1. 点到分布的距离:马氏距离简介
马氏距离(Mahalanobis Distance)用于衡量一个点与一个  维空间中分布之间的距离。它在识别异常值方面非常有用,也可以在数据稀缺的情况下用于分类任务。
维空间中分布之间的距离。它在识别异常值方面非常有用,也可以在数据稀缺的情况下用于分类任务。
在本文中,我们将了解它为何如此实用,并分析为何在某些情况下它比欧氏距离(Euclidean Distance)更优。
2. 点到点 vs 点到分布
我们先从两个点之间的距离谈起。假设在 维空间中有两个点  和
和  ,要衡量它们之间的总体距离,我们需要考虑它们在每个维度上的差异。
,要衡量它们之间的总体距离,我们需要考虑它们在每个维度上的差异。
因此,欧氏距离的公式如下:
![[d(p, q)=\sqrt{\left(p_{1}-q_{1}\right) ^2+\left(p_{2}-q_{2}\right) ^2+\cdots+\left(p_{n}-q_{n}\right)^{2}}]](/wp-content/ql-cache/quicklatex.com-db328e67b83545e98ade99a8bc6042f4_l3.svg "Rendered by QuickLaTeX.com")
欧氏距离是统计学和机器学习中最基础、最常用的度量方式。它适用于点与点之间的比较。但当我们需要比较一个点与一个分布之间的距离时,情况就变得复杂了。
2.1. 均值与标准差的距离
通常,要衡量一个点与一个分布之间的距离,我们可以先将分布简化为一个点,即它的均值(mean)。然后我们可以用标准差(standard deviation)来衡量该点与这个均值之间的距离。
在一维空间中,这方法是可行的。但在多维空间中,变量之间可能存在相关性(correlation),这就不能简单地使用欧氏距离了。
3. 变量相关性带来的问题
欧氏距离默认每个维度权重相等,相当于假设变量之间是独立的、互不相关的。 如果数据确实满足这一前提,那使用欧氏距离没有问题。
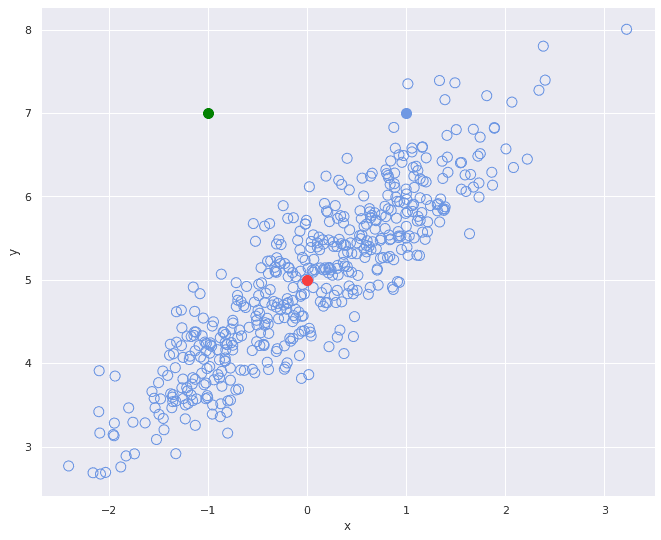
但在实际数据中,变量之间往往存在相关性。考虑下面两个散点图:
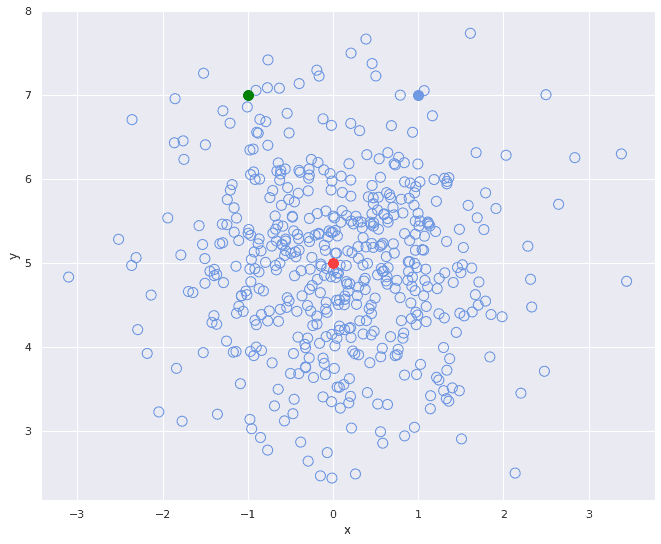
- 第一个图中变量不相关,
 和
和  之间无明显关联。
之间无明显关联。 - 第二个图中变量呈正相关, 增大时, 也相应增大。
我们来看三个点:
- 红色点代表分布的中心(均值)
- 绿色和蓝色点分别与红色点在欧氏距离上等距
但观察第二张图,绿色点在分布中的位置明显“更远”,这说明:
- 欧氏距离没有考虑变量之间的相关性
- 它忽略了分布的整体结构
4. 马氏距离的定义与作用
马氏距离正是为了解决变量相关性带来的偏差而提出的。它不仅考虑了变量的分布,还通过协方差矩阵(covariance matrix)对变量进行归一化处理。其公式如下:
![[d_{M}(\vec{p}, \mu ; Q)=\sqrt{(\vec{p}- \mu)^{\top} S^{-1}(\vec{p}- \mu)}]](/wp-content/ql-cache/quicklatex.com-fbacb27589ae0461c6e5f291dc76d16b_l3.svg "Rendered by QuickLaTeX.com")
其中:
 是数据分布
是数据分布- 是待测点
 是分布的均值向量
是分布的均值向量 是协方差矩阵的逆
是协方差矩阵的逆
4.1. 数值示例
我们以图中三个点为例:
- 红点 R:

- 绿点 G:
- 蓝点 B:
使用两个不同的协方差矩阵:

欧氏距离计算


马氏距离计算


可以看到,在变量相关的情况下,马氏距离显著增大,更准确地反映了点与分布之间的“实际”距离。
4.2. 直观理解
马氏距离的核心在于协方差矩阵的逆 。这个逆矩阵的作用类似于“标准化”操作,它将变量按其协方差关系进行归一化。
我们可以将公式理解为:
![[d_{M}(\vec{x}, \vec{y}; Q)=\|W(\vec{x}-\vec{y})\|]](/wp-content/ql-cache/quicklatex.com-0a34a7abaef4348a5cd20146bdaa02c4_l3.svg "Rendered by QuickLaTeX.com")
其中  是对 的分解结果。
是对 的分解结果。
换句话说,马氏距离可以看作是经过线性变换后的欧氏距离。这种变换使变量具有单位方差,并去除相关性,从而更公平地衡量点与分布之间的距离。
5. 总结
本文我们介绍了马氏距离的基本概念、与欧氏距离的差异,并通过数值示例说明了其优势。马氏距离之所以优于欧氏距离,关键在于:
✅ 考虑变量之间的相关性
✅ 对变量进行标准化处理
✅ 更准确地反映点与分布之间的“真实”距离
在实际应用中,尤其是在异常检测、聚类分析、分类任务中,当数据维度较高且变量间存在相关性时,使用马氏距离能显著提升模型的准确性和鲁棒性。