1. 概述
本文将介绍自监督学习(Self-Supervised Learning)的基本概念。我们会先定义什么是自监督学习,说明它在机器学习中的重要性,然后通过几个典型的应用示例来说明其工作原理,并讨论它存在的一些局限性。
2. 背景知识
过去几年,机器学习在多个领域取得了突破性进展,从自动驾驶到疾病预测,应用场景非常广泛。推动这一进步的关键因素之一,是大量精心标注的数据集的可用性。
然而,仅靠监督学习和标注数据,机器学习的发展已经面临瓶颈。例如,一些任务(如低资源语言的翻译)中,标注数据的获取成本高昂或根本不可行。因此,要让人工智能更接近人类水平的理解能力,我们必须探索无需人工标注数据的训练方法。其中,最具前景的方法之一就是自监督学习。
3. 定义
自监督学习的核心思想是:先利用未标注数据学习通用的特征表示,再在具体下游任务中用少量标注数据进行微调。关键问题在于:如何在没有标签的情况下学到有用的表示。
在自监督学习中,模型的训练信号不是人工标注的标签,而是数据本身。例如,一种常见的方法是训练模型根据输入的一部分来预测另一部分隐藏的内容。
下图展示了监督学习(左)和自监督学习(右)的工作方式对比: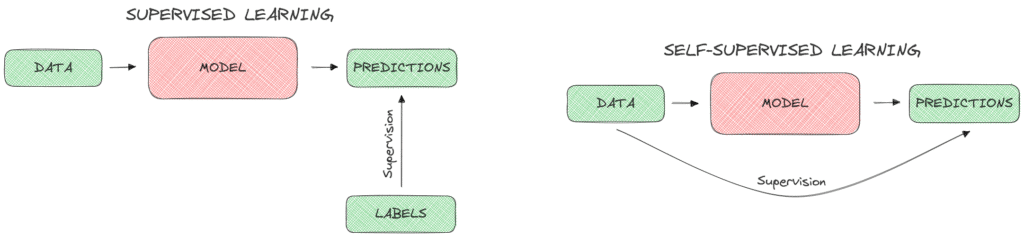
4. 重要性
近年来,越来越多的自监督模型被提出,试图替代传统的监督学习方法。自监督学习之所以重要,主要有以下几个原因:
✅ 减少数据标注需求,节省时间和成本
✅ 使得在难以获取标注数据的领域也能应用机器学习
✅ 未标注数据无处不在,尤其在互联网和社交媒体上,图像、视频、音频等资源极为丰富
5. 典型应用场景
下面我们将通过几个不同模态的示例来展示自监督学习的实际应用。
5.1. 视觉领域
视觉任务中有很多自监督方法用于学习更强大的特征表示。我们来看看几个常见任务:
图像上色(Image Colorization)
在图像上色任务中,模型被训练为将灰度图还原为彩色图像。训练过程中无需人工标注,因为原始图像本身就提供了彩色版本作为监督信号。
训练完成后,模型学到的特征表示可用于图像分类、分割等下游任务。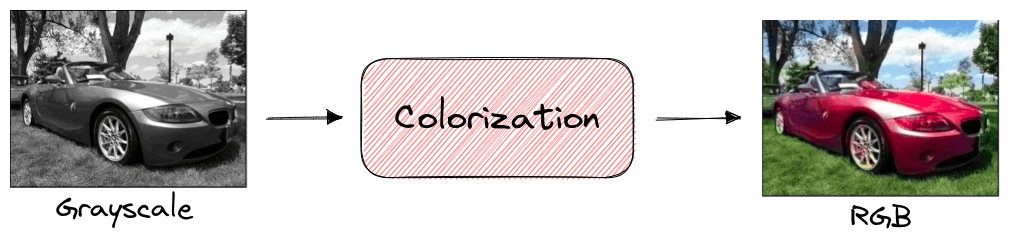
图像去噪(Denoising)
