1. 概述
堆(Heap) 是一种常用的基于树的数据结构。堆中常见的操作之一是插入新节点。
本文将详细讲解 如何向堆中插入新节点,并对其插入过程的 时间复杂度 进行分析。
2. 插入算法
我们先来看一下堆插入的基本算法流程,之后再逐步解释:
algorithm Insertion(B, N, newValue):
// INPUT
// B = input array
// N = starting index
// newValue = new node to insert
// OUTPUT
// Heap tree with the new node
N <- N + 1
B[N] <- newValue
k <- N
while k > 1:
PNode <- k / 2
if B[PNode] < B[k]:
swap(B[PNode], B[k])
k <- PNode
else:
return
算法的输入包括一个数组 B,堆的当前大小 N,以及要插入的新值 newValue。我们使用 PNode 表示父节点索引。
插入步骤详解 ✅
- 增加堆的大小:
N = N + 1,为新节点腾出空间。 - 将新节点插入到堆末尾:
B[N] = newValue。 - 从新节点开始向上调整(heapify up):
- 比较当前节点与其父节点的值。
- 如果不符合堆的性质(如最大堆中子节点比父节点大),则交换两者。
- 继续向上检查,直到堆性质恢复或到达根节点。
⚠️ 插入后必须维护堆的结构,否则后续操作可能出错,这是使用堆时的常见“踩坑点”。
插入过程图示
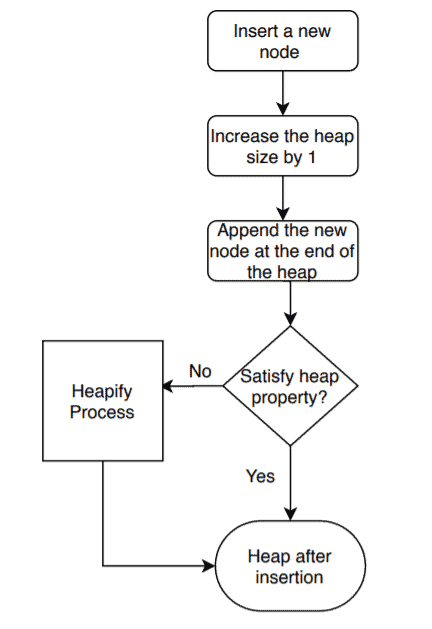
3. 时间复杂度分析
最佳情况(Best Case)✅
如果新插入的节点满足堆的性质,不需要进行任何交换操作,插入操作只需一次赋值即可完成。
此时时间复杂度为:
$$
\mathbf{\mathcal{O}(1)}
$$
最坏情况(Worst Case)✅
最坏情况下,新节点必须从叶子节点一直交换到根节点,才能恢复堆的性质。
由于堆是一棵 完全二叉树,其高度为: $$ \mathbf{\mathcal{O}(\log N)} $$
每次交换操作为常数时间 $\mathcal{O}(1)$,因此最坏情况下的时间复杂度为: $$ \mathbf{\mathcal{O}(\log N)} $$
⚠️ 有些开发者误以为堆是普通的二叉搜索树,从而错误估计其性能。堆的高度特性来源于其“完全性”,这一点要特别注意。
4. 总结
本文我们讨论了堆插入节点的算法流程,并分析了插入操作的 最佳和最坏情况下的时间复杂度:
| 情况 | 时间复杂度 |
|---|---|
| 最佳情况 | $\mathcal{O}(1)$ |
| 最坏情况 | $\mathcal{O}(\log N)$ |
堆的插入操作效率较高,适用于需要频繁插入并维护堆性质的场景,例如优先队列、Dijkstra算法等。掌握其时间复杂度有助于我们在实际开发中更高效地使用堆结构。