1. Goal-Based Agent(目标型智能体)
目标型智能体是一种旨在达成特定目标的 AI 系统。这个目标可以是走迷宫、玩游戏,甚至完成某个任务。它通常会根据当前环境状态,选择最优策略来实现目标。
这类智能体依赖于搜索算法和启发式方法(heuristics)来寻找达到目标的最有效路径。此外,它通常也被称为规划型(planning)或目标导向型(goal-seeking)智能体。在某些情况下,我们也会称其为规则型智能体,因为它遵循一套预设的规则来采取行动。
我们可以为这类智能体设定特定条件下的行为逻辑,例如:“如果前方是障碍物,则绕行”。它广泛应用于机器人控制、计算机视觉、自然语言处理等领域。
下面这张图展示了目标型智能体的工作流程:
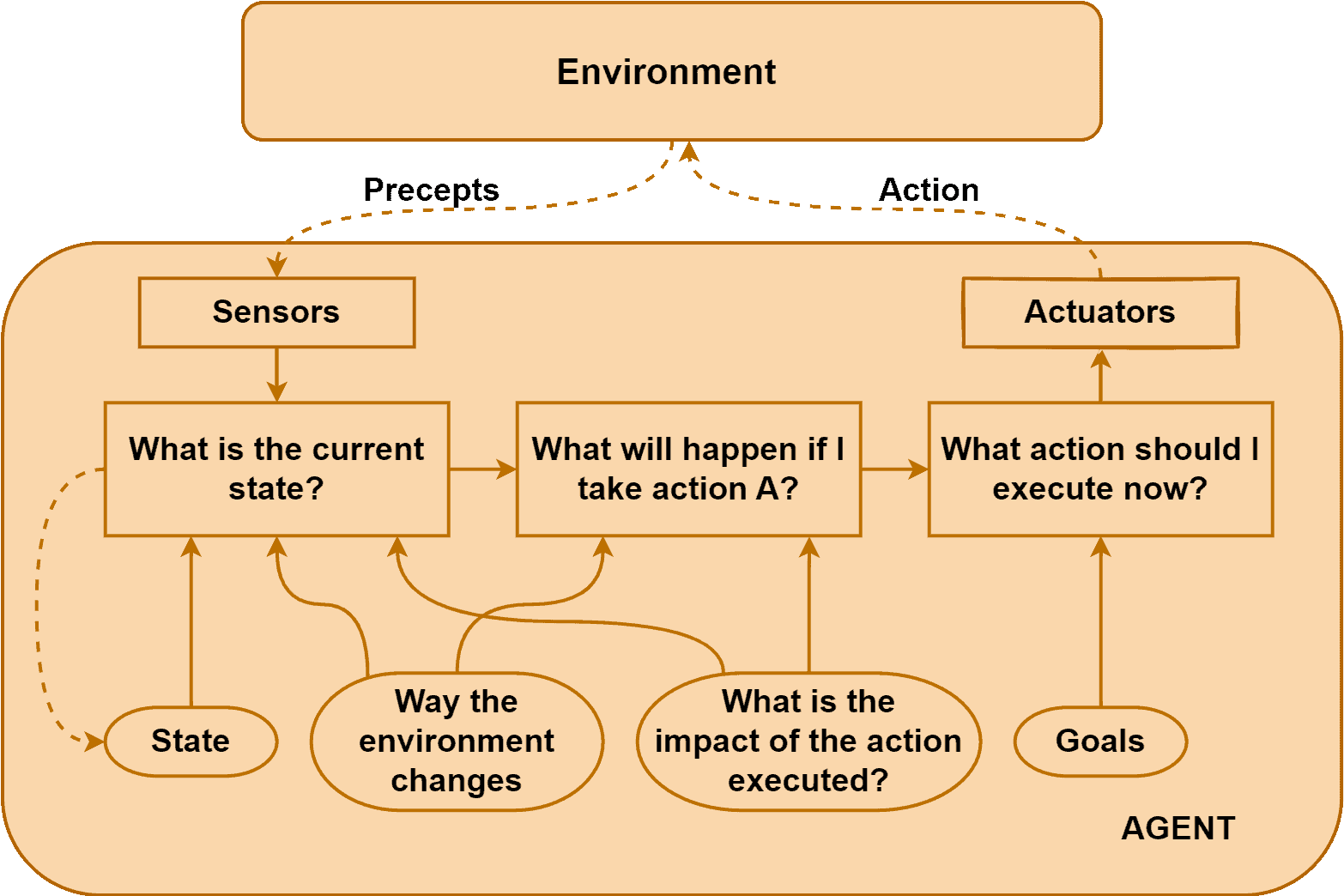
示例:Breakout 游戏中的目标型智能体
以经典游戏 Breakout 为例:
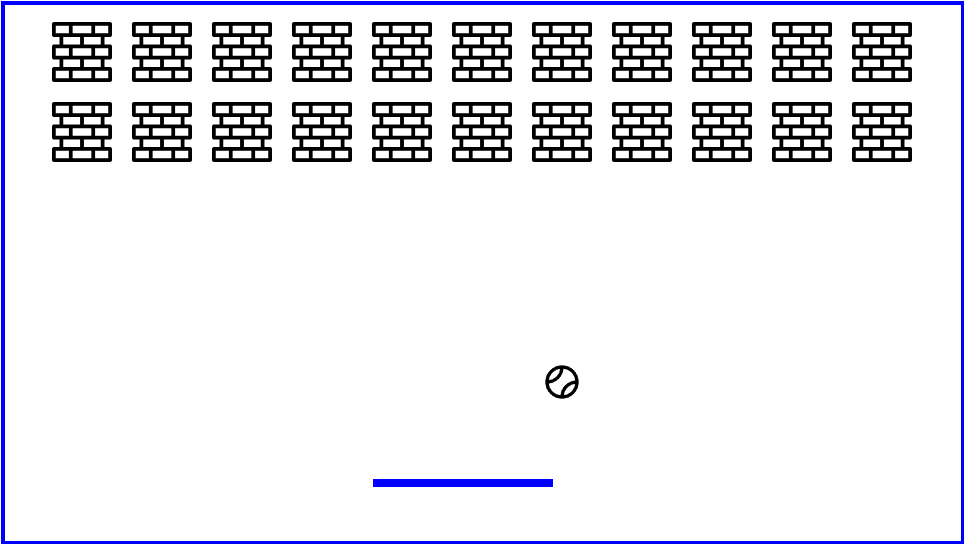
在这个游戏中,玩家控制底部的挡板来反弹球以击碎顶部的砖块。目标是尽可能多地击碎砖块并得分。
目标型智能体的目标是最大化击碎砖块数量。它会根据球的位置、挡板的位置、砖块分布等信息,不断评估环境并做出动作决策(例如向左或向右移动挡板),以逼近目标。
