1. 引言
在本教程中,我们将讨论神经网络的训练、验证和测试阶段。这些概念是机器学习中的核心环节,能够体现模型从初步训练到最终评估的完整生命周期。此外,这些概念还与交叉验证、批量优化、正则化等技术密切相关。
2. 核心概念
神经网络的兴起极大地推动了机器学习的发展。神经网络之所以被广泛应用,是因为它具备极强的灵活性,几乎可以拟合任何类型的数据,前提是具备足够的计算资源来支持其训练过程。
要高效利用这些模型,关键在于确保模型能够从训练数据中提取出通用的规律(泛化能力)。
2.1. 训练集 vs 测试集
最基础的做法是将数据集划分为训练集和测试集。训练集用于模型学习,测试集用于评估模型的性能。测试集在训练过程中完全不参与,这样得出的模型评估结果才具有参考价值。
通常我们会使用反向传播等技术来训练神经网络。但如果我们发现模型表现不佳,尝试调整超参数后再测试,这种做法就存在问题:我们是在利用测试结果来优化模型,这会导致测试结果失真。
2.2. 验证集的作用
为避免上述问题,我们需要引入一个中间环节:验证集。验证集用于在模型开发过程中反复调整超参数,比如学习率、网络结构、正则化参数等。
✅ 验证集的作用是帮助我们优化模型,而测试集只在最后阶段使用一次,用于最终评估模型性能。
总结一下:
- 训练集:训练模型
- 验证集:调整模型参数、选择最优模型
- 测试集:最终评估模型性能
3. 实现思路
我们以一个简单的二分类任务为例,展示如何进行数据划分和模型训练。
3.1. 数据集划分
假设我们有一个带标签的数据集,如下图所示:
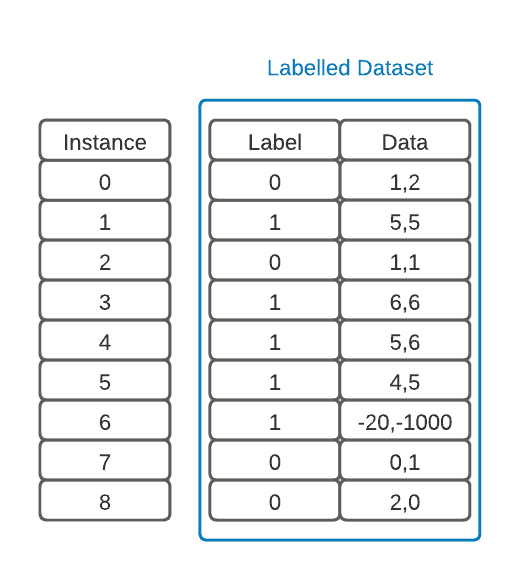
在训练前,我们通常需要进行数据预处理,包括去除异常值、标准化、归一化等操作:
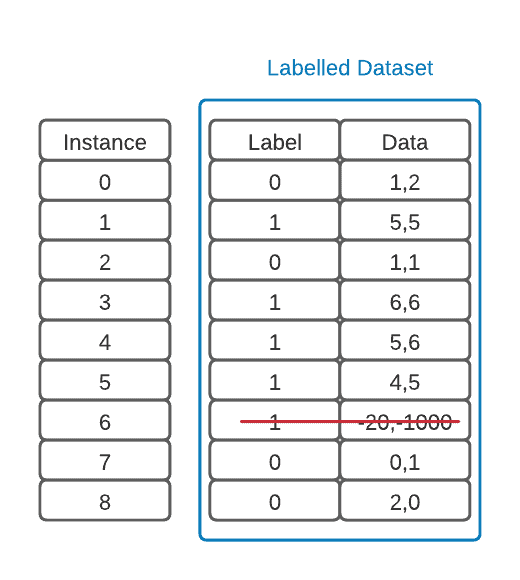
然后,将数据集划分为训练集、验证集和测试集:
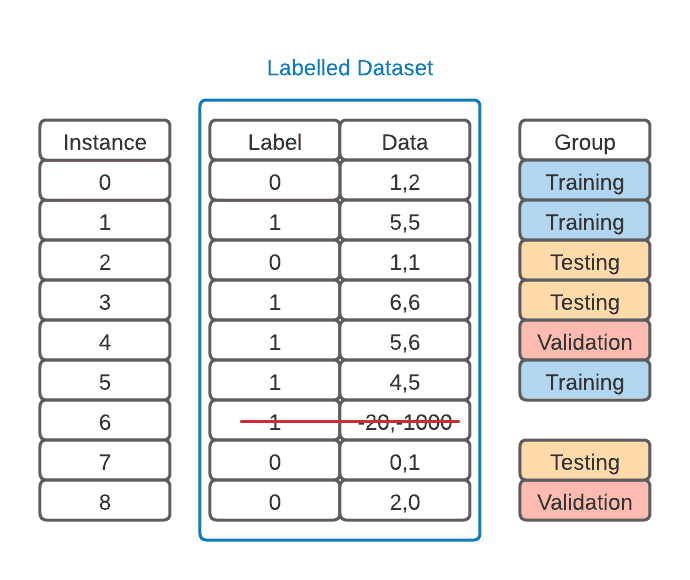
⚠️ 注意:划分时要保持各类别样本数量大致均衡,否则可能导致模型对某些类别学习不充分。
3.2. 模型训练与验证
使用前馈神经网络进行训练,通过反向传播算法不断调整权重,直到模型在训练集上达到较高准确率。
接着,使用验证集评估模型表现:
- 如果验证准确率不理想,可以调整超参数重新训练
- 可以使用早停(early stopping)防止过拟合
- 验证集还可以用于模型选择
最后,使用测试集对模型进行最终评估,确保结果未受训练过程影响。
4. Python 实现
我们使用 Python 和 Scikit-Learn 来实现完整的训练、验证和测试流程。
4.1. 环境准备
使用虚拟环境管理依赖,安装必要的库:
$ mkdir my_first_ml_project
$ cd my_first_ml_project
$ python3 -m venv env
$ source env/bin/activate # Linux/Mac
$ .\env\scripts\activate # Windows
