1. 简介
生成对抗网络(GANs)是一种无监督深度学习方法,近年来在图像生成、风格迁移等领域大放异彩。本文将从 GAN 的基本结构入手,重点解析其两个核心组件 —— 生成器(Generator)和判别器(Discriminator)的工作机制,并深入探讨它们的损失函数(Loss Function)在训练过程中的作用。
2. 生成对抗网络概述
GAN 最早由 Ian J. Goodfellow 等人在 2014 年提出,其核心思想是让两个神经网络相互博弈:生成器负责生成尽可能逼真的假数据,而判别器则负责判断输入数据是真实数据还是由生成器伪造的。这种对抗过程最终使得生成器能够输出与真实数据分布高度相似的样本。
GAN 的基本结构如下图所示:
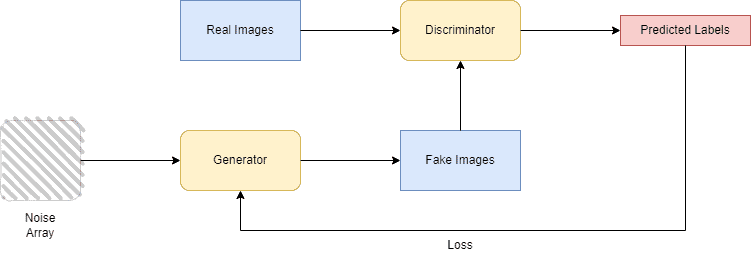
2.1 GAN 的损失函数
GAN 的训练过程本质上是一个极小极大博弈(Minimax Game),其目标函数如下:
$$ \underset{G}{\min} ; \underset{D}{\max} ; V(D,G) = \mathbb{E}{x} [\log D (x) ] + \mathbb{E}{z} [\log (1 - D (G(z))) ] $$
其中:
- $ G(z) $:生成器以噪声 $ z $ 为输入生成的假样本
- $ D(x) $:判别器判断真实样本 $ x $ 为真实的概率
- $ D(G(z)) $:判别器判断生成样本为真实的概率
- $ \mathbb{E}_x $、$ \mathbb{E}_z $:分别表示对真实数据和生成数据的期望
这个公式可以理解为:
- 判别器的目标是最大化 $ \log D(x) $,即尽可能正确识别真实样本;
- 同时最大化 $ \log(1 - D(G(z))) $,即尽可能识别生成样本为假;
- 生成器的目标是最小化 $ \log(1 - D(G(z))) $,即让判别器误以为生成样本是真实的。
3. 生成器(Generator)
生成器的职责是根据输入的随机噪声 $ z $,生成尽可能逼真的数据。训练过程中,生成器不断尝试欺骗判别器,使其误判生成的数据为真实数据。
3.1 生成器的奖励机制
当判别器将生成器生成的样本误判为真实数据时,生成器就“获胜”,并获得正向反馈。反之则被惩罚。生成器的训练目标是通过梯度下降法最小化以下损失函数:
$$ \nabla_{\theta_g} \frac{1}{m} \sum_{i=1}^{m} \log (1 - D(G(z^{(i)}))) $$
其中:
- $ \theta_g $:生成器的参数;
- $ G(z; \theta_g) $:生成器函数;
- $ m $:批量大小(batch size)。
生成器通过不断调整参数,使判别器对生成样本的判断趋近于 1(即认为是真实样本)。
4. 判别器(Discriminator)
判别器的职责是区分输入数据是真实样本还是由生成器生成的假样本。它本质上是一个二分类器,输出一个概率值表示输入为真实数据的可能性。
4.1 判别器的奖励机制
如果判别器正确识别了输入数据的真实与否,它就“获胜”并获得正向反馈。否则,它被惩罚。判别器的训练目标是最大化以下损失函数:
$$ \nabla_{\theta_d} \frac{1}{m} \sum_{i=1}^{m} [ \log D(x^{(i)}) + \log (1 - D(G(z^{(i)}))) ] $$
其中:
- $ \theta_d $:判别器的参数;
- $ D(x^{(i)}) $:判别器对真实样本的判断;
- $ D(G(z^{(i)})) $:判别器对生成样本的判断。
判别器通过调整参数,使得对真实样本的输出趋近于 1,对生成样本的输出趋近于 0。
5. GAN 的局限性
尽管 GAN 在图像生成、风格迁移等领域表现出色,但也存在一些显著的挑战和局限性:
✅ 优点:
- 可以生成高质量、逼真的图像;
- 支持无监督学习,适合缺乏标签的数据集;
- 可用于数据增强、图像修复等任务。
❌ 缺点与挑战:
- 训练不稳定:判别器和生成器之间需要良好的平衡,否则一方过强会导致训练失败;
- 模式崩溃(Mode Collapse):生成器可能只生成少数几种样本,缺乏多样性;
- 难以评估训练效果:缺乏统一的指标衡量 GAN 的性能;
- 生成离散数据困难:如文本、语音等,GAN 的效果通常不如其他模型。
6. 应用场景
GAN 的应用场景非常广泛,主要包括以下几个方面:
- ✅ 图像生成:如人脸生成、卡通角色生成、图像修复;
- ✅ 图像转换:如将黑白图像转为彩色、将草图转为照片;
- ✅ 视频生成:可用于动画制作、虚拟人生成;
- ✅ 数据增强:在数据量不足时,生成额外训练样本;
- ✅ 风格迁移:如将照片风格转换为梵高画风;
- ✅ 安全领域:用于生成对抗样本,测试模型鲁棒性。
7. 总结
本文详细介绍了生成对抗网络(GAN)的基本原理及其两个核心组件 —— 生成器和判别器的损失函数。我们从数学角度分析了它们在训练过程中的博弈关系,以及损失函数如何引导模型更新参数。
GAN 的训练过程充满挑战,但其生成能力在多个领域展现出了巨大潜力。对于经验丰富的开发者来说,理解其损失函数的含义是调优和改进模型的关键一步。
如果你正在研究图像生成、风格迁移或数据增强方向,GAN 是一个值得深入掌握的技术方向。