1. 简介
在本文中,我们将讨论两个神经网络训练中非常关键的超参数:学习率(Learning Rate) 和 批量大小(Batch Size)。我们会分别介绍它们的定义和作用,并进一步分析它们之间的关系。
同时,我们还会讨论一些在实际训练中如何调整这两个参数的经验法则,以及它们之间是否存在某种内在联系。
2. 学习率(Learning Rate)
学习率是机器学习和优化算法中的一个核心概念。它决定了模型在每次梯度下降时朝着损失函数最小值移动的步长。
学习率的重要性不言而喻。设置得太小,训练会非常慢;设置得太大,又可能导致模型无法收敛,甚至发散。
2.1 梯度下降中的学习率
在梯度下降法中,我们根据损失函数对权重的梯度方向来更新参数。学习率控制了这一步的“力度”:
学习率 = 梯度下降步长
下图展示了学习率过大或过小对训练过程的影响:
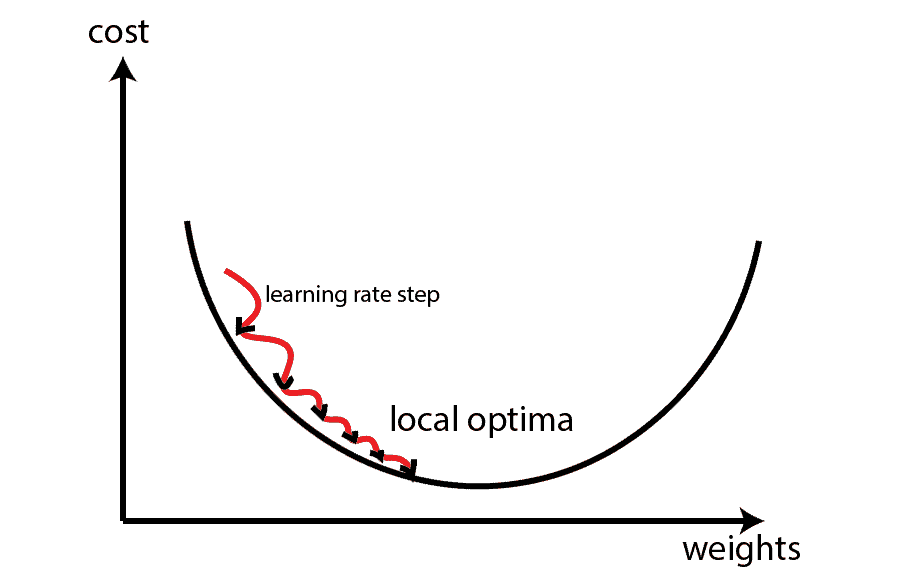
- ✅ 合适的学习率:模型快速收敛到最优值。
- ❌ 太小的学习率:训练慢,容易陷入局部极小值或鞍点。
- ❌ 太大的学习率:参数更新“跳过”最优值,导致震荡甚至发散。
2.2 学习率的动态调整
学习率不一定是固定不变的。常见的策略包括:
- 逐步衰减(Step Decay):每隔几个 epoch 减小学习率。
- 指数衰减(Exponential Decay):按指数规律衰减。
- 自适应优化器(如 Adam):自动调整学习率。
在实际使用中,建议从 0.1、0.01、0.001 等值开始尝试,再根据验证集表现进行调整。
3. 批量大小(Batch Size)
批量大小指的是在一次参数更新中使用的样本数量。它直接影响训练速度、内存占用和模型泛化能力。
