1. 引言
多臂老虎机(K-Armed Bandit)是强化学习中的一个经典问题模型,它抽象了探索(Exploration)与利用(Exploitation)之间的权衡问题。本文将带你了解:
- 多臂老虎机的基本设定
- 探索与利用的博弈
- 常见的策略选择方法
- 如何评估策略效果(Regret 分析)
2. 强化学习与多臂老虎机
强化学习中,智能体(Agent)通过与环境交互,学习如何做出最优决策以最大化长期奖励。而多臂老虎机是强化学习的一个简化模型,它只包含一个状态,只有多个动作(即“臂”)可供选择。
比如,想象你面前有 k 台老虎机,每台都有一个未知的奖励分布。你的任务是尽可能多地获得奖励。这正是多臂老虎机问题的核心。
多臂老虎机模型如下图所示:
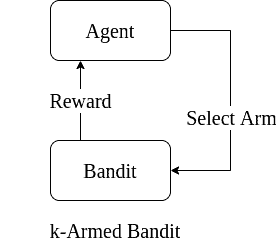
每一轮你选择一个“臂”拉动,获得一个即时奖励。这个奖励来自该臂的固定但未知的概率分布。
2.1 上下文多臂老虎机(Contextual Bandits)
为了更贴近现实问题,我们可以引入“上下文”(context),即智能体在做出动作选择时,会考虑当前的状态或环境信息。例如,广告推荐系统中,用户特征就是上下文。
如下图所示,上下文帮助智能体做出更精准的决策:
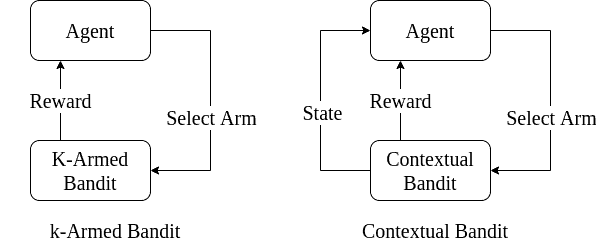
但即使如此,上下文老虎机仍不能很好地模拟需要延迟奖励的复杂场景(如游戏、路径规划等)。这时就需要更复杂的强化学习模型。
3. 探索 vs 利用
多臂老虎机的核心在于如何在探索未知动作与利用已知高回报动作之间取得平衡。
3.1 探索(Exploration)
探索指的是尝试当前未知或表现不明确的动作,以获取更多信息。比如,你不知道某台老虎机的中奖率,就尝试多拉几次。
3.2 利用(Exploitation)
利用指的是根据已有经验,选择当前已知收益最高的动作。比如,你已经知道某台机器回报高,就一直拉它。
3.3 探索与利用的权衡(Trade-off)
- 如果只探索,你会错过很多高回报机会;
- 如果只利用,你可能陷入局部最优,错过更好的选择。
因此,如何在探索与利用之间取得平衡,是解决多臂老虎机问题的关键。
下图展示了探索初期与后期的预期奖励估计情况:
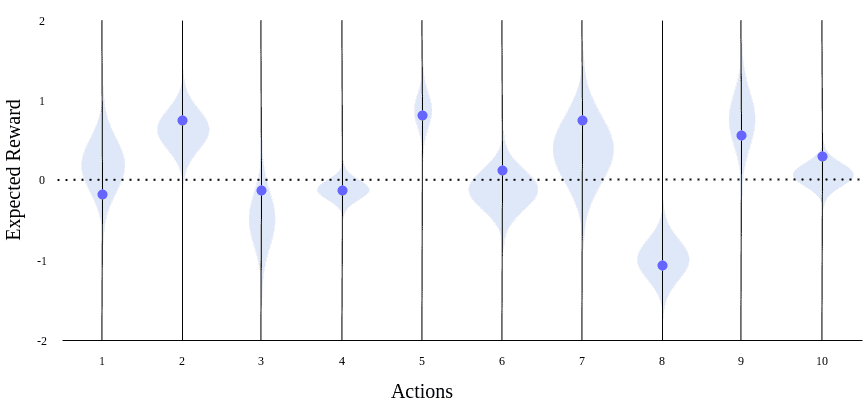
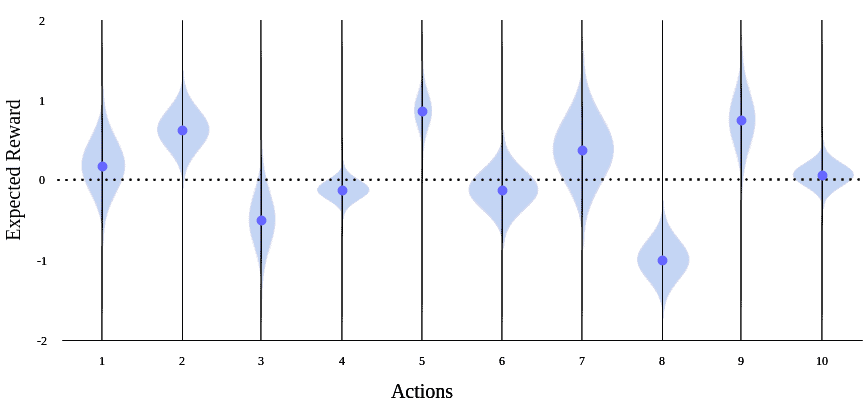
4. 动作选择策略
4.1 探索优先(Explore-First)
- 策略:先对所有臂进行若干次尝试,评估其平均奖励;
- 然后:选择表现最好的臂进行后续利用。
✅ 优点:利用阶段无悔; ❌ 缺点:探索阶段效率低,可能浪费很多机会。
4.2 ε-Greedy(Epsilon-Greedy)
- 策略:以 ε 概率随机选择臂,以 1-ε 概率选择当前最优臂;
- 示例代码(Python):
import random
def choose_action(q_values, epsilon):
if random.random() < epsilon:
return random.choice(range(len(q_values))) # 探索
else:
