1. 简介
One Class SVM(支持向量机)是一种无监督异常检测方法,常用于识别数据集中的离群点(Outliers)或异常点(Anomalies)。
与传统的分类 SVM 不同,One Class SVM 仅使用一个类的数据进行训练,目标是学习该类数据的边界(Boundary),从而判断新数据是否属于这个类。这在实际应用中非常有用,例如在网络入侵检测、信用卡欺诈识别等场景中,我们可能只有正常数据,而异常数据非常稀少甚至没有。
本文将介绍 One Class SVM 的基本原理,并通过一个简单的示例说明其工作方式。
2. 支持向量机(SVM)基础
传统的 SVM 是一种监督学习算法,用于分类任务。它通过在特征空间中寻找一个最优超平面(Hyperplane),将不同类别的数据尽可能分开。
而 One Class SVM 则是无监督学习的一种形式,它不依赖于多个类别的标签,而是试图找出一个能包围所有训练数据的区域(例如一个超球体)。当新样本落在这个区域之外时,就被视为异常。
✅ 一句话总结:
传统 SVM 是“分界分类”,One Class SVM 是“围界识别”。
3. One Class SVM 原理
One Class SVM 有两种主流形式:
- Schölkopf 提出的超平面方法
- Tax 和 Duin 提出的超球体方法(SVDD)
我们重点介绍 SVDD(Support Vector Data Description)方法,它通过构建一个最小体积的超球体来包围所有训练数据点。
3.1 数学建模
设训练数据为:
$$ \mathbf{x}_1, \mathbf{x}_2, \cdots, \mathbf{x}_n $$
目标是找到一个中心为 $\mathbf{a}$、半径为 $R$ 的超球体,使得所有训练数据都尽可能落在该球体内。
基本优化目标:
$$ \min R^2 $$
约束条件:
$$ |\mathbf{x}_i - \mathbf{a}|^2 \leq R^2, \quad \forall i $$
3.2 引入松弛变量(Soft Margin)
为了增强模型对异常点的鲁棒性,我们引入松弛变量 $\xi_i$ 来允许部分点可以轻微超出边界:
优化目标变为:
$$ \min R^2 + C \sum_i \xi_i $$
新的约束:
$$ |\mathbf{x}_i - \mathbf{a}|^2 \leq R^2 + \xi_i, \quad \xi_i \geq 0 $$
其中:
- $C$ 是一个正则化参数,控制模型对异常点的容忍度。
- $\xi_i$ 越大,说明该点对模型的影响越小。
3.3 拉格朗日乘子法(Lagrange Multipliers)
引入拉格朗日乘子 $\alpha_i$ 和 $\gamma_i$,构造拉格朗日函数:
$$ \mathcal{L}(R, \mathbf{a}, \alpha_i, \gamma_i, \xi_i) = R^2 + C\sum_i \xi_i - \sum_i \alpha_i (R^2 + \xi_i - (|\mathbf{x}_i|^2 - 2\mathbf{a} \cdot \mathbf{x}_i + |\mathbf{a}|^2 )) - \sum_i \gamma_i \xi_i $$
优化目标是:
最大化 $\mathcal{L}$ 关于 $\alpha_i$ 和 $\gamma_i$,最小化 $\mathcal{L}$ 关于 $R$ 和 $\mathbf{a}$。
4. 示例:One Class SVM 实战
我们使用 Python 的 scikit-learn 库来演示一个简单的例子。
4.1 数据准备
