1. 概述
在机器学习中,归纳偏置(Inductive Bias) 是模型在学习过程中所依赖的先验知识或结构假设。它决定了模型如何从有限的训练数据中泛化到未见过的新数据。
归纳偏置强弱直接影响模型的泛化能力。强归纳偏置有助于模型更快收敛并找到全局最优解;而弱归纳偏置可能导致模型陷入局部最优,且对初始状态敏感。
本文将从传统机器学习和深度学习两个角度,深入解析归纳偏置的类型与表现形式。
2. 定义
归纳偏置 是指我们在建模时对数据所做的假设,以及模型结构所隐含的先验知识。
这些假设可能包括:
- 数据点之间存在某种关系(如线性、局部性、顺序性)
- 使用特定类型的函数来拟合数据
- 网络结构限制了信息的传递方式
归纳偏置可以分为两大类:
✅ 关系型归纳偏置(Relational):描述模型中实体之间的结构关系
✅ 非关系型归纳偏置(Non-relational):指对模型行为施加的额外约束(如正则化、归一化)
3. 传统机器学习中的归纳偏置
不同的传统机器学习算法,其归纳偏置各不相同。
3.1 贝叶斯模型(Bayesian Models)
- 归纳偏置:先验分布和变量间的条件独立性假设
- 贝叶斯网络通过图结构表达变量之间的因果关系
- 条件独立性简化了联合概率分布的建模
3.2 K近邻算法(k-NN)
- 归纳偏置:相似的数据点在空间中应彼此靠近
- 假设类别标签在局部区域具有连续性
- 对距离度量方式敏感(如欧氏距离、曼哈顿距离)
3.3 线性回归(Linear Regression)
- 归纳偏置:目标变量 Y 与特征 X 之间存在线性关系
- 示例代码如下:
// 线性回归模型伪代码
public class LinearRegression {
double[] weights;
double bias;
public double predict(double[] x) {
double y = bias;
for (int i = 0; i < x.length; i++) {
y += weights[i] * x[i];
}
return y;
}
}
- 缺点:无法建模非线性关系
3.4 逻辑回归(Logistic Regression)
- 归纳偏置:类别之间存在一个超平面可分界
- 假设数据线性可分(或近似可分)
- 实际中若数据不可分,模型效果会大打折扣
4. 深度学习中的关系型归纳偏置
这类偏置主要体现在网络结构设计上,决定了模型中各部分之间的交互方式。
4.1 弱关系(Weak Relation)
- 典型结构:全连接层(Fully Connected Layer)
- 各神经元之间无明确结构依赖
- 适用于输入特征之间无明显空间或时序关系
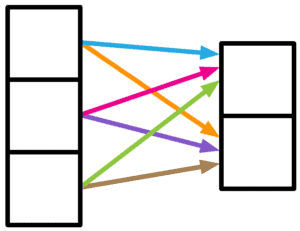
4.2 局部性(Locality)
- 典型结构:卷积层(Convolutional Layer)
- 假设图像中相邻像素之间存在局部依赖关系
- 通过局部感受野逐步提取全局特征
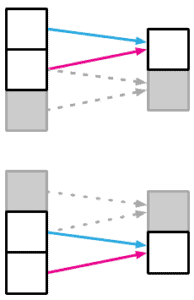
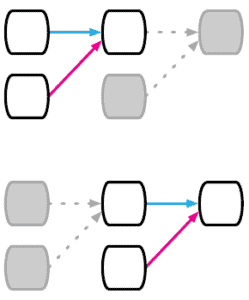
4.3 顺序性(Sequential Relation)
- 典型结构:循环神经网络(RNN、LSTM、GRU)
- 假设数据具有时间或顺序依赖性
- 适用于自然语言、时间序列等任务
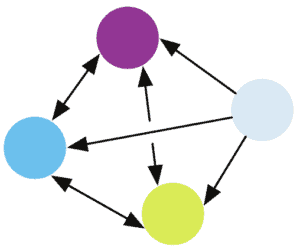
4.4 任意关系(Arbitrary Relation)
- 典型结构:图神经网络(GNN)
- 假设实体之间存在任意图结构关系
- 适用于社交网络、知识图谱等非结构化数据
5. 深度学习中的非关系型归纳偏置
这些偏置不直接描述实体之间的关系,而是对模型行为施加额外约束,以提升泛化能力。
5.1 非线性激活函数(Non-linear Activation)
- 常用函数:ReLU、Sigmoid、Tanh
- 作用:引入非线性,使模型能拟合复杂函数
- 没有非线性激活,多层网络等价于单层网络
5.2 Dropout
- 作用:防止过拟合
- 原理:训练时随机关闭部分神经元,强制网络学习冗余表示
- 示例代码(PyTorch):
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 10)
)
5.3 权重衰减(Weight Decay)
- 又称 L2 正则化
- 限制权重大小,防止模型过于复杂
- L1 正则化倾向于产生稀疏权重
5.4 归一化(Normalization)
- 常见方法:BatchNorm、LayerNorm、InstanceNorm
- 作用:缓解内部协变量偏移(Internal Covariate Shift)
- 提高训练稳定性与速度
5.5 数据增强(Data Augmentation)
- 归纳偏置:输入数据的某些变换不影响输出
- 常用于图像、文本任务
- 示例:图像旋转、裁剪、加噪声;文本同义词替换等
5.6 优化算法(Optimization Algorithm)
- 不同优化器(SGD、Adam、RMSProp)会导致不同收敛路径
- 学习率、动量等参数影响模型最终泛化能力
6. 总结
归纳偏置是机器学习模型泛化能力的核心机制之一,它决定了模型如何从有限数据中学习并推广到新样本。
✅ 关系型归纳偏置 通过网络结构体现实体间的关系
✅ 非关系型归纳偏置 通过正则化、归一化、激活函数等方式约束模型行为
合理设计归纳偏置,是提升模型性能、减少过拟合、加快训练速度的关键。在实际开发中,我们应根据任务特性选择合适的模型结构和约束策略,以达到最佳泛化效果。