1. 引言
在计算机视觉领域,我们希望从图像中提取有价值的信息。这通常通过识别图像中的对象来实现,而图像分割(image segmentation)是实现这一目标的重要手段之一。
本文将解释图像分割的原理,并重点介绍两种主要的分割方法:实例分割(Instance Segmentation) 和 语义分割(Semantic Segmentation)。
2. 图像分割概述
在图像分割任务中,我们的目标是对图像中的每个像素进行分类。
属于同一类别的像素集合构成一个图像片段(segment)。通常,我们希望通过分割来识别图像中的对象,从而将图像的表示形式从像素值转换为类别标签。
图像分割的方法有很多,最简单的是阈值法(thresholding)。例如,在灰度图像中,我们可以通过设定一个阈值(如149),将像素值低于该值的归为前景,高于该值的归为背景:

图像分割在生物学中也有广泛应用。例如,在医学图像分析中,我们需要从组织样本中区分癌细胞和正常细胞。由于癌细胞的结构通常与正常细胞不同,图像中也会体现这种差异。通过分割技术识别出细胞后,可以进一步进行形态学分析。
图像分割主要分为两种类型:语义分割 和 实例分割。
3. 语义分割
在语义分割中,属于同一类别的所有对象共享同一个标签。
以自动驾驶场景为例,所有行人将被标记为“行人”,所有车辆将被标记为“车辆”,无论它们的数量和位置:

3.1. SegNet 简介
在语义分割中,深度学习方法表现最佳。SegNet 是其中一种经典方法,它是一种编码器-解码器结构的网络:
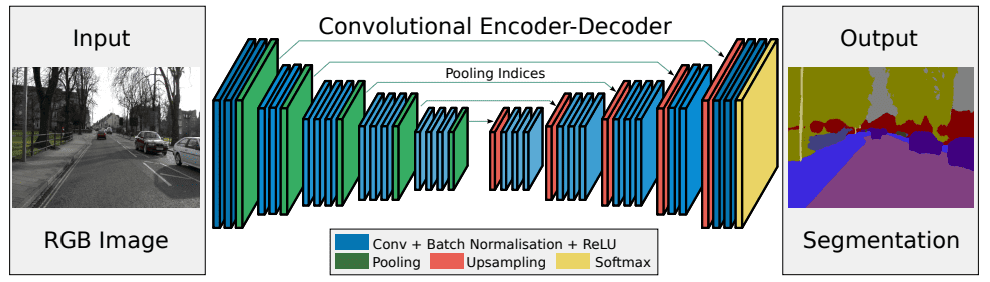
在编码阶段,SegNet 使用 13 层卷积网络对输入图像进行下采样,每层后接最大池化(max-pooling)。在池化过程中,它会记录每个池化窗口中最大值的位置(索引)。
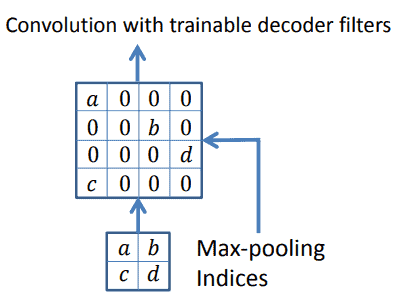
在解码阶段,SegNet 使用这些保存的索引对特征图进行上采样。它将最大值放回原来的位置,其余位置填充为 0,从而重建稀疏特征图:
最后,通过卷积操作将稀疏图转换为密集的特征图输出。
4. 实例分割
在实例分割中,每个检测到的对象都会被赋予唯一的标签。
当我们需要区分对象的个体数量或独立性时,通常使用实例分割。例如,在演唱会现场统计人数,就需要对每个观众进行独立识别。
同样以自动驾驶为例,语义分割中所有车辆共享一个标签,而在实例分割中,每个行人和每辆车都会被赋予不同的标签(通常用不同颜色表示):

4.1. Mask R-CNN 简介
Mask R-CNN 是当前最流行的实例分割方法之一,其工作流程分为多个阶段:
第一阶段是区域建议网络(Region Proposal Network, RPN),用于生成候选区域。
第二阶段对每个候选区域进行分类、边界框回归,并生成对应的二值掩码(mask):
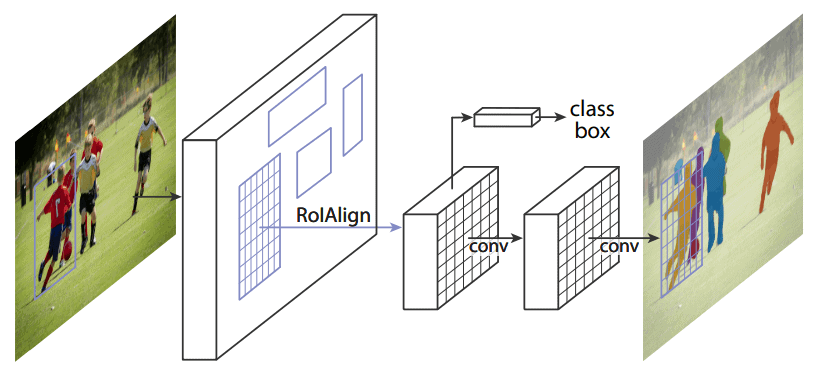
Mask R-CNN 的创新点在于,它在预测边界框的同时生成对象掩码,实现了对对象的精确分割。
5. 总结
图像分割是计算机视觉中的重要任务,广泛应用于医学图像分析、自动驾驶、智能机器人等多个领域。
在选择分割方法时,关键在于明确应用场景:
✅ 如果你需要统计图像中对象的数量,或者区分同一类别中的不同个体,应选择实例分割
✅ 如果你只需要对图像中的对象进行类别划分,而不需要区分个体,应选择语义分割
选择合适的分割方法,不仅能提升模型的精度,也能更高效地满足实际业务需求。