- 生成 100 个来自二维高斯分布 $\mathcal{N}(0, 0.3)$ 的样本。
- 添加 20 个来自均匀分布 $\mathcal{U}(-3, 3)$ 的异常点。
import numpy as np
from sklearn.svm import OneClassSVM
import matplotlib.pyplot as plt
# 正常数据(高斯分布)
X_train = 0.3 * np.random.randn(100, 2)
# 测试数据:正常+异常
X_test = np.concatenate([
0.3 * np.random.randn(20, 2),
np.random.uniform(low=-3, high=3, size=(20, 2))
])
# 标签(仅用于可视化)
y_test = np.array([0]*20 + [1]*20)
4.2 模型训练与预测
# 训练 One Class SVM 模型
clf = OneClassSVM(gamma='scale', nu=0.1)
clf.fit(X_train)
# 预测
y_pred = clf.predict(X_test)
4.3 可视化结果
plt.figure(figsize=(8, 6))
# 正常数据点
plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1], c='blue', label='Normal (True)')
# 异常数据点
plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1], c='red', label='Outlier (True)')
# One Class SVM 预测的正常点
plt.scatter(X_test[y_pred == 1, 0], X_test[y_pred == 1, 1], facecolors='none', edgecolors='green', label='Normal (Predicted)')
# One Class SVM 预测的异常点
plt.scatter(X_test[y_pred == -1, 0], X_test[y_pred == -1, 1], c='orange', label='Outlier (Predicted)')
plt.title("One Class SVM - Outlier Detection")
plt.legend()
plt.grid(True)
plt.show()
4.4 可视化效果
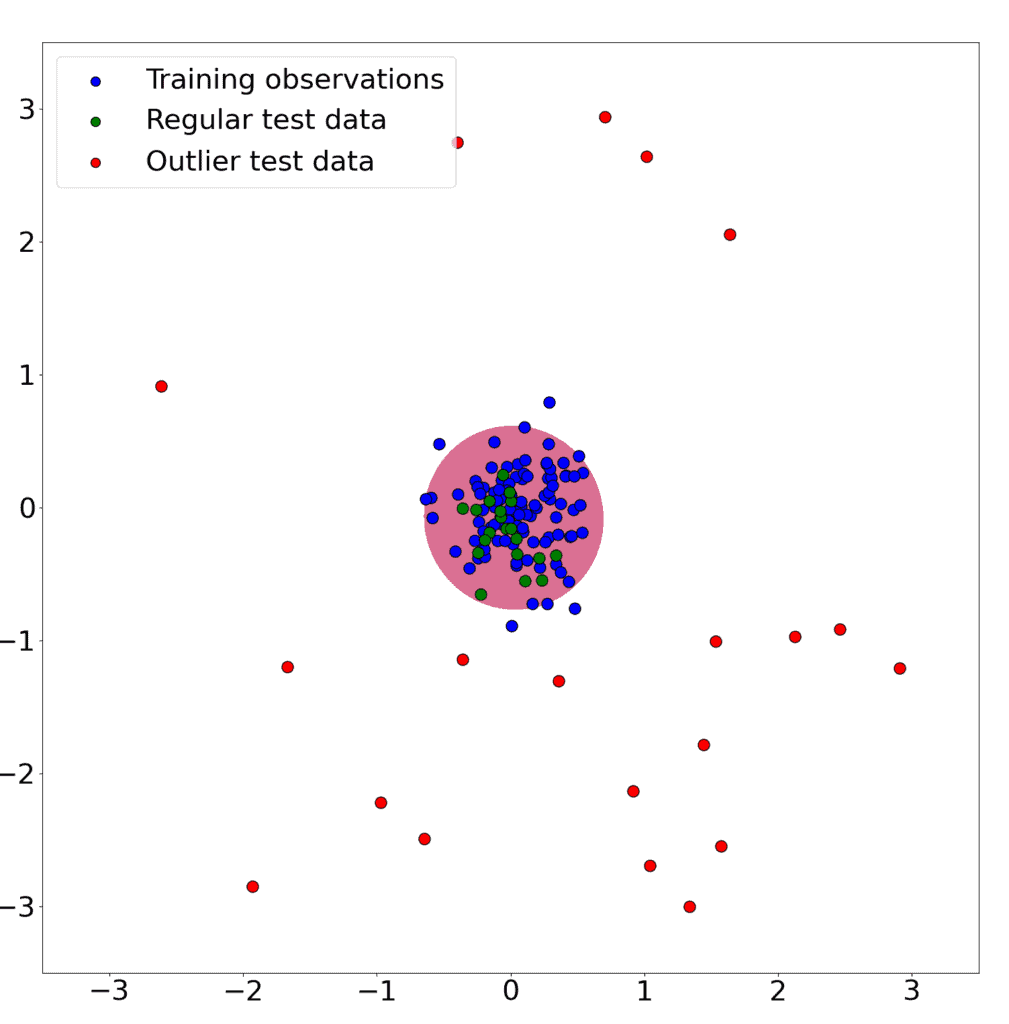
图中:
- 蓝色点:真实正常数据
- 红色点:真实异常数据
- 绿色空心点:模型预测为正常的数据
- 橙色点:模型预测为异常的数据
可以看到,One Class SVM 能较好地识别出大部分异常点,即使训练数据中没有异常样本。
5. 总结
One Class SVM 是一种强大的无监督异常检测工具,适用于只有正常数据或异常数据极少的场景。
✅ 优点:
- 无需异常样本进行训练
- 可以处理高维数据
- 对噪声有一定鲁棒性
❌ 缺点:
- 对参数(如
nu和gamma)敏感,调参较为关键 - 在大规模数据集上训练较慢
⚠️ 踩坑提醒:
nu参数控制模型对异常点的容忍度,取值范围为 (0, 1),一般设置为异常样本比例的上界。- 使用 RBF 核时,
gamma参数对模型性能影响很大,建议使用网格搜索进行调优。
如果你有异常检测的需求,尤其是在数据集中缺乏异常样本的情况下,One Class SVM 是一个值得尝试的算法。