1. 引言
在本教程中,我们将探讨机器学习中常见的各种偏见(Bias)。这有助于我们理解偏见的含义,以及为何要避免它们。
我们还将学习偏见是如何进入机器学习应用的,更重要的是,如何识别、避免和纠正这些偏见。
2. 机器学习的应用
本教程假设读者对机器学习算法及其应用开发流程有一定了解。但在偏见的语境下,了解机器学习的实际应用场景尤为重要,这有助于我们理解偏见在实际应用中可能带来的影响。
机器学习是人工智能(Artificial Intelligence, AI)领域的一个分支。人工智能旨在构建能够执行通常需要人类智能才能完成任务的智能系统。而机器学习则是研究通过经验与数据自动提升性能的算法:
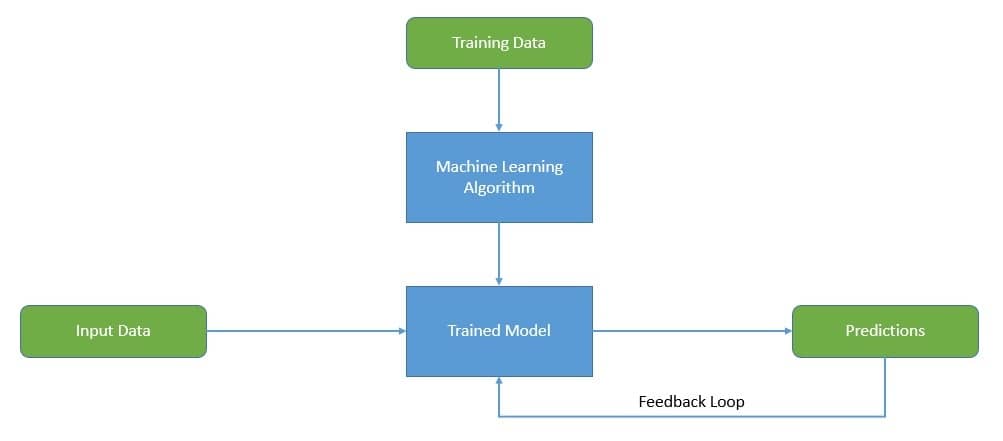
机器学习本身是一个广泛的领域,可分为监督学习、无监督学习、半监督学习、强化学习等多种类型。其中也包括流行的神经网络和深度学习方向。不过这些内容不在本教程的讨论范围内。
有趣的是,人工智能和机器学习其实已有较长历史。但直到近几十年,随着云计算的普及和大数据的爆发式增长,才真正从学术研究走向了实际应用。
如今,机器学习已广泛应用于各行各业。我们越来越多地将决策权交给这些算法。例如,用机器学习在公共场所识别人脸、筛选求职者、审批贷款等。
3. 什么是偏见,我们为何要关注它?
在深入之前,我们需要明确“偏见”的含义。偏见是指对某个人或群体存在倾向性或歧视性的看法。 在机器学习中,当算法系统性地输出带有偏见的结果时,就出现了偏见。
这在机器学习中为何会发生?如前所述,机器学习算法主要依赖于训练数据的质量、客观性和数量。如果输入数据本身存在偏见,那么输出结果也很可能带有偏见。
但这并不是机器学习应用中偏见的唯一来源。在构建机器学习应用的过程中,还有多个环节可能引入偏见,我们将在下一节详细讨论。我们需要理解的是:为何我们要关心这些偏见?
以下是一些典型的例子:

不难看出,当我们部署带有偏见的算法来解决现实问题时,可能会带来意想不到的后果。例如,人脸识别系统可能表现出种族歧视,贷款评估系统可能带有性别偏见。 这些都会带来严重的后果。
偏见还可能导致应用在不同场景下失效。例如,如果我们训练一个语音助手时仅使用某地区人群的声音,那么在其他地区使用时,由于语调、方言、文化差异等问题,其表现可能大打折扣。
当然,偏见不一定总是这么严重,但其影响不容忽视。
4. 机器学习中的偏见类型
我们已经简要了解了偏见是如何进入机器学习应用的。在构建应用的过程中,我们需要收集数据、处理数据,并将其输入模型进行训练。在这个过程中,任何环节都可能无意中引入偏见,偏见的来源也多种多样:
要想高效应对偏见,我们首先需要了解偏见是如何产生的。大致来说,机器学习算法中的偏见可以分为以下几类:
✅ 预设立场偏见 (Prejudicial Bias)
偏见往往源于设计者本身。我们作为社会中的一员,可能有意或无意地带有根深蒂固的偏见。这种偏见会影响机器学习应用的每个阶段,是最复杂也是最难纠正的偏见来源。
✅ 采样偏见 (Sampling Bias)
数据收集过程中,我们可能有意或无意地过度采样某一类群体,导致模型预测偏向该群体。例如,采集数据时过多地使用某一性别的样本。
✅ 算法偏见 (Algorithm Bias)
在选择算法时,不同的算法适用于不同的场景。例如线性回归、支持向量机、决策树等。错误选择算法可能导致预测结果出现偏见。
✅ 确认偏见 (Confirmation Bias)
在训练和评估模型时,我们可能会倾向于保留支持我们预期的数据,排除与我们预期不符的数据。这会导致数据集的偏见,从而影响模型预测。
以上只是偏见的主要来源,并非全部。但如果我们能有效应对这些来源,就能显著提升应用的公平性。
5. 如何识别和衡量偏见
在前面的章节中,我们了解了偏见的定义及其进入机器学习应用的方式。我们也很清楚为何要尽可能地消除偏见。但在尝试减少或消除偏见之前,识别和衡量偏见是非常关键的一步。
