1. 引言
在本教程中,我们将探讨人工智能(AI)、机器学习(ML)、统计学(Statistics) 与数据挖掘(Data Mining) 之间的区别。
这些领域之间存在大量重叠,且没有明确的界限。多年来,研究人员和工程师对此问题提出了不同甚至相互冲突的观点,因此,目前并没有统一的共识。
2. 人工智能(Artificial Intelligence)
人工智能的核心目标是构建能够自主解决问题的智能代理(Agent),仿佛它们拥有类似人类的内在智能。AI 的丰富性来源于对“智能代理”定义和构建方式的多样性。
例如:
- 手写识别软件是一种 AI 代理,它能自动读取手写文本并将其转换为数字格式,无需人工干预。
- 国际象棋程序通过搜索对手可能的走法,找出最佳走法序列。它的“智能”不是来自数据,而是来自搜索算法(如 Minimax 算法)。
✅ AI 的核心在于构建理性代理(Rational Agent),即始终在已知条件下选择最优选项。比如:
- 判断手写内容最可能代表的单词
- 找出最快赢得棋局的走法
- 设计等待时间最短的航班调度方案
3. 机器学习(Machine Learning)
机器学习是人工智能的一个子领域。简而言之,ML 是通过从数据中自动学习规则,用于预测新数据的技术。
举个例子:我们想根据公寓的特征(如面积、房间数、楼层)预测售价。我们拥有大量公寓的历史数据,从中自动学习出预测规则,这就是 ML 的任务。
这些规则可以是:
- 决策树
- 线性回归方程
- 神经网络
我们不手动编写这些规则,而是让算法自动提取。
✅ ML 是 AI 的一部分,它通过数据构建智能代理。例如,我们可以限制模型为以下形式的线性方程:
$$ \theta_0 + \theta_1 \cdot \text{size} + \theta_2 \cdot \text{rooms} + \theta_3 \cdot \text{floor} $$
目标是找到最准确的参数 $\theta_0, \theta_1, \theta_2, \theta_3$。这等同于构建一个 AI 代理,在所有可能的预测中选择最接近真实值的那个。
4. 统计学(Statistics)
与 AI 的关系相比,ML 与统计学的关系更具争议性。
一些统计学家认为 ML 只是“重新包装的统计学”,这个观点有一定道理。但也有许多研究者持反对意见。
4.1. 统计学是什么?
统计学通常被定义为通过样本推断总体的数学分支。
例如:
- 我们想了解美国青少年的平均身高,不可能测量所有青少年。于是我们从多个学校随机选取样本进行测量,并用样本均值推断总体均值。
- 统计学也研究变量之间的关系,比如温度对工业流程的影响,或房间数量对房价的影响。
统计学方法高度形式化,有严格的数学证明。例如,我们知道 95% 的置信区间在理想条件下有 95% 的概率包含真实总体均值。
⚠️ 但这些结论依赖于假设,如样本独立性和数据正态分布,这些在现实中未必成立。
4.2. 为什么说 ML 是统计学?
支持者认为:从数据中学习预测规则本质上就是在对数据生成过程做出推断。
- ML 的线性回归模型最早就源自统计学。
