1. 介绍
Project Reactor 是构建 Java 全非阻塞式响应式应用的强力工具库。Reactor 提供了两种可组合的响应式类型:Flux 和 Mono。
在多核架构普及的今天,轻松实现并行计算至关重要。对于 Flux,Project Reactor 通过特殊类型 ParallelFlux 提供并行支持,该类型内置了优化的并行操作符。
本文将通过计算密集型任务对比 Flux 和 ParallelFlux,分析它们的差异及对响应式应用性能的影响。
2. Flux 基础
Flux 是 Project Reactor 的核心类型,表示 0 到 N 个元素的响应式流。Flux 支持异步非阻塞数据处理,非常适合处理数据库结果或事件流等序列,如下图所示:

创建简单 Flux 的示例:
Flux<Integer> flux = Flux.range(1, 10);
默认情况下 Flux 在单线程上顺序执行,但可通过调度器实现并发。 对于大多数响应式工作流(尤其是 I/O 密集型或小数据量场景),Flux 简单高效。
3. ParallelFlux 基础
ParallelFlux 是 Flux 的并行扩展版。它将流拆分为多个轨道(rails),每个轨道在独立线程上处理,特别适合 CPU 密集型任务,如下图所示:

通过 parallel() 操作符配合 runOn(Scheduler scheduler) 可将 Flux 转换为 ParallelFlux:
Flux<Integer> flux = Flux.range(1, 10);
ParallelFlux<Integer> parallelFlux = flux.parallel(2).runOn(Schedulers.parallel());
ParallelFlux 利用多线程加速计算,是计算密集型任务的理想选择。
4. Flux 与 ParallelFlux 的核心差异
我们将通过计算 斐波那契数列(计算密集型任务)展示两者性能差异,突出 ParallelFlux 的并行优势。
4.1 斐波那契计算
处理整数列表,计算每个整数的斐波那契值。该递归函数计算成本高,模拟真实 CPU 密集型任务:
private long fibonacci(int n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
4.2 Flux 实现
使用 Flux 在单线程顺序处理:
Flux<Integer> flux = Flux.just(43, 44, 45, 47, 48)
.map(n -> fibonacci(n));
此实现简单,但在 CPU 密集型任务中较慢(逐个处理)。
4.3 ParallelFlux 实现
ParallelFlux 版本将流拆分为 2 个轨道,每个轨道独立线程运行。通过多线程分发任务,缩短总执行时间:
ParallelFlux<Integer> parallelFlux = Flux.just(43, 44, 45, 47, 48)
.parallel(2)
.runOn(Schedulers.parallel())
.map(n -> fibonacci(n));
展示了 ParallelFlux 如何利用多线程加速计算。
4.4 执行时间对比
使用 JMH 微基准测试计算两种实现的执行时间。
Flux 基准测试
@Test
public void givenFibonacciIndices_whenComputingWithFlux_thenCorrectResults() {
Flux<Long> fluxFibonacci = Flux.just(43, 44, 45, 47, 48)
.map(Fibonacci::fibonacci);
StepVerifier.create(fluxFibonacci)
.expectNext(433494437L, 701408733L, 1134903170L, 2971215073L, 4807526976L)
.verifyComplete();
}
JMH 基准测试实现:
@Test
public void givenFibonacciIndices_whenComputingWithFlux_thenRunBenchMarks() throws IOException {
Main.main(new String[] {
"com.baeldung.reactor.flux.parallelflux.FibonacciFluxParallelFluxBenchmark.benchMarkFluxSequential",
"-i", "3",
"-wi", "2",
"-f", "1"
});
}
@Benchmark
public List<Long> benchMarkFluxSequential() {
Flux<Long> fluxFibonacci = Flux.just(43, 44, 45, 47, 48)
.map(Fibonacci::fibonacci);
return fluxFibonacci.collectList().block();
}
多核机器上的基准结果(可能因系统负载略有波动):
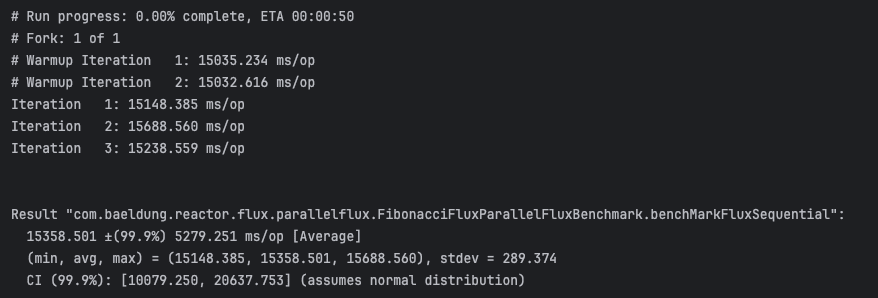