模型被训练为从加噪或损坏的图像中恢复原始图像。由于我们可以在输入图像中人为添加噪声,因此训练数据无需标注。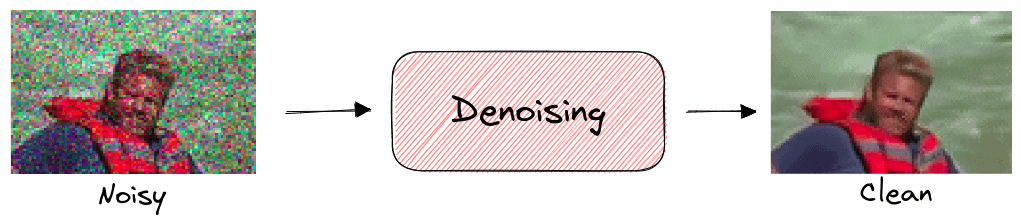
图像补全(Inpainting)
图像补全的目标是重建图像中缺失的部分。训练时,我们只需随机裁剪图像中的某些区域,即可生成训练样本。
5.2. 音视频领域
自监督学习也可用于音视频任务,例如判断音频与视频是否同步。
在一段视频中,音频和视觉事件通常是同步的,比如吉他手拨动琴弦时会发出相应的旋律。我们可以训练模型判断音频和视频是否匹配,从而学习它们之间的关系。由于音视频信息天然对齐,无需标注即可训练。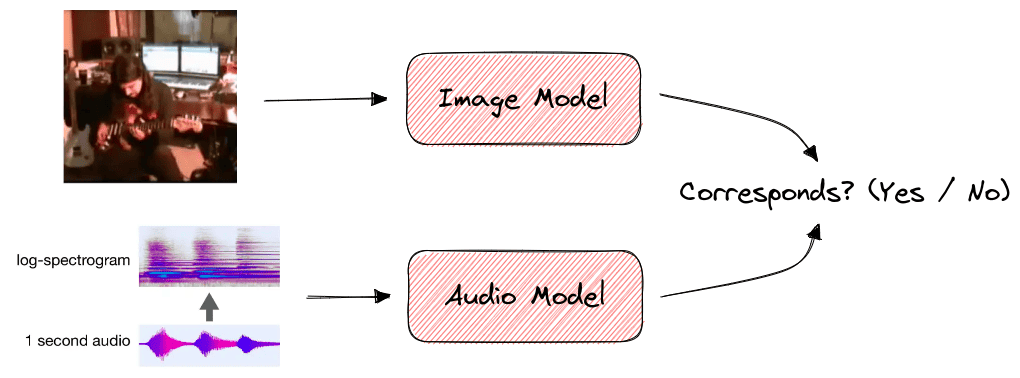
5.3. 文本领域
在语言模型训练中,如何定义预测目标以学习丰富的词向量是一个挑战。BERT 等大规模语言模型正是通过自监督学习实现的。
BERT 使用了两种主要的训练策略:
- MaskedLM:将输入句子中的一些词隐藏,训练模型预测这些词
- Next Sentence Prediction:判断两个句子是否连续
下图展示了 MaskedLM(左)和 Next Sentence Prediction(右)的训练目标: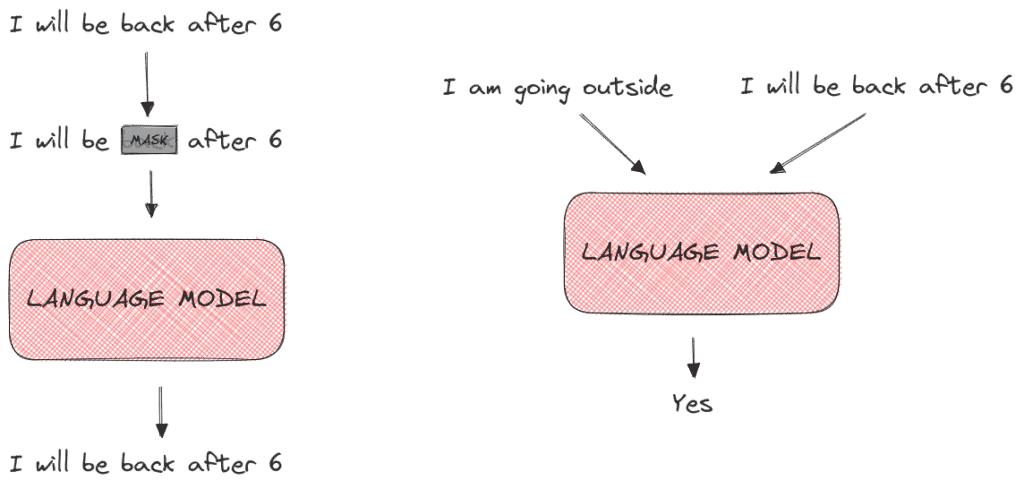
6. 局限性
尽管自监督学习潜力巨大,但我们也应正视它的一些局限:
6.1. 训练时间成本高
机器学习模型的训练本身就需要大量计算资源,而自监督学习由于缺乏真实标签指导,训练过程可能更长。我们需要权衡:是花更多时间训练模型,还是直接人工标注数据进行监督学习。
6.2. 伪标签准确性问题
自监督学习依赖于伪标签(pseudo-labels)进行训练。这些标签是模型自己生成的,在某些情况下可能存在误差,进而影响模型最终性能。因此,在使用前应评估伪标签的质量。
7. 总结
本文介绍了自监督学习的基本概念、其在图像、音视频、文本等领域的典型应用,以及它的优势与局限性。
✅ 自监督学习为减少人工标注、提升模型泛化能力提供了新思路
✅ 它在大规模预训练模型中扮演了关键角色
⚠️ 但也要注意其训练成本较高、伪标签可能不准确等问题
如果你在处理数据标注成本高、数据分布复杂或多模态任务时遇到瓶颈,不妨尝试引入自监督学习策略。