这类智能体通过探索环境和设定规则来学习如何最大化奖励。它的行为是目标驱动的,一旦目标达成(如击碎所有砖块),任务即完成。
2. Utility-Based Agent(效用型智能体)
效用型智能体的目标是最大化某个效用函数(utility function),而不是完成一个具体的目标。效用函数可以是利润最大化、能耗最小化,也可以是游戏中的得分最大化。
这类智能体没有明确的“终点”,而是根据当前状态和行为选择最能提升效用值的行动。它通常使用优化算法(如梯度下降、遗传算法)和启发式方法来不断调整策略,以逼近最优解。
效用型智能体通过一个预定义的效用函数来评估不同行为的优劣。这个函数可能包含多个因素,如当前得分、剩余生命、时间消耗等。它会综合这些因素来做出最优决策。
下图展示了效用型智能体的工作流程:
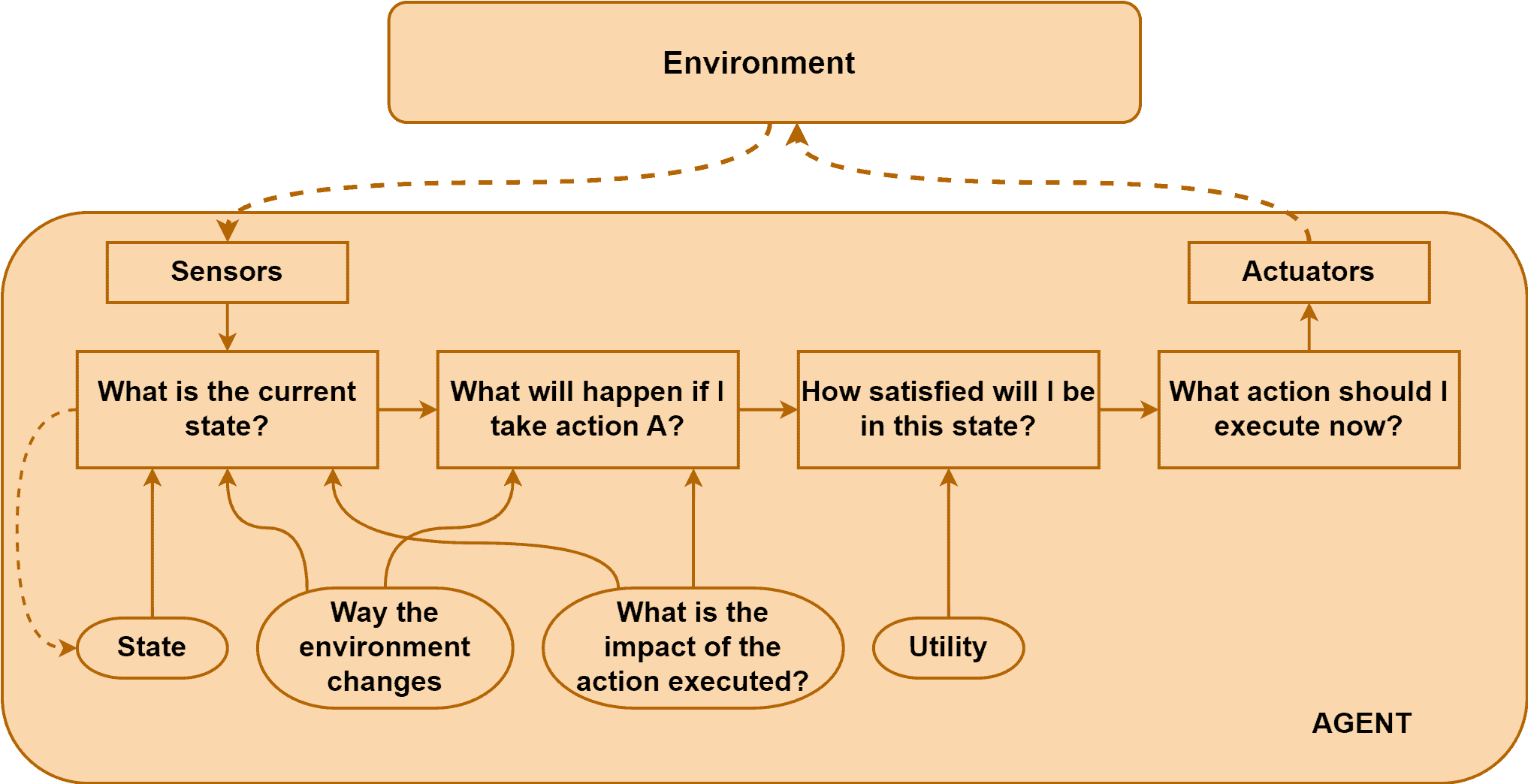
示例:Pac-Man 游戏中的效用型智能体
考虑训练一个能玩 Pac-Man 的智能体:
玩家控制角色在迷宫中移动,吃掉所有豆子即可进入下一关。同时,有鬼怪会追击玩家,如果被吃掉则会受到惩罚(如扣分、关卡重置)。
我们可以为这个智能体设计一个效用函数,例如:
Utility = 10 * 收集到的豆子数 - 50 * 被鬼吃掉次数
