1. 概述
本文将介绍两种常用的数据结构:堆(Heap) 与 二叉搜索树(Binary Search Tree, BST)。我们将从结构特性、操作效率、适用场景等方面进行比较,帮助你在实际开发中做出更合适的选择。
我们假设你已具备基本的数据结构知识。如果你还不熟悉 BST 或 Heap 的基本概念,建议先补充相关内容。
2. 二叉搜索树(BST)
二叉搜索树是一种基于二叉树的有序数据结构。其核心特性是:
- 每个节点最多有两个子节点(左子节点、右子节点)
- 对于任意节点:
- 左子节点的值 < 当前节点的值
- 右子节点的值 > 当前节点的值
- 所有节点值唯一(不支持重复值)
这使得 BST 中的数据天然有序,可以通过中序遍历得到升序序列。
示例图示
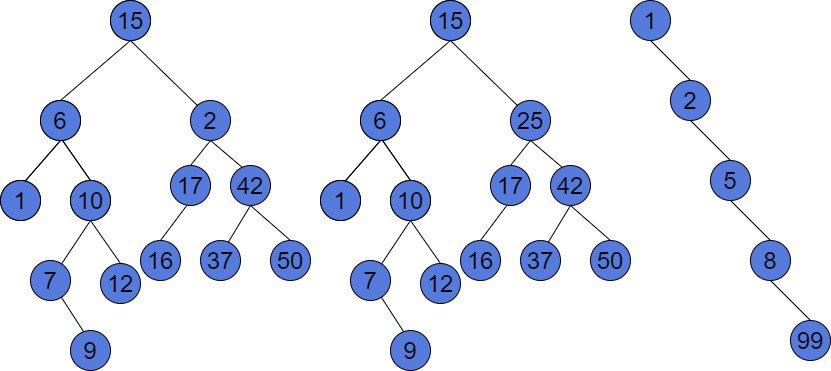
图中左侧的树不是 BST,因为某些节点违反了 BST 的大小规则。中间和右侧的树是合法的 BST。
时间复杂度分析
- 查找、插入、删除:
- 最坏情况(树退化为链表):✅ O(n)
- 平衡 BST(如 AVL、红黑树):✅ O(log n)
- 构建 BST:
- 插入 n 个节点,每次 O(log n):✅ O(n log n)
- 遍历获取有序序列:✅ O(n)
⚠️ 如果插入顺序不当,BST 可能退化成链表,严重影响性能。使用平衡 BST 可避免这个问题。
3. 堆(Heap)
堆是一种完全二叉树(Complete Binary Tree)结构,通常用于实现优先队列(Priority Queue)。
完全二叉树的定义
- 除了最后一层外,其余层都满
- 最后一层从左到右填充
堆有两种类型:
- 最小堆(Min-Heap):父节点 ≤ 子节点,根节点最小
- 最大堆(Max-Heap):父节点 ≥ 子节点,根节点最大
堆允许重复值。
存储方式
堆在内存中通常用数组表示。索引关系如下:
- 父节点索引 i
- 左子节点索引:2 * i + 1
- 右子节点索引:2 * i + 2
示例图示
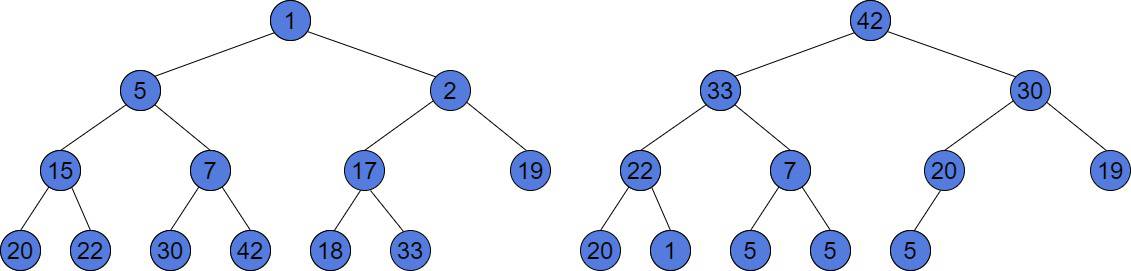
左侧是 Min-Heap,右侧是 Max-Heap。它们都满足堆的结构与值顺序规则。
时间复杂度分析
- 构建堆:
- 一般方法:✅ O(n log n)
- 优化算法(自底向上):✅ O(n)
- 插入、删除(堆顶):✅ O(log n)
- 获取有序序列(堆排序):✅ O(n log n)
⚠️ 堆是无序结构,不能直接遍历得到有序序列,必须反复弹出堆顶元素。
4. 堆 vs BST:对比分析
| 特性 | 堆(Heap) | BST |
|---|---|---|
| 是否有序 | ❌ 无序 | ✅ 有序 |
| 是否允许重复值 | ✅ | ❌ |
| 插入/删除时间复杂度 | ✅ O(log n) | ❌ 最坏 O(n) |
| 构建时间复杂度 | ✅ O(n)(优化) | ✅ O(n log n) |
| 遍历有序 | ❌(需排序) | ✅ 中序遍历即可 |
| 底层实现 | 数组 | 指针结构 |
| Java 实现 | PriorityQueue(默认 Max-Heap) |
TreeMap(基于红黑树) |
适用场景建议
- 使用 BST 的情况:
- 需要快速查找、插入、删除,并保持数据有序
- 支持范围查询、前驱后继查找等操作
- 使用 Heap 的情况:
- 仅需维护最大/最小值(如任务调度、优先队列)
- 构建时间敏感(可接受 O(n) 构建)
5. 总结
Heap 和 BST 是两种基础但非常重要的数据结构:
- BST 是有序结构,适合需要频繁查找、排序的场景
- Heap 是无序结构,适合维护最大/最小值,且插入删除效率稳定
- BST 可能退化为链表,需使用平衡树(如红黑树)保证性能
- Heap 用数组实现,构建效率高,但不支持快速查找
在实际开发中,根据具体需求选择合适的结构:
- 要排序、查范围 → BST(推荐 TreeMap)
- 要优先级调度、最大值维护 → Heap(推荐 PriorityQueue)
✅ Java 中的实现:
PriorityQueue:默认是 Max-HeapTreeMap:基于红黑树的平衡 BST
合理选择结构,可以显著提升程序性能与可维护性。