. Graph Databases Are for Highly Interconnected Data
Instead of tables and joins, graph databases use nodes and edges to represent entities and their connections. This structure makes traversing relationships very efficient, even when they are deep or complex.
For example, if we want to find all the friends of a person and their friends in a social network, a graph database retrieves this information quickly by avoiding multiple join operations.
In graph databases, relationships act as first-class objects, directly connecting nodes (such as people) through edges (like friendships). These direct connections allow us to traverse these relationships efficiently.
However, graph databases might not perform as well for simple, structured data queries as they specialize in managing and querying complex relationships.
Graph databases excel in scenarios such as social networks, recommendation engines, and network analysis applications. We should always try to optimize traversal queries for efficient data retrieval. Monitoring the graph’s size makes sense to prevent performance issues during write operations. Additionally, we should periodically review and even adjust the graph schema.
4.3. Hybrid Approach
In rare cases, we might use both database types to combine their strengths.
Combining both types can optimize performance and provide more flexibility in handling diverse data needs.
However, this approach has challenges, such as synchronizing data between the two systems and ensuring consistency.
5. Querying
Relational databases use the Structured Query Language (SQL), while graph databases often use Cypher (and GQL after April 2024).
Each language aligns closely with its database’s data model, making it well-suited for different queries. Let’s check out some examples.
5.1. Querying in a Relational Database
Let’s consider a simple relational database for a social network with two tables: Users and Friends. The Users table holds user information, and the Friends table represents relationships: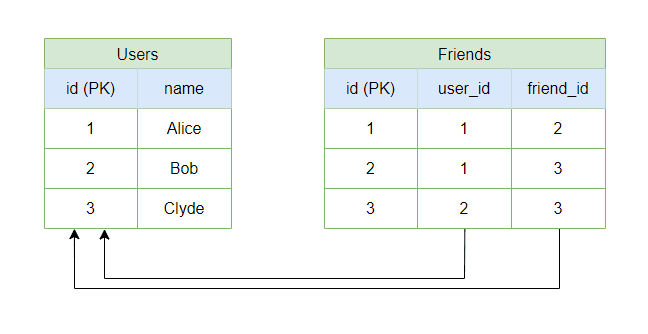
Let’s write an SQL query to find all the friends of the specific user:
-- SQL query to find all friends of a specific user
SELECT u.name
FROM Users u
JOIN Friends f ON u.user_id = f.friend_id
WHERE f.user_id = 1;
In this query, we join the Users table with the Friends table to retrieve the names of all the friends of the user with user_id=1.
While SQL handles these operations across multiple tables efficiently, queries can become less efficient as relationships grow more complex. For example, searching for the friends of the friends of the friends, and so on, may be difficult.
5.2. Graph Database Queries
Let’s revisit the social network example. This time, we’ll use a graph database where users are nodes and friendships are relationships:
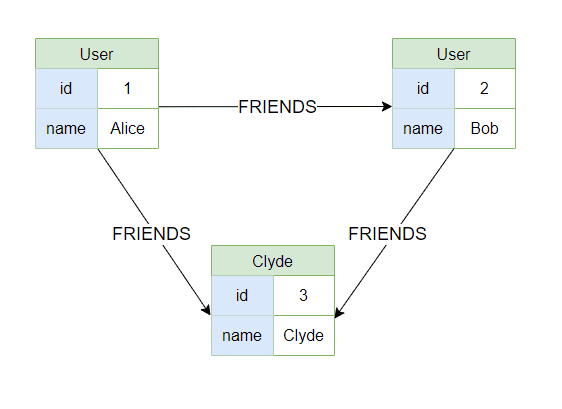
Here’s a Cypher query that returns the same result as the SQL query:
MATCH (u:User)-[:FRIEND]->(friend)
WHERE u.user_id = 1
RETURN friend.name;
In this Cypher query, we use the MATCH clause to specify a pattern where a user node connects to a friend node through a FRIEND relationship. After that, the query returns the names of all the user’s friends. The syntax aligns naturally with the graph data model, making it easier to express complex relationships.
We can perform effective queries on deeper relationships. For example, let’s fetch friends of friends:
MATCH (u:User)-[:FRIEND]->(friend)-[:FRIEND]->(friendOfFriend)
WHERE u.user_id = 1
RETURN friendOfFriend.name;
Cypher can handle even longer path-like relationships.
5.3. Query Complexity for Relationships
Expressing a complex path-like relationship in a graph database is more intuitive and concise than in a relational database. This simplicity in modeling and querying relationships can lead to faster development and fewer errors.
Let’s complete this section with an example of many different kinds of nodes and relationships—Users, Posts, and Comments for nodes and FRIEND, LIKES, COMMENTS_ON, and FOLLOWS for relationships.