return max(range(len(q_values)), key=lambda i: q_values[i]) # 利用
✅ 优点:简单易实现; ❌ 缺点:探索是均匀的,不区分好坏。
4.3 ε-Decreasing(衰减 ε-Greedy)
- 策略:开始时 ε 较大,探索多;随着学习进行,ε 逐渐减小;
- 实现方式:每次更新 ε = ε * decay(如 decay = 0.95)。
✅ 优点:前期探索多,后期聚焦; ❌ 缺点:衰减策略需要调参。
4.4 Softmax(Boltzmann 探索)
- 策略:根据每个臂的期望奖励计算选择概率,奖励越高概率越大;
- 公式:$$P(a) = \frac{e^{Q(a)/\tau}}{\sum_b e^{Q(b)/\tau}}$$
其中 τ 是温度参数,控制探索程度。
✅ 优点:探索有优先级,不是均匀的; ❌ 缺点:仍无法保证最优悔值。
4.5 Pursuit Methods(追踪策略)
- 策略:维护每个臂的偏好概率,持续向当前最优臂靠拢;
- 实现方式:每次更新偏好概率,使最优臂概率增加,其他减少。
✅ 优点:动态调整; ❌ 缺点:实现稍复杂。
4.6 Upper Confidence Bound(UCB)
- 策略:根据置信区间上界选择臂;
- 公式:$$A_t = \arg\max_a \left(Q_t(a) + c \sqrt{\frac{\ln t}{N_t(a)}}\right)$$
其中:
- $Q_t(a)$:当前估计奖励;
- $N_t(a)$:该臂被选中的次数;
- $c$:探索参数。
✅ 优点:理论上有界最小悔; ❌ 缺点:实现略复杂。
4.7 Thompson Sampling(汤普森抽样)
- 策略:基于贝叶斯推理,为每个臂维护一个概率分布;
- 实现方式:每次从分布中抽样,选择抽样值最大的臂。
✅ 优点:适合先验知识; ❌ 缺点:依赖分布假设。
5. 策略对比与悔值分析
我们可以通过“悔值”(Regret)来评估策略表现。悔值定义为:
每次选择的奖励与当前最优奖励的差值之和。
下图展示了不同策略的悔值上限对比:
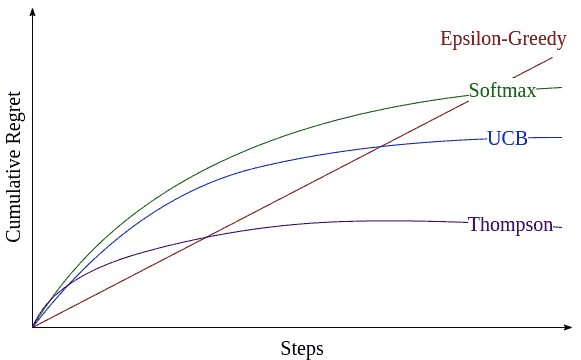
5.1 各策略表现总结
| 策略 | 探索效率 | 利用效率 | 悔值表现 | 适用场景 |
|---|---|---|---|---|
| ε-Greedy | 中等 | 中等 | 中等 | 快速实现 |
| ε-Decreasing | 高 | 高 | 好 | 逐步聚焦 |
| Softmax | 高 | 高 | 中等 | 有优先级 |
| UCB | 高 | 高 | 最佳(理论) | 数据稳定 |
| Thompson Sampling | 高 | 高 | 稳定 | 有先验信息 |
6. 总结
多臂老虎机问题虽然简化了强化学习的复杂性,但其核心思想——探索与利用的平衡——贯穿整个强化学习领域。本文介绍了以下内容:
- 多臂老虎机的基本设定与强化学习的关系;
- 探索与利用的含义及其权衡;
- 常见策略及其优缺点;
- 如何通过悔值分析评估策略效果。
✅ 建议:实际应用中,优先考虑 UCB 或 Thompson Sampling,它们在理论上和实践中表现都较优。对于快速实现,ε-Greedy 是一个不错的选择。