1. 引言
网络爬虫(或称蜘蛛)是自动搜索和索引网页内容的程序。当用户执行搜索查询时,爬虫通过扫描网页来检索、更新和索引网站信息。
WebMagic 是一个简洁、强大且可扩展的爬虫框架。其设计灵感来源于 Python 著名的 Scrapy 框架,能以最小化样板代码处理 HTTP 请求、HTML 解析、任务调度和数据管道处理。
本文将探讨 WebMagic 的架构、配置方法及基础示例。
2. 架构设计
WebMagic 采用模块化可扩展架构,核心组件如下:
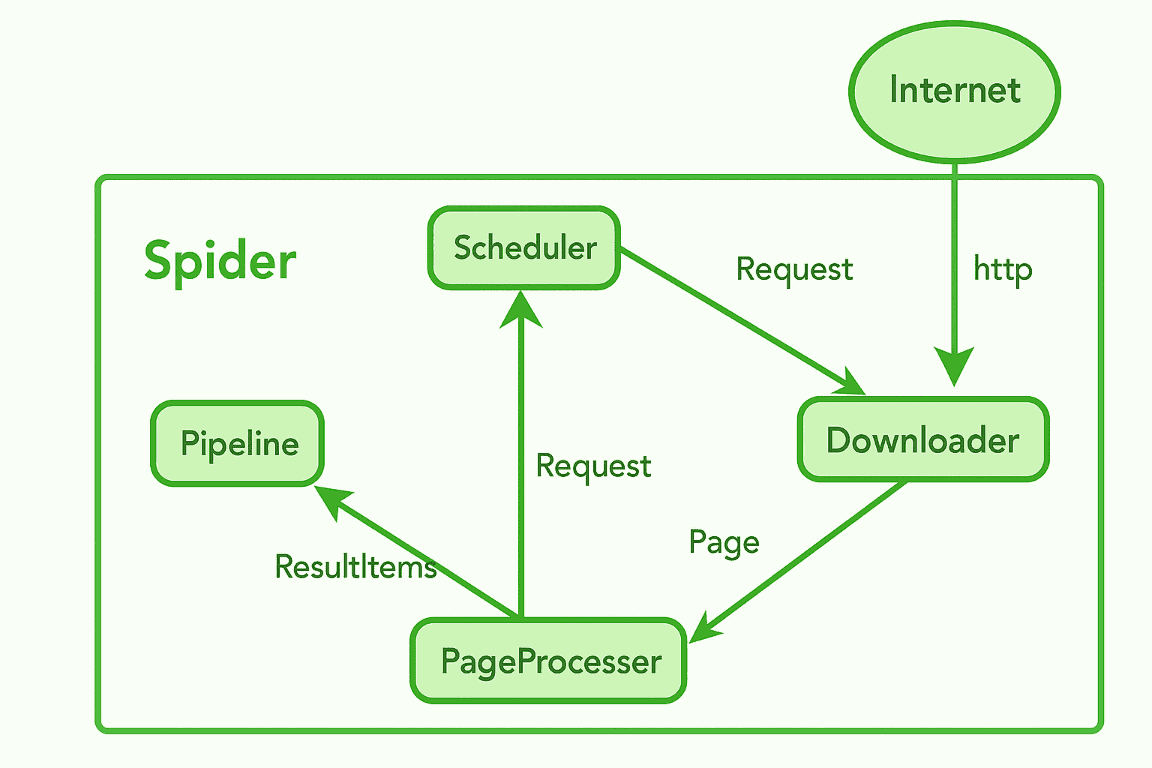
2.1 Spider
Spider 是驱动整个爬取流程的核心引擎。它接收初始 URL,并协调调用 Downloader、Processor 和 Pipeline 组件。
2.2 Scheduler
Scheduler 负责管理待爬取 URL 队列,并通过记录已访问 URL 防止重复爬取。它每次向 Downloader 发送一个请求进行处理。支持以下实现方式:
- 内存队列
- 文件队列
- Redis 队列
- 自定义调度器
2.3 Downloader
Downloader 处理实际 HTTP 请求,负责从互联网下载 HTML 内容。默认使用 Apache HttpClient 实现,但可替换为 OkHttp 或其他库。下载完成后将页面传递给 PageProcessor。
2.4 PageProcessor
PageProcessor 是爬虫逻辑的核心。顾名思义,它定义了如何从页面提取目标数据(如商品、价格等)及待爬取的新链接。 必须实现 process 方法解析响应并提取信息。
提取的数据发送至 Pipeline,新链接则返回给 Scheduler。
2.5 Pipeline
Pipeline 处理提取数据的后置操作,常见场景包括:
- 保存到数据库
- 写入文件
- 输出到控制台
3. Maven 配置
WebMagic 使用 Maven 构建,推荐通过 Maven 管理项目依赖。在 pom.xml 中添加以下依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>1.0.3</version>
</dependency>
⚠️ WebMagic 默认使用 slf4j-log4j12 实现,需排除该依赖以避免冲突:
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
4. Hello World 示例
以下示例爬取 books.toscrape.com 站点,提取前 10 本书籍的标题和价格并输出到控制台:
public class BookScraper implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
@Override
public void process(Page page) {
var books = page.getHtml().css("article.product_pod");
for (int i = 0; i < Math.min(10, books.nodes().size()); i++) {
var book = books.nodes().get(i);
String title = book.css("h3 a", "title").get();
String price = book.css(".price_color", "text").get();
System.out.println("Title: " + title + " | Price: " + price);
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new BookScraper())
.addUrl("https://books.toscrape.com/")
.thread(1)
.run();
}
}
关键点说明:
Site配置:设置请求重试 3 次,间隔 1 秒(避免被封禁)private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);- 核心逻辑在
process()方法:- 通过 CSS 选择器定位所有
article.product_pod元素 - 遍历提取书籍标题(
h3 a的 title 属性)和价格(.price_color的文本)
- 通过 CSS 选择器定位所有
- 启动爬虫:从首页开始,单线程运行
程序输出示例:
17:02:26.460 [main] INFO us.codecraft.webmagic.Spider -- Spider books.toscrape.com started!
Title: A Light in the Attic | Price: £51.77
Title: Tipping the Velvet | Price: £53.74
Title: Soumission | Price: £50.10
Title: Sharp Objects | Price: £47.82
Title: Sapiens: A Brief History of Humankind | Price: £54.23
Title: The Requiem Red | Price: £22.65
Title: The Dirty Little Secrets of Getting Your Dream Job | Price: £33.34
Title: The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull | Price: £17.93
Title: The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics | Price: £22.60
Title: The Black Maria | Price: £52.15
get page: https://books.toscrape.com/
5. 总结
本文介绍了 WebMagic 的核心架构、配置方法和基础应用。WebMagic 为 Java 爬虫开发提供了简洁强大的解决方案,其设计让开发者能专注于数据提取,而非 HTTP 通信、解析或线程管理等底层细节。
从示例可见,仅需少量代码即可实现功能完整的爬虫。对于需要快速构建爬虫的场景,WebMagic 是个不错的选择(踩坑提示:生产环境需注意反爬策略和异常处理)。
本文源码可在 GitHub 获取。