1. 概述
本文将探讨梯度下降(Gradient Descent)与梯度上升(Gradient Ascent)之间的区别。
学完本文后,你将能够理解它们各自的应用场景,并掌握如何在两者之间进行转换。
2. 梯度的基本概念
一个连续函数  的梯度定义为:在某一点
的梯度定义为:在某一点  处所有偏导数组成的向量,即:
处所有偏导数组成的向量,即:
![\nabla f(x) = [\frac{\delta{f}}{\delta{x_1}}(p), \frac{\delta{f}}{\delta{x_2}}(p), ... , \frac{\delta{f}}{\delta{x_{|x|}}}(p)]^T](/wp-content/ql-cache/quicklatex.com-133a31967b684d56f788e2ceaf4d4a89_l3.svg "Rendered by QuickLaTeX.com")
梯度存在的前提是所有偏导数都定义良好且有限。
在优化过程中,我们可以使用梯度进行梯度下降或梯度上升,接下来我们来看它们的区别。
3. 梯度下降
✅ 梯度下降是一种迭代优化方法,常用于优化机器学习模型的参数。它广泛应用于:
- 神经网络
- 逻辑回归
- 支持向量机(SVM)
它是最小化代价函数最常用的方法之一。
⚠️ 它的一个主要限制是:只能保证收敛到局部最小值,而非全局最小值。
如下图所示,模型可能陷入局部最小值而非全局最小值:
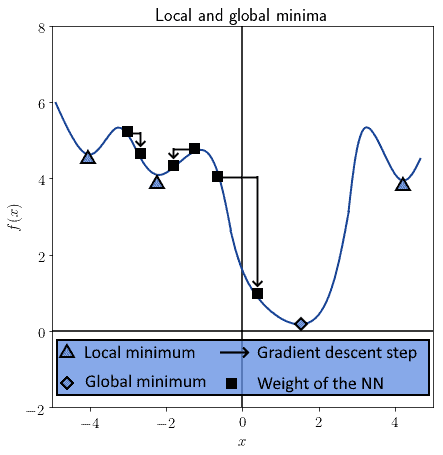
梯度下降中引入一个超参数  (也称为学习率),用于控制下降步长。选择合适的 α 值有助于跳出局部最小值,向全局最小值靠近。
(也称为学习率),用于控制下降步长。选择合适的 α 值有助于跳出局部最小值,向全局最小值靠近。
在神经网络中,梯度下降作用于权重矩阵的过程被称为误差反向传播(Backpropagation)。
梯度的符号决定了权重是增加还是减少。公式如下:

图形表示如下:
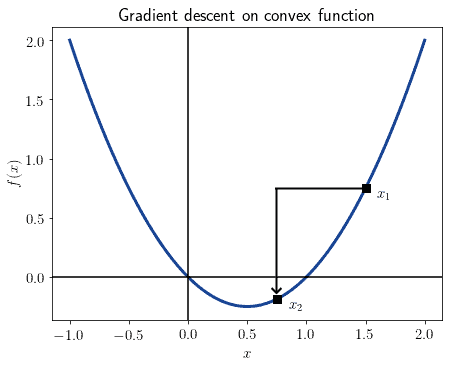
✅ 公式解读:
- 在第 n 步,权重
 被更新为:当前值减去 α 乘以当前梯度
被更新为:当前值减去 α 乘以当前梯度 - 若梯度为正,则权重减少;若梯度为负,则权重增加
4. 梯度上升
✅ 梯度上升与梯度下降原理相同,但目标是最大化目标函数而非最小化。
比如在支持向量机中,我们需要最大化分类超平面与样本点之间的距离,这时就使用梯度上升。
梯度上升的更新公式如下:

✅ 公式解读:
- 与梯度下降相比,仅符号不同
- 梯度上升朝最近的最大值方向移动
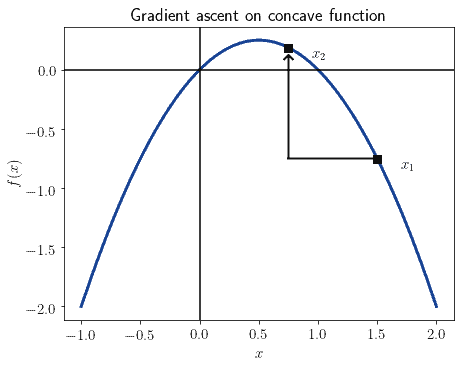
⚠️ 梯度下降适用于凸函数,而梯度上升则适用于凹函数。
比如在逻辑回归中:
- 使用正的对数似然(log-likelihood)时,目标函数是凹函数,应使用梯度上升
- 使用负的对数似然时,目标函数是凸函数,应使用梯度下降
如下图所示,将原函数沿 x 轴翻转后即可在不同优化方式之间切换:
5. 如何选择梯度下降或梯度上升?
总结如下几个关键点:
- ✅ 梯度是函数在某点的所有偏导数组成的向量
- ✅ 梯度下降用于最小化凸函数,梯度上升用于最大化凹函数
- ✅ 梯度下降寻找局部最小值,梯度上升寻找局部最大值
- ✅ 同一问题可通过翻转目标函数在两者之间切换
⚠️ 实际应用中,梯度下降更常见,因为多数优化问题以最小化损失函数为目标。
6. 小结
本文我们学习了:
- 梯度的定义
- 梯度下降与梯度上升的数学表达式与使用场景
- 如何在两者之间转换
- 实际应用中为何梯度下降更常用
理解这两个概念有助于我们在优化问题中做出更合理的选择。