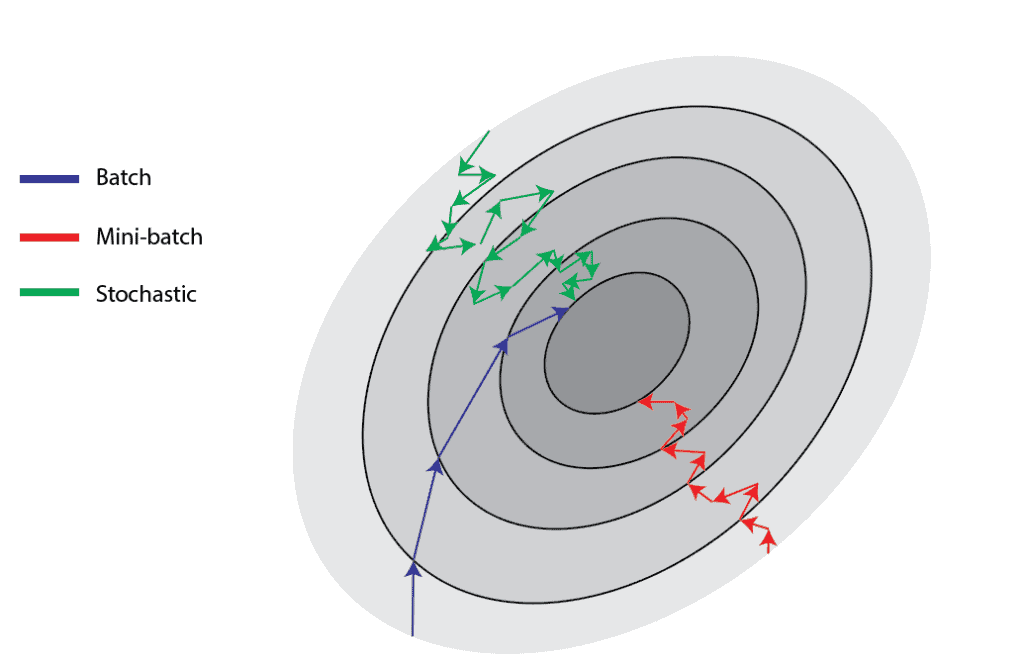
3.1 三种梯度下降方式
根据批量大小的不同,梯度下降可以分为三类:
| 类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 批量梯度下降(Batch GD) | 使用整个训练集 | 稳定,收敛方向明确 | 计算开销大 |
| 随机梯度下降(Stochastic GD) | 每次只用一个样本 | 更新快,适合在线学习 | 收敛波动大 |
| 小批量梯度下降(Mini-batch GD) | 每次使用固定数量样本 | 平衡收敛速度与稳定性 | 需调参 |
这是最常见的训练方式,推荐批量大小设置为 2 的幂,比如 16、32、64、128、256、512 等。32 是一个经验起点值。
下图展示了不同批量大小下的训练效果对比:
3.2 批量大小的影响
批量大小会影响以下几个方面:
- ✅ 训练速度:越大越快,但受限于内存。
- ✅ 模型性能:合适的大小有助于提升泛化能力。
- ✅ 内存占用:越大占用越多。
- ✅ 更新频率:越小更新越频繁,模型更“灵活”。
4. 学习率与批量大小的关系
很多人会问:如果我改变了批量大小,是否也应该调整学习率?这个问题在理论和实践中都有研究。
我们先假设使用的是普通的 mini-batch SGD,而非 Adam 等自适应优化器。因为对于后者,学习率的调整通常不是必须的。
4.1 理论视角
有研究表明,当批量大小乘以 k 倍时,学习率也应相应调整:
- 线性缩放规则(Linear Scaling Rule):
- 批量大小 ×k → 学习率 ×k
