1. 概述
在本教程中,我们将介绍机器学习(Machine Learning, ML)模型中的三个核心组成部分:特征(Features)、参数(Parameters)和类别(Classes)。
这些概念贯穿于几乎所有机器学习任务中,理解它们有助于我们更好地构建、调试和优化模型。
2. 前置知识
近年来,机器学习已经深刻改变了我们的生活和工作方式。从工程、金融到医学、生物学,ML 的应用无处不在,比如自动驾驶、疾病预测等。总体而言,机器学习的目标是理解数据的结构,并将其拟合为人类可理解、可使用的模型。
这些模型是现实世界过程的数学表示,主要分为两大类:
- ✅ 监督学习(Supervised Learning):使用带有标签的数据集,训练模型进行分类或预测。
- ✅ 无监督学习(Unsupervised Learning):处理无标签数据,通常用于聚类分析。
3. 特征(Features)
特征是模型的输入变量,也称为特征向量中的各个维度。它们是描述任务属性的独立变量。
选择信息丰富、具有区分性且相互独立的特征,是构建模型的第一步。在传统机器学习中,特征往往需要人工设计和提取;而在现代深度学习中,特征可以由模型自动学习得到。
示例:研究生录取预测
假设我们要构建一个模型,预测某学生是否能被研究生院录取。我们可以选择以下特征:
- ✅ 本科 GPA
- ✅ 推荐信质量(来自教授或雇主)
- ✅ 标准化考试成绩(如 GRE、GMAT)
- ✅ 是否有发表论文
- ✅ 本科期间参与的项目经历
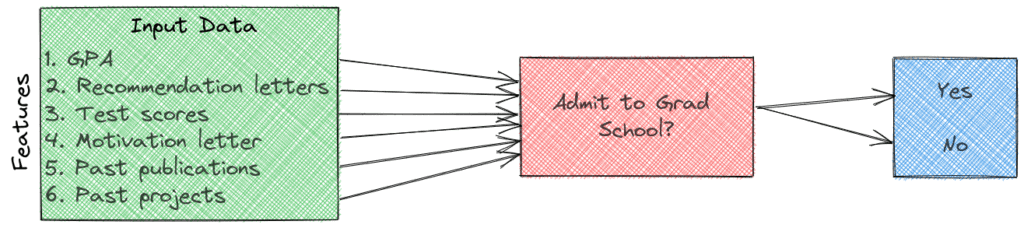
这些变量共同影响录取结果,因此可以作为模型输入特征。如果特征太多,可以使用特征选择方法进行降维。
4. 参数(Parameters)
参数是模型内部的变量,它们是通过训练数据学习或估计出来的。换句话说,参数决定了模型的行为。
训练开始时,参数通常被初始化为某些值。在训练过程中,优化算法(如梯度下降)会不断更新这些参数。训练结束后,最终的参数集合就构成了模型本身。
不同模型中的参数示例
- ✅ 线性回归(Linear Regression):模型形式为
y = ax + b,其中a和b是模型参数。 - ✅ 神经网络(Neural Network):权重(weights)和偏置(biases)是模型参数。
- ✅ 聚类模型(如 K-Means):聚类中心(centroids)是模型参数。
⚠️ 注意:参数 ≠ 超参数(Hyperparameters)
超参数是我们在训练前手动设置的,而不是从数据中学习得到的。例如,在 K-Means 中,聚类数量 k 是超参数,而聚类中心是参数。
5. 类别(Classes)
类别仅适用于分类任务(Classification),即我们希望模型将输入特征映射到一个离散的输出变量。
这些输出变量就是所谓的类别(也称为标签)。例如:

在我们前面提到的研究生录取预测任务中,输出只有两个类别:
- ✅ 被录取(Accepted)
- ✅ 未被录取(Not Accepted)
6. 总结
本文我们介绍了机器学习模型中的三个核心组成部分:
| 组成 | 说明 | 示例 |
|---|---|---|
| ✅ 特征(Features) | 模型输入变量,用于描述数据 | GPA、推荐信、考试成绩等 |
| ✅ 参数(Parameters) | 模型内部变量,训练过程中自动学习 | 线性回归中的系数、神经网络中的权重 |
| ✅ 类别(Classes) | 分类任务的输出标签 | “被录取”、“未被录取” |
理解这些概念对构建和优化模型至关重要,特别是在特征工程、模型调参和结果解释方面。掌握它们,有助于我们更高效地“踩坑”和排错。