$ pip install pandas pyarrow seaborn matplotlib scikit-learn
也可以在 Jupyter Notebook 中直接安装:
%pip install pandas pyarrow seaborn matplotlib scikit-learn
4.2. 加载 Iris 数据集
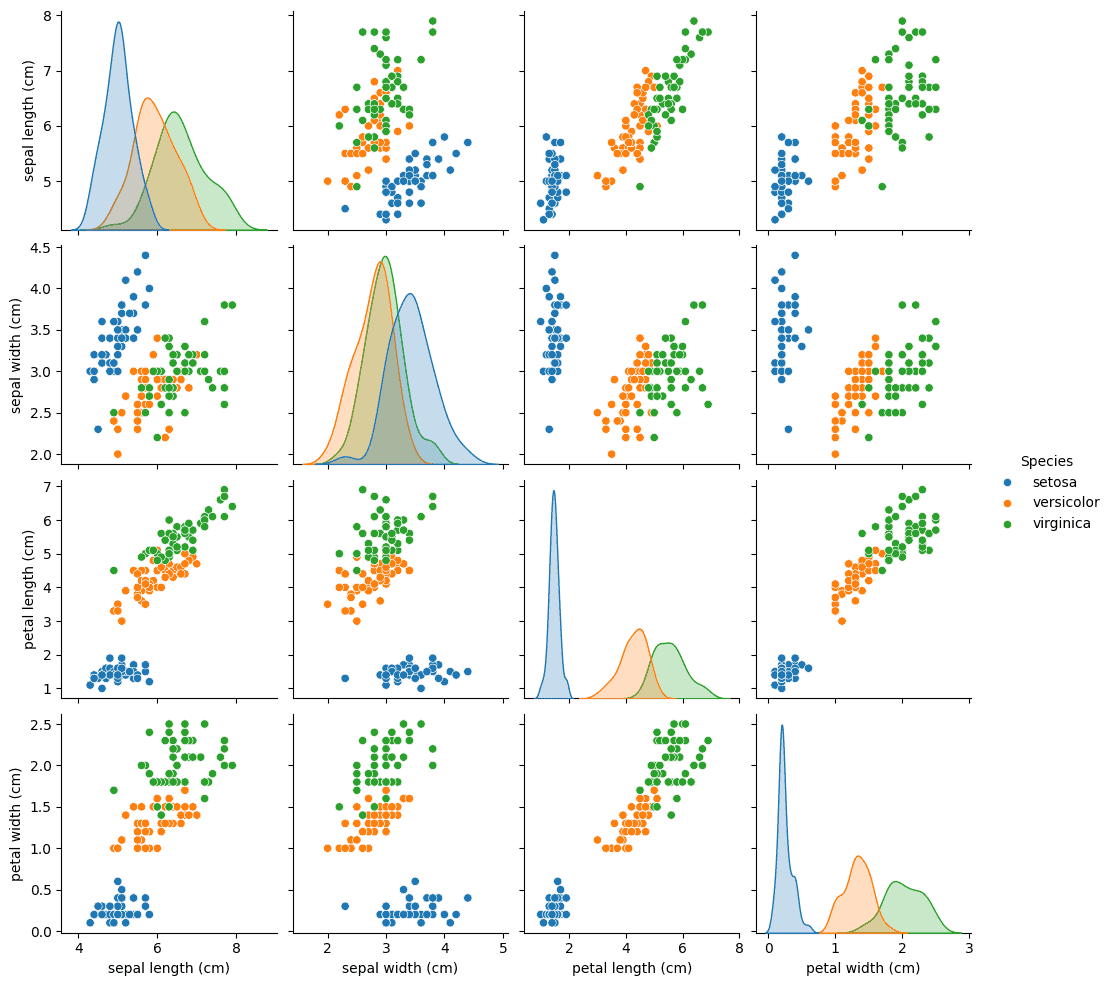
Iris 是一个经典的多分类数据集,包含 3 种鸢尾花的 4 个特征(花萼和花瓣的长宽)。
from sklearn.datasets import load_iris
import pandas as pd
iris_data = load_iris()
iris = pd.DataFrame(iris_data.data, columns=iris_data.feature_names)
iris['Species'] = list(map(lambda i: iris_data.target_names[i], iris_data.target))
可视化数据分布:
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(iris, hue='Species')
plt.show()
4.3. 划分训练集、验证集和测试集
使用 train_test_split 进行两次划分:
from sklearn.model_selection import train_test_split
# 第一次划分:60% 训练集,40% 验证+测试集
train, val_test = train_test_split(iris, test_size=0.4)
# 第二次划分:各占一半
val, test = train_test_split(val_test, test_size=0.5)
# 准备输入输出
X_cols = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
train_X, train_y = train[X_cols], train['Species']
val_X, val_y = val[X_cols], val['Species']
test_X, test_y = test[X_cols], test['Species']
4.4. 模型训练与验证
使用 MLPClassifier 构建多层感知机模型,尝试不同隐藏层神经元数量:
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
best_accuracy = 0
best_model = None
for i, layer_size in enumerate(range(1, 11)):
print(f'{i+1}: Testing MLP with {layer_size} neurons')