智能体通过观察屏幕状态(如角色位置、鬼的位置、剩余豆子数等),计算每一步的效用值,并选择使效用最大化的动作。
此外,效用型智能体还能从经验中学习,不断调整效用函数参数,以适应更复杂的环境变化。
3. 两者核心区别对比
| 特性 | Goal-Based Agent(目标型) | Utility-Based Agent(效用型) |
|---|---|---|
| ✅ 决策依据 | 是否有助于达成目标 | 是否最大化效用函数 |
| ✅ 行为模式 | 固定目标导向 | 灵活适应不同状态 |
| ✅ 可靠性 | 搜索空间有限,可能产生意外结果 | 能从环境中学习,表现更稳定 |
| ✅ 编程难度 | 较简单 | 实现较复杂 |
| ✅ 应用场景 | 计算机视觉、机器人、NLP | GPS导航、资源调度、游戏AI |
| ✅ 决策方式 | 考虑是否达成目标 | 给每个状态打分,选择最优路径 |
4. 总结
本文介绍了两种常见 AI 智能体:目标型智能体与效用型智能体。
- 目标型智能体专注于达成特定目标,适用于任务明确、目标清晰的场景。
- 效用型智能体则通过最大化效用函数来优化整体表现,更适合复杂、多变量的环境。
选择哪种智能体取决于具体应用场景和需求。在实际开发中,有时也会结合两者优势,构建更复杂的混合型智能体系统。