1. 简介
Jump Search 是一种适用于有序数组或链表的搜索算法。它在链表搜索中表现尤为出色,但同样适用于数组。其核心思想是通过跳跃式地检查元素,缩小查找范围,从而提高搜索效率。
与 Binary Search 不同,Jump Search 不需要频繁回溯(backtracking),这使得它在处理链表、大文件或流式数据时具有优势。
2. 问题背景
我们面对的典型问题是:
- 给定一个有序数组或链表
x,包含n个元素。 - 给定一个目标值
z,要求找出其在x中的索引(或对应元素)。
数组 vs 链表
| 特性 | 数组 | 链表 |
|---|---|---|
| 随机访问 | ✅ O(1) |
❌ O(i) |
| 回溯操作 | ✅ | ❌ |
| Binary Search 适用性 | ✅ | ⚠️ 不推荐 |
| Jump Search 适用性 | ✅ | ✅ 推荐 |
由于链表无法随机访问,Binary Search 的效率会大打折扣。Jump Search 则通过跳跃式查找,减少指针遍历次数,更适合链表结构。
3. Jump Search 原理
核心思想
将有序链表划分为多个大小为 m 的子块:
x[1:m], x[m+1:2m], ..., x[(⌊n/m⌋ - 1)m : n]
算法从头开始,每次跳 m 步,直到找到一个子块,其起始和结束元素之间包含目标值 z,即:
x[j * m + 1] ≤ z ≤ x[(j + 1) * m]
然后在该子块中进行线性查找。
示例图解
假设 m = 5,查找过程如下图所示:
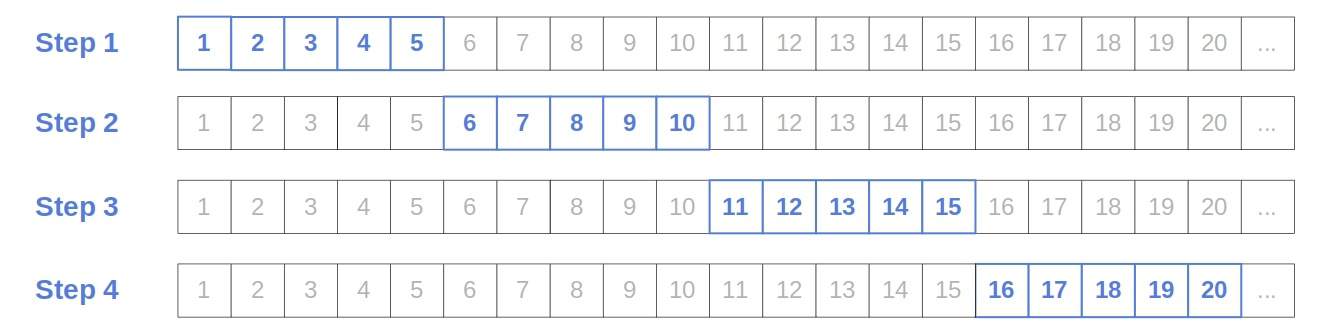
4. 算法实现(伪代码)
algorithm JumpSearch(x, z, m):
// x: 有序链表
// z: 目标值
// m: 跳跃步长
left <- x.head
right <- follow m pointers from left
while right != NULL and not (left.key <= z < right.key):
left <- right.next
right <- follow m pointers from right
if right == NULL:
return "failure"
else:
while left != right.next and left.key != z:
left <- left.next
if left == right.next:
return "failure"
else:
return left.item
5. 时间复杂度分析
设链表长度为 n,跳跃步长为 m:
- 最坏情况下需要检查
⌈n/m⌉个子块。 - 每个子块最多检查
m个元素。
总比较次数为:
O(n/m + m)
要使该表达式最小,取 m = √n,此时时间复杂度为:
✅ **O(√n)**(比较次数)
⚠️ 但若考虑链表遍历操作(指针跳转),最坏情况下仍为 O(n)。
6. 在数组中的应用
虽然 Jump Search 更适合链表,但它同样适用于数组。在以下场景中,Jump Search 比 Binary Search 更优:
- 数组过大,无法完全载入内存
- 数组为流式数据,只能顺序读取
- 访问前一个元素代价高昂(如网络传输、磁盘读取)
示例场景
- 从磁盘读取大文件时,跳跃式访问比来回查找更高效。
- 从网络下载数据时,Binary Search 的回溯操作会导致多次请求,效率低下。
7. 总结
Jump Search 是一种适用于有序链表和数组的搜索算法,其优势在于:
✅ 无需回溯操作
✅ 适用于链表、大文件、流式数据
✅ 时间复杂度为 O(√n)(比较次数)
✅ 实现简单,适合实际工程中使用
| 算法 | 时间复杂度(比较) | 是否适合链表 | 是否适合大文件 |
|---|---|---|---|
| Binary Search | O(log n) |
❌ | ⚠️ |
| Linear Search | O(n) |
✅ | ❌ |
| Jump Search | O(√n) |
✅ | ✅ |
⚠️ 踩坑提醒:选择跳跃步长
m很关键。一般建议设为√n,否则可能影响性能。