Let’s say we want to find all the posts liked by a user’s friends and list the comments made by other users who also follow the original user. This query requires navigating through multiple levels of connections and different types of relationships. In a relational database, just to fetch the comment’s content, we need a long query like this:
SELECT c.content
FROM Users u1
JOIN Friends f ON u1.user_id = f.user_id
JOIN Likes l ON f.friend_id = l.user_id
JOIN Posts p ON l.post_id = p.post_id
JOIN Comments c ON p.post_id = c.post_id
JOIN Follows fo ON c.user_id = fo.follower_id
WHERE u1.user_id = 1 AND fo.following_id = 1;
In the graph database with Cypher, we’ll use something more readable:
MATCH (u:User {user_id: 1})-[:FRIEND]->(friend)-[:LIKES]->(post:Post)<-[:COMMENTS_ON]-(comment:Comment)<-[:MADE]-(commenter)-[:FOLLOWS]->(u)
RETURN commenter.name, post.title, comment.content;
Note that we didn’t specify “friend” and “commenter” types because the connections imply them; i.e., a FRIEND connection can exist only between users.
This Cypher query is much more readable than its SQL counterpart because the relation is more easily defined and expressed as a path than the result of relational operations in the relational model.
6. Scaling
6.1. Relational Database Scaling
Relational databases typically scale vertically, adding more powerful hardware to handle increased loads.
Horizontal scaling (distributing the database across multiple servers) is also widespread, but it’s challenging due to the need to maintain data consistency and integrity across distributed systems. This process often involves sharding or partitioning, dividing data into more manageable pieces that can be distributed across different servers.
Additionally, replication creates copies of the data across multiple instances, such as primary and replica nodes, to ensure high availability and fault tolerance.
While these practices can improve scalability and performance, they add complexity because of data synchronization, query processing, and system management, making it harder to ensure high availability and consistency.
6.2. Graph Database Scaling
Graph databases, on the other hand, are inherently designed for horizontal scaling.
They naturally use partitioning and sharding to distribute data across multiple nodes in a cluster, optimizing its storage and retrieval.
Replication is also used to enhance data availability and resilience. This approach allows graph databases to efficiently handle large volumes of data and complex queries by spreading the load across multiple machines.
For example, Neo4J supports multiple strategies for horizontal scaling.
7. Popular Relational and Graph Databases
Let’s briefly examine some of the most popular databases in both categories.
7.1. Popular Relational Databases
Relational databases have been the backbone of many systems for decades. Here are a few of the most widely used relational databases that have proven reliable and efficient.
MySQL is an open-source relational database known for its ease of use, strong community support, and widespread adoption in web applications.
PostgreSQL is another open-source relational database recognized for its advanced features, such as support for complex data types and full ACID compliance.
Oracle Database is a commercial relational database renowned for its high performance, scalability, and comprehensive security features. It’s widely used in enterprise environments.
Microsoft SQL Server is a relational database management system developed by Microsoft. It offers tight integration with other Microsoft products and robust analytics and reporting tools.
7.2. Popular Graph Databases
Although graph databases are less known, a solid range of options is available.
Neo4j is the leading graph database that provides native graph storage and processing optimized for traversing highly interconnected data.
Amazon Neptune is a fully managed graph database service by AWS that supports property graph and RDF (Resource Description Framework) graph models for flexible graph data management.
Finally, ArangoDB is a native multi-model database that supports graph, document, and key/value data models, offering flexibility and performance for diverse applications like IoT and social networks.
8. Summary
Let’s summarize the key differences between both databases:
Relational Databases
Graph Databases
Data Model
Tables with rows and columns
Nodes and edges with properties
Schema
Predefined schema required
In most of the cases, schema-optional
Relationships
Represented by foreign keys and joins
Represented by edges between nodes
Query Languages
SQL is the dominant language
Cypher, GQL, Gremlin, etc.
Performance
Scales vertically, but scaling horizontally could be cumbersome
A graph database excels in representing and querying relationships between data.
Scalability
Typically scales vertically (adding more powerful hardware)
Great at scaling horizontally
Ease of Use
Suitable for structured data and simple queries, but complex relationships can be challenging.
Intuitive for relationship-centric data, enabling efficient traversal across connected data.
These differences offer high-level guidelines for making the most suitable choice. However, while the table highlights the core differences, the right choice often depends on the project’s unique challenges.
9. Conclusion
In this article, we discussed how a choice between relational and graph databases depends on our specific use case and data needs.
Relational databases excel in handling structured data, complex transactions, and predefined schemas. They are ideal for traditional applications that prioritize data integrity and efficient querying. At the same time, graph databases are best for applications with highly interconnected entities and semi-structured data.