ParallelFlux 基准测试
@Test
public void givenFibonacciIndices_whenComputingWithParallelFlux_thenCorrectResults() {
ParallelFlux<Long> parallelFluxFibonacci = Flux.just(43, 44, 45, 47, 48)
.parallel(3)
.runOn(Schedulers.parallel())
.map(Fibonacci::fibonacci);
Flux<Long> sequencialParallelFlux = parallelFluxFibonacci.sequential();
Set<Long> expectedSet = new HashSet<>(Set.of(433494437L, 701408733L, 1134903170L, 2971215073L, 4807526976L));
StepVerifier.create(sequencialParallelFlux)
.expectNextMatches(expectedSet::remove)
.expectNextMatches(expectedSet::remove)
.expectNextMatches(expectedSet::remove)
.expectNextMatches(expectedSet::remove)
.expectNextMatches(expectedSet::remove)
.verifyComplete();
}
JMH 基准测试实现:
@Benchmark
public List<Long> benchMarkParallelFluxSequential() {
ParallelFlux<Long> parallelFluxFibonacci = Flux.just(43, 44, 45, 47, 48)
.parallel(3)
.runOn(Schedulers.parallel())
.map(Fibonacci::fibonacci);
return parallelFluxFibonacci.sequential().collectList().block();
}
@Test
public void givenFibonacciIndices_whenComputingWithParallelFlux_thenRunBenchMarks() throws IOException {
Main.main(new String[] {
"com.baeldung.reactor.flux.parallelflux.FibonacciFluxParallelFluxBenchmark.benchMarkParallelFluxSequential",
"-i", "3",
"-wi", "2",
"-f", "1"
});
}
ParallelFlux 基准结果(毫秒级):
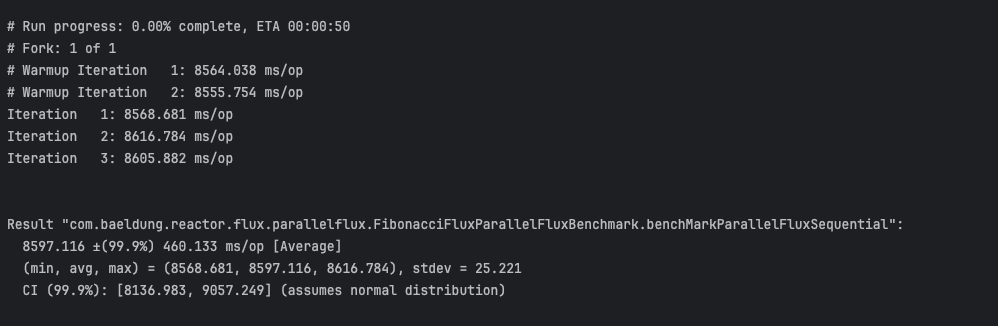

测试表明:在典型多核 CPU 上,ParallelFlux 处理 CPU 密集型任务比 Flux 快得多。
5. Project Reactor 中的调度器
调度器(Schedulers)控制响应式流的执行线程。 它是管理 Flux 和 ParallelFlux 并发性的关键组件。
关键调度器对比:
| 调度器类型 | 适用场景 | 线程池特点 |
|------------|----------|------------|
| Schedulers.parallel() | CPU 密集型任务 | 固定大小(= CPU 核心数) |
| Schedulers.boundedElastic() | I/O 密集型任务 | 动态扩容 |
ParallelFlux 必须 指定调度器(通常用 Schedulers.parallel())定义轨道执行线程。Flux 也可通过 publishOn(Schedulers.boundedElastic()) 引入并发提升 I/O 操作响应性。
务必根据负载选择调度器:CPU 密集用 parallel(),I/O 密集用 boundedElastic()。 这是高效执行的基础。
6. 如何选择 Flux 和 ParallelFlux
根据工作负载类型选择:
✅ 选择 Flux 的场景:
- I/O 密集型任务(REST 调用、数据库访问)
- 小数据集或轻量级操作
- 顺序处理已足够快的场景
✅ 选择 ParallelFlux 的场景:
- CPU 密集型任务(需并行减少执行时间)
- 大数据集(需多核分发提升性能)
测试证明:ParallelFlux 显著提升计算密集任务性能,而 Flux 在轻量/I/O 场景更简单高效。
7. 实践陷阱与最佳实践
7.1 ParallelFlux 常见陷阱
⚠️ 线程管理开销: 对于轻量任务,ParallelFlux 的线程开销可能使其比 Flux 更慢。
⚠️ 轨道数过多: 轨道数超过 CPU 核心数(如 4 核机器用 8 轨道)会导致线程争用,性能下降。
⚠️ 顺序不保证: 默认不保留元素顺序,顺序敏感场景需用 ordered() 或后处理。
用以下测试验证顺序问题(重复执行5次):
@RepeatedTest(5)
public void givenListOfIds_whenComputingWithParallelFlux_OrderChanges() {
ParallelFlux<String> parallelFlux = Flux.just("id1", "id2", "id3")
.parallel(2)
.runOn(Schedulers.parallel())
.map(String::toUpperCase);
List<String> emitted = new CopyOnWriteArrayList<>();
StepVerifier.create(parallelFlux.sequential().doOnNext(emitted::add))
.expectNextCount(3)
.verifyComplete();
log.info("ParallelFlux emitted order: {}", emitted);
}

多次运行日志显示输出顺序不固定——并行执行导致最终序列不确定。
7.2 ParallelFlux 最佳实践
✅ CPU 密集型任务用 Schedulers.parallel(): 固定线程池大小=CPU核心数,避免系统过载。
✅ 轨道数匹配 CPU 核心数: 动态获取核心数:
int cores = Runtime.getRuntime().availableProcessors();
ParallelFlux<Long> parallelFlux = Flux.just(40, 41, 42, 43, 44, 45, 46, 47, 48, 49)
.parallel(cores)
.runOn(Schedulers.parallel())
.map(n -> fibonacci(n));
8. 总结
本文通过斐波那契算法(计算密集型任务)对比了 Flux 和 ParallelFlux,分析了适用场景、差异及 ParallelFlux 的最佳实践与陷阱。
所有代码示例可在 GitHub 获取。