model = MLPClassifier(hidden_layer_sizes=layer_size, max_iter=20000)
model.fit(train_X, train_y)
pred = model.predict(val_X)
acc = accuracy_score(pred, val_y)
print(f'\tValidation accuracy: {acc:.3f}')
if acc > best_accuracy:
best_accuracy = acc
best_model = model
输出示例:
5: Testing MLP with 5 neurons
Validation accuracy: 1.000
Best model had 5 neurons in the hidden layer
4.5. 最终测试
使用测试集评估模型最终表现:
test_pred = best_model.predict(test_X)
test_acc = accuracy_score(test_pred, test_y)
print(f'\tTest accuracy: {test_acc:.3f}')
输出:
Test accuracy: 0.967
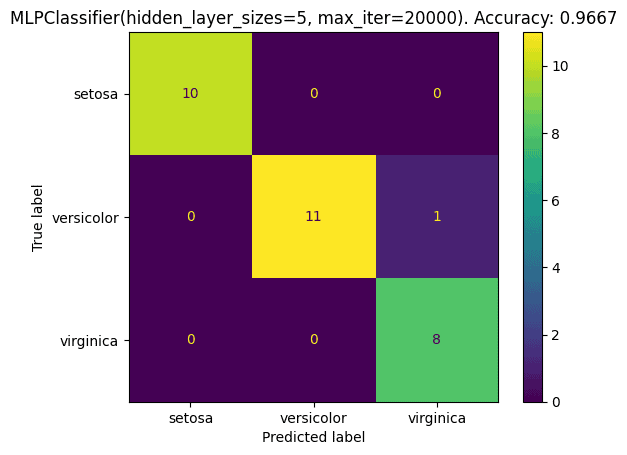
进一步输出分类报告和混淆矩阵:
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
print(classification_report(test_y, test_pred))
cm = confusion_matrix(test_y, test_pred, labels=load_iris().target_names)
cmd = ConfusionMatrixDisplay(cm, display_labels=load_iris().target_names)
cmd.plot()
cmd.ax_.set_title('Confusion Matrix')
plt.show()
输出结果:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 0.92 0.96 12
virginica 0.89 1.00 0.94 8
accuracy 0.97 30
macro avg 0.96 0.97 0.97 30
weighted avg 0.97 0.97 0.97 30
5. 总结
本文介绍了机器学习中模型开发的三个关键阶段:训练、验证和测试。
- ✅ 训练集 用于模型学习
- ✅ 验证集 用于超参数调整和模型选择
- ✅ 测试集 用于最终评估模型性能,仅在最后使用一次
我们使用 Python 和 Scikit-Learn 实现了完整的流程,包括数据加载、划分、训练、验证和测试。
通过合理使用这三个数据集,可以有效防止模型过拟合,提高模型的泛化能力。同时,我们还展示了如何通过验证集选择最优模型,并最终使用测试集评估模型表现。