- 平方根缩放规则(Square Root Scaling Rule):
- 批量大小 ×k → 学习率 ×√k
其中,线性缩放在实践中更常用。例如,在 ImageNet 上使用 8k 的批量大小时,通过线性缩放学习率,依然可以保持训练效果一致。
4.2 实验验证
在 MNIST 上训练一个简单的 CNN(包含一个卷积层、Dropout 和全连接层),我们测试了不同批量大小和学习率组合下的训练效果:
- 基准配置:batch_size = 8,lr = 0.001
- 倍数范围:2 到 7 倍
下图展示了不同配置下的训练曲线对比:
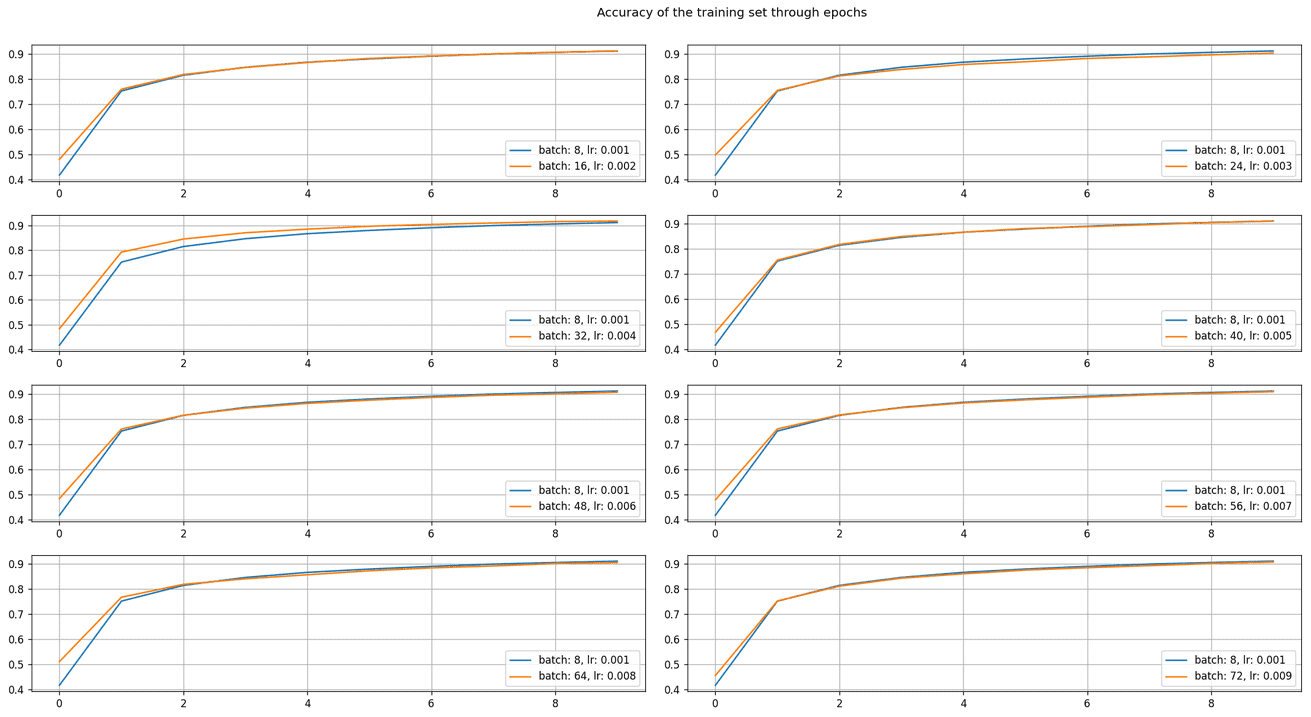
✅ 结果显示:通过线性缩放学习率,不同批量大小下的训练曲线高度一致。
4.3 实践建议
尽管理论上有明确的缩放规则,但在实际应用中:
- ❗ 目标不是复制训练曲线,而是获得最佳性能。
- ✅ 如果增大批量后模型效果更好,就没必要调整学习率来“还原”之前的训练效果。
- ✅ 超参数调优是一个整体过程,学习率和批量大小通常与其他参数一起调整。
- ⚠️ 冷启动(Warmup)策略:在训练初期逐步增加学习率,防止早期震荡。
5. 总结
学习率和批量大小是影响神经网络训练效果的两个关键超参数:
- ✅ 学习率决定梯度下降的“步长”,太小训练慢,太大容易发散。
- ✅ 批量大小影响训练速度、内存占用和模型泛化能力。
- ✅ 理论上建议学习率与批量大小按比例缩放(如线性缩放)。
- ✅ 实践中应以最终模型效果为目标,灵活调整。
最后,记住一句话:
我们的目标是训练出性能最好的模型,而不是追求学习率与批量大小之间的某种固定比例。