机器学习模型的输出机制通常难以理解。在大多数实际应用中,我们将其视为一个“黑盒”:数据输入,预测输出:
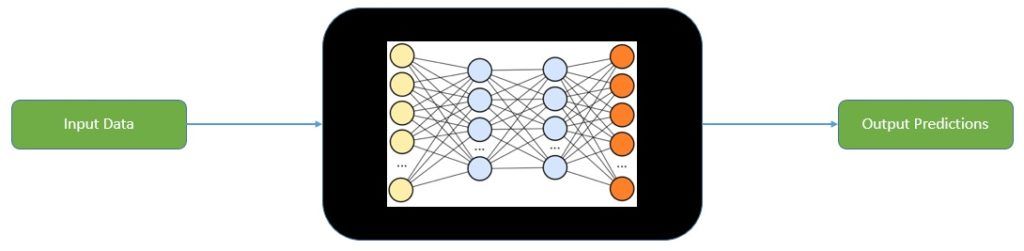
对于一些简单的模型,如线性回归,我们还能大致理解其预测逻辑。但对于复杂的模型(如神经网络),理解其内部机制则困难得多。
这使得我们很难判断一个机器学习应用为何会产生偏见。因此,关键在于持续监控大量预测结果中的偏见迹象。每个组织都应明确在其业务范围内哪些行为或结果构成偏见。 例如,招聘公司应定期评估是否在性别、种族、民族等方面存在偏好倾向。
6. 如何预防机器学习中的偏见
最后,我们来讨论如何应对偏见。如前所述,机器学习本质上是一个启发式过程。虽然我们可以部分解释其行为,但无法完全理解。这也使得偏见的检测和消除变得复杂。
尽管如此,偏见问题在机器学习中已有数十年历史,我们也发展出了一些最佳实践来尽可能避免偏见。关键在于组织层面是否建立了一套系统性的应对机制:
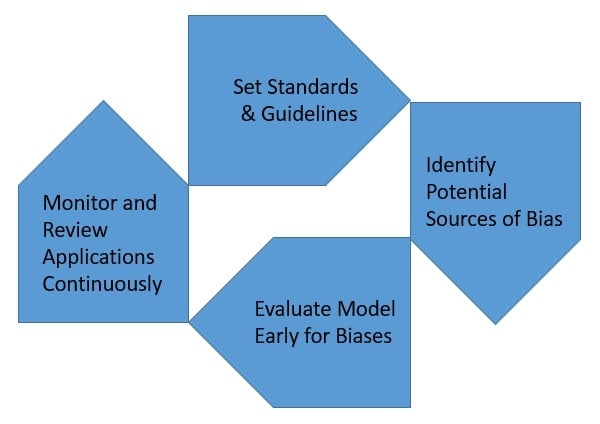
✅ 设定标准与指导方针
处理偏见的第一步是认真对待它。组织应建立明确的标准和指导方针,用于识别潜在偏见及其应对方式,并定期更新。
✅ 识别潜在偏见来源
数据是模型预测的基础,因此我们必须在数据收集阶段就识别可能的偏见来源,如设计者偏见、测量误差、样本偏差等。
✅ 早期评估模型偏见
在开发过程中,我们通常只关注准确率、精确率等性能指标。其实,偏见也应被视为一个关键的性能指标,越早发现越容易纠正。
✅ 持续监控与评估
大多数模型是基于固定数据训练的,但部署后实际数据会随时间变化。模型也会持续学习新数据。因此,在运行期间持续监控偏见表现非常重要。
7. 与“负责任的人工智能”的关系
如前所述,机器学习是人工智能的一部分。AI领域中的技术常用于构建智能和自主系统。因此,偏见问题不仅限于机器学习,整个AI领域都面临越来越多的伦理和法律挑战。
在此背景下,政府、大型组织和公民社会正在推动相关方承担更多责任。这催生了一个治理框架,称为“负责任的人工智能(Responsible AI)”,旨在开发公平、可信的AI应用。
当我们提到人工智能时,通常指的就是机器学习。由于机器学习的普及和广泛应用,负责任的人工智能框架也主要围绕机器学习的透明性和民主化展开。
目前,推动这一治理框架的责任主要在组织层面。 大型AI应用公司已公开其负责任AI政策,并采取多项措施确保其公平性。但目前在组织之间仍缺乏统一标准。
8. 支持公平AI的工具
随着我们越来越重视AI中的公平性,一些开源工具也应运而生,帮助我们在这方面做出改进。在遵循最佳实践开发完应用后,我们可以使用这些工具来评估其公平性表现。
Google 的 PAIR 团队开发了一个名为 What-If Tool 的工具,它可以帮助开发者可视化五种类型的公平性指标,并提供按钮按不同公平标准排序数据。
另一个可用工具是 IBM Research 提供的 AI Fairness 360 工具包。这是一个可扩展的开源工具集,支持在整个AI应用生命周期中检测、报告和减轻歧视与偏见。它提供了一整套Python包,包含丰富的数据集和模型偏见检测指标。
9. 总结
在本文中,我们探讨了机器学习应用中的偏见问题。我们分析了偏见的来源,以及如何识别和衡量它们。我们还讨论了如何通过最佳实践和工具来应对偏见,以减少或消除其影响。最重要的是,我们认识到偏见问题在AI和机器学习中的重要性,以及它可能带来的深远影响。
✅ 偏见可能源于数据、算法、设计者甚至评估过程。
✅ 持续监控和评估是应对偏见的关键。
✅ 负责任的人工智能框架正在推动AI公平性的发展。
✅ 使用开源工具可以帮助我们更系统地检测和纠正偏见。
在构建AI系统时,公平性不应被忽视,否则可能导致严重的社会和伦理问题。