1. 概述
在本教程中,我们将讨论如何处理大型图像以训练卷积神经网络(CNNs)。首先,我们会介绍 CNN 的基本概念以及使用大型图像作为输入时所面临的挑战。随后,我们会介绍三种常见的解决方案:调整图像尺寸、扩展模型结构、分批次处理图像。
2. 卷积神经网络(CNN)简介
卷积神经网络(CNN)是深度学习中最成功的架构之一,它通常由一个或多个卷积层组成,后接若干全连接层。关于卷积层和全连接层的区别,我们曾在另一篇文章中做过详细说明。
CNN 最常用于图像分类、图像分割、图像重建等视觉任务。近年来,它也被应用在语音识别和自然语言处理等非视觉任务中。本文我们聚焦于 CNN 在视觉任务中的应用,即输入为图像的场景。
3. 大型图像带来的问题
CNN 的一个重要特性是输入图像的尺寸必须固定。
这是因为 CNN 的参数数量与输入尺寸直接相关。在训练过程中,参数数量必须保持稳定,因此输入尺寸也必须保持不变。
此外,在计算机视觉中,常见的做法是使用预训练好的 CNN 模型进行迁移学习。这些模型是在特定输入尺寸下训练得到的。如果我们直接使用这些模型,就必须将输入图像调整为相同的尺寸。
这就带来一个问题:我们手头的图像尺寸可能与模型要求的输入尺寸不一致。下面,我们介绍三种常用的解决方案。
4. 调整图像尺寸(Resize)
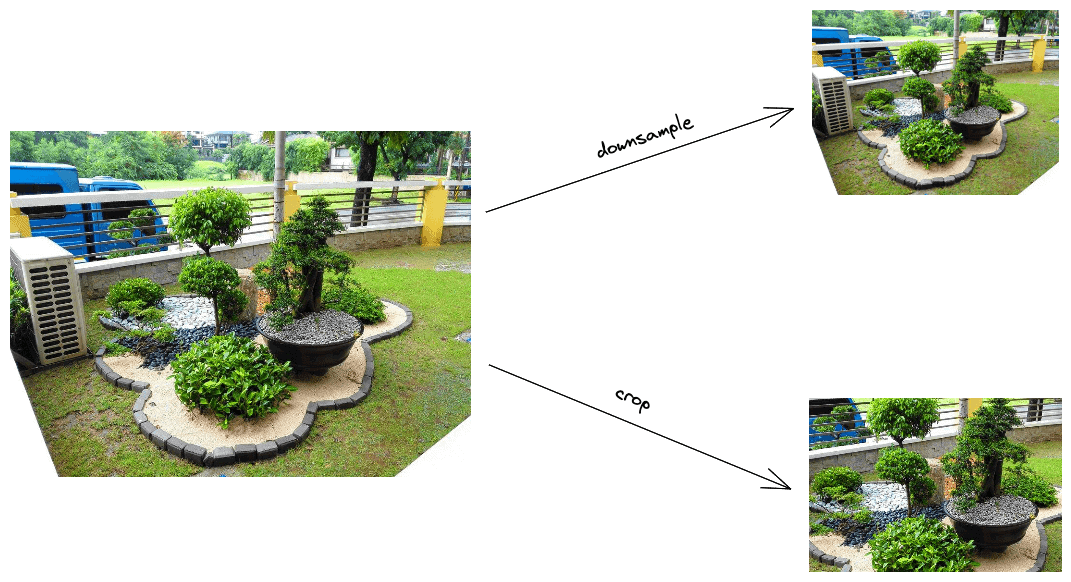
最直接的解决办法是将图像调整为模型所需的输入尺寸。 通常有两种方式:下采样(Downsample)和裁剪(Crop)。
4.1 下采样图像
下采样的目标是在保持图像二维结构的前提下降低其空间分辨率。 最简单的做法是跳过部分像素。例如,将图像尺寸缩小为原来的一半,可以每隔一个像素取一个。
但这种方式可能会导致混叠(aliasing)问题,即图像中的高频信息(如明暗交替区域)被错误地转化为低频信息(如均匀明暗)。
一种更优的下采样方式是使用平均法(Averaging),即把 $2 \times 2$ 的像素区域平均为一个像素,从而避免混叠。
4.2 裁剪图像
如果不需要保留图像的全部内容,可以将图像裁剪为所需尺寸。 通常我们从图像中心区域裁剪,因为中心内容往往更重要。
下图展示了这两种方法的示意图:
5. 扩展模型结构
前面我们是通过调整图像尺寸来适应模型,另一种思路是保持图像尺寸不变,调整模型结构。 由于卷积层本身具有降维能力,我们可以在原有 CNN 结构前添加额外的卷积层,使得模型能够处理更大的输入。
如下图所示,我们通过添加一个卷积层,使得 CNN 能够处理更大的图像输入。该卷积层将输入尺寸缩小了 4 倍:
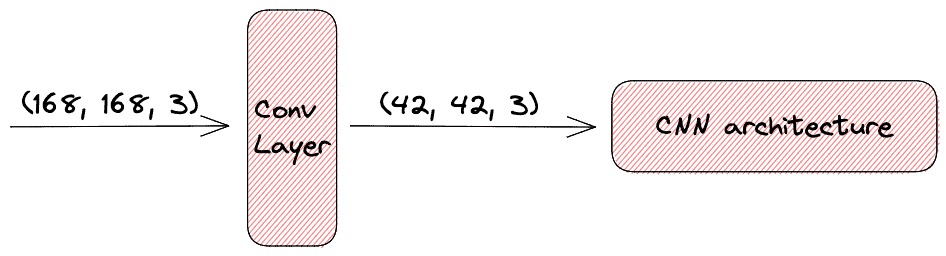
6. 分批次处理图像(Batch Processing)
第三种处理大型图像的方法是将其分批次进行处理,以降低内存压力。 当图像尺寸较大时,整个训练集可能无法一次性加载进内存。
此时可以使用 Mini-Batch Gradient Descent,每次处理一小批图像。我们只需根据显存容量合理设置 batch size,即可有效训练大型图像。
✅ 优点:减少内存压力
✅ 优点:适合大规模数据集
❌ 缺点:训练时间可能增加
⚠️ 踩坑提示:batch size 设置过大会导致 OOM(内存溢出)
7. 总结
本文介绍了三种处理大型图像以训练 CNN 的方法:
- 调整图像尺寸:包括下采样和裁剪,适用于大多数预训练模型
- 扩展模型结构:通过添加卷积层来适配大图像,适合有模型修改权限的场景
- 分批次处理:缓解内存压力,适合大规模图像训练
根据实际场景和资源限制,选择合适的方法可以有效提升模型训练效率和稳定性。