- 所有 ML 模型本质上都是统计工具,只是更复杂、难以解释、计算更密集。
- 有人甚至认为 ML 是“错误使用统计学”的结果,因为它缺乏人类参与的严谨性。
4.3. 为什么说 ML 不是统计学?
反对者则强调:ML 的核心是预测,而统计学侧重于推断和解释。
- 在工业界,模型的预测性能才是王道。一个预测准确但难以解释的深度神经网络完全可以接受。
- 统计学家通常不信任“黑盒”模型。
- ML 更注重模型训练的工程与计算效率,而统计学更偏向小样本和理论严谨性。
- ML 更重视实证表现,而统计学强调理论证明。
4.4. 示例对比
假设有如下数据集,记录了 10 套公寓的面积与售价:
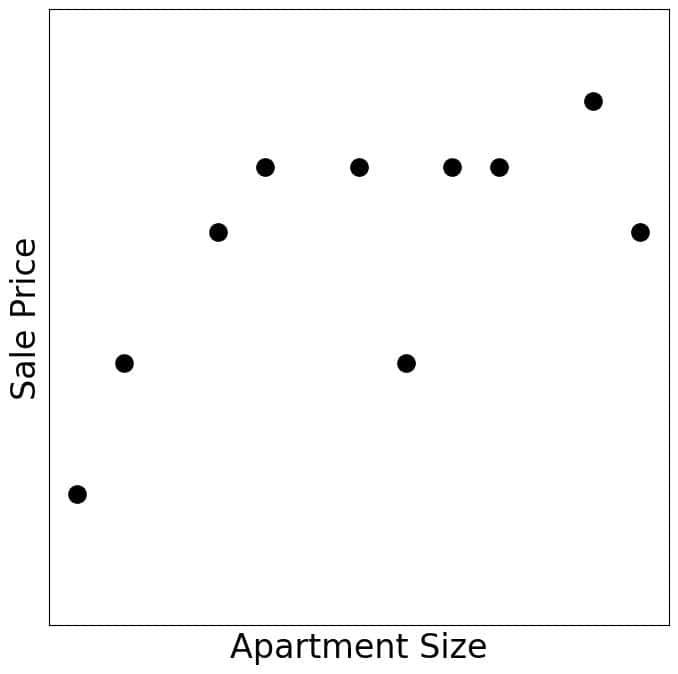
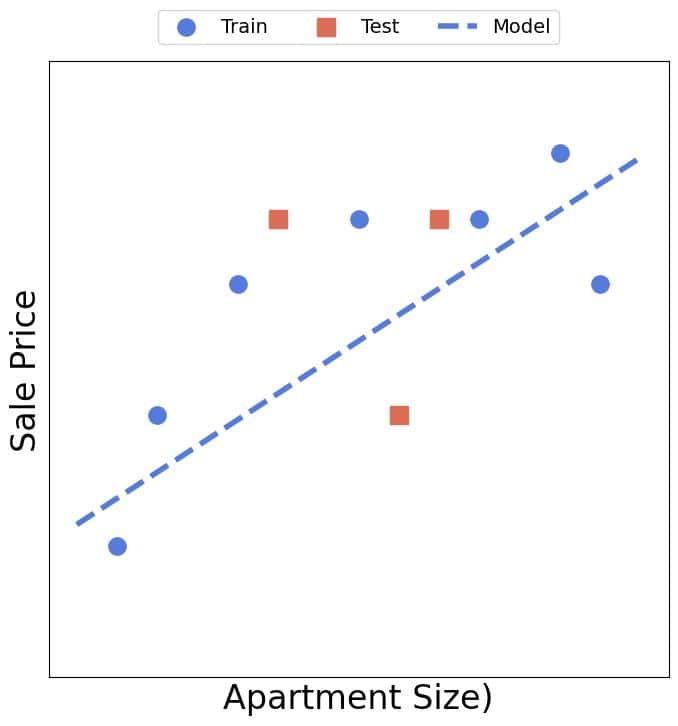
✅ ML 方法
- 将数据分为训练集(蓝色)和测试集(红色)
- 在训练集上最小化损失函数,得到模型:
$$ \theta_0 + \theta_1 \cdot \text{size} $$
- 在测试集上评估模型效果,若误差可接受,则认为模型可用
✅ 统计方法
- 对全部数据拟合线性模型(可能得到不同参数)
- 不用于预测,而是用于检验假设:面积是否显著影响房价
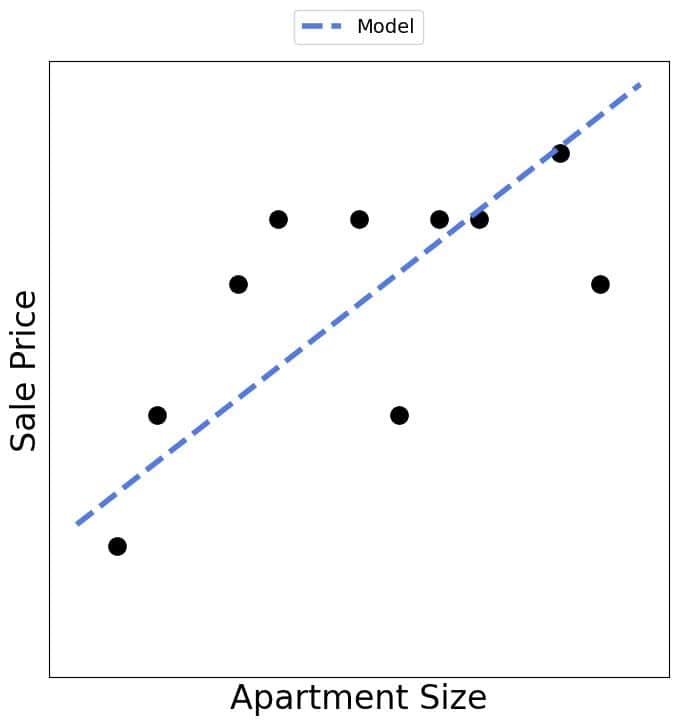
⚠️ 这个例子虽然简化,但很好地体现了 ML 与统计学在目标和方法上的差异。
5. 数据挖掘(Data Mining)
数据挖掘起源于商业数据库管理,目标是从大数据中发现有价值模式,为企业决策提供可操作的信息。
5.1. 示例
假设一家新闻网站想了解其读者的地域分布,以便调整内容策略。他们只关心当前活跃订阅者的来源地,而不是潜在用户或被动订阅者。
- 统计学方法:提出假设,如“某一地区订阅者比例高于 30%”,进行检验。
- ML 方法:预测某一地区用户订阅的可能性。
- 数据挖掘方法:直接分析现有数据,找出活跃订阅者的地域分布模式。
✅ 数据挖掘关注的是已有数据中的模式,而不是从样本推断总体。很多时候,数据集本身就是目标群体。
5.2. 数据挖掘 vs 统计学 & 机器学习
- 有人认为数据挖掘只是统计学或 ML 的应用,因为其工具大多来源于这两个领域。
- 但数据挖掘强调结果导向,而非方法论严谨性。
- 它更注重探索性分析,以发现业务关键信息为目标。
- 数据挖掘常使用启发式方法,即使数学基础不强,只要能产生价值即可。
6. 总结
本文我们探讨了人工智能、机器学习、统计学与数据挖掘之间的区别。
✅ 虽然这四个领域之间存在大量交叉,但它们的目标和方法有本质差异:
| 领域 | 目标 | 方法特点 |
|---|---|---|
| AI | 构建理性代理,解决复杂问题 | 强调智能行为,不局限于数据 |
| ML | 从数据中学习预测规则 | 强调预测性能,工程实现 |
| 统计学 | 从样本推断总体 | 强调理论证明与假设检验 |
| 数据挖掘 | 从数据中发现模式 | 强调业务价值,探索性分析 |
⚠️ 虽然边界模糊,但在实际应用中,理解这些差异有助于我们选择合适的方法和工具。