1. Introduction
In this tutorial, we’ll study LlamaIndex. We’ll examine its role in augmenting the efficiency of large language models (LLM) on multimodal semantic search tasks.
2. LlamaIndex: Use Case
LlamaIndex (GPT index) is an external framework explicitly designed for two purposes:
- Efficient information retrieval from large (unstructured /quasi-structured) data points such as TXT, DOCXs, PDFs, XML, etc.
- The subsequent interaction with this processed information.
LlamaIndex augments the LLM to provide an intelligent and flexible method for querying and managing extensive information collections.
2.1. Advantages of LlamaIndex
First, LlamaIndex makes it easier to search and retrieve relevant information from unstructured datasets, even when conventional search methods fail.
Second, LLMs are trained in limited word contexts. So, they need to be updated and specialized for specific data or business domains. LlamaIndex augments our LLMs to our custom data sources by creating a knowledge index to contextualize overall results.
Third, LlamaIndex works best to solve a query with widespread solution space (the relevant information is scattered across multiple documents or sections of large documents). In this case, it catalyzes semantic searches across a collection, linking related concepts and ideas. This allows users to get coherent and updated responses to their complex queries.
Last but not least, in addition to searching, we can use LlamaIndex to extract summaries, generate reports, and provide insights from large data sets.
3. LlamaIndex
LlamaIndex is an orchestration framework integrating private and unseen external data with LLM responses.
It provides more coherent and relevant results for a given user query. Additionally, it exposes our LLMs to both structured and unstructured data sources, which, in turn, makes them more efficient in generating context-aware responses.
3.1. LlamaIndex Data Interface
LlamaIndex primarily focuses on indexing and retrieving external data rather than integration and generation.
First, it structures large data items into chunks that we can better manage. Moreover, it indexes external data so that retrieval is fast, efficient, and context-aware.
The indexing process involves organizing the data in some data structure, such as a graph, tree, or skip list:
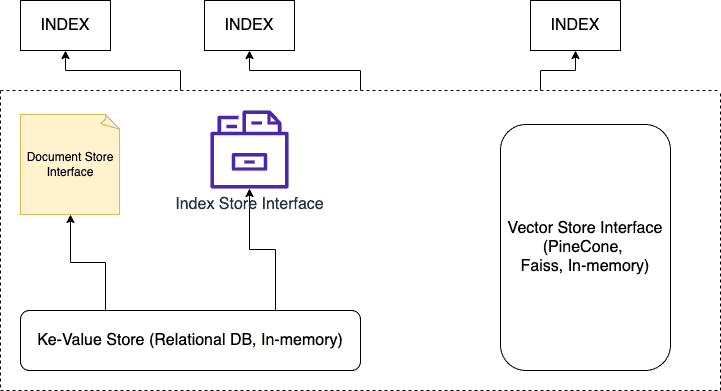
Here, we have two significant data sources. The Vector database stores vector embeddings against our structured data points (text chunks, images, or audio). The second source is a crucial value map in a relational database (Elastic Search). It also contains raw file paths to external data items.
Each keyword points to multiple nodes, which might have multiple keywords linked to it. LlamaIndex has specialized data loaders for each case that help index all data items for retrieval.
4. Advanced Multimodal Search Using LlamaIndex
Let’s work out the most common use case of multimodal semantic search using a vector database, LLM, and LLaMaIndex.
4.1. Multimodal Search
Multi-modal search is an advanced search technology that cuts across more than one modality. The user can query and retrieve information from multiple spaces, such as text, audio, video, and images. This differs from traditional search methods that implement some or the other form of lexical search over a single modality.
Multimodal search works in three steps. First, we extract and store all our data (documents, audio, video, images, etc.) in a local repository. Then, we use an LLM to generate an embedding for each data point and project it to the same vector space since we have multimodality. Lastly, we use the same LLM to generate the embedding of the user query and search all the stored embeddings to find our top K matching items.
4.2. Semantic Search Settings
We are given images, documents, and audio and video files. Our objective is to perform a semantic search based on our textual query. For this, we can use both TensorFlow and PyTorch. However, we’ll use the PyTorch framework for this task.
We’ll have our documents, images, audio, and video collection in our pipeline. Furthermore, we use FAISS to index vector embeddings for similarity search and LlamaIndex to handle external knowledge sources and retrieve factual data. Here, we transform all modalities to text and then use a standard embedding model.
5. Python Setup
We use the following libraries:
- llama-index
- llama-cloud
- llama-index-core
- llama-index-embeddings-huggingface
- llama-index-legacy
- llama-index-llms-huggingface
- llama-index-readers-file
- llama-index-readers-llama-parse
- llama-parse
- torch
- torchaudio
- torchlibrosa
- torchtext
- torchvision
- pydub
- PyPDF2
- faiss-cpu
- transformers
- numpy
- whisper
- pillow
6. Python Implementation
6.1. Importing Libraries
Let’s import the packages and classes we need:
from llama_index.core import VectorStoreIndex, Document
from llama_index.llms.huggingface.base import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
import os
import glob
import cv2
from PIL import Image
import numpy as np
import PyPDF2
import faiss
import whisper
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import BlipProcessor, BlipForConditionalGeneration
from sentence_transformers import SentenceTransformer
6.2. Embedding
We use the pre-trained BLIP model for image and video-to-text mapping, the Whisper model for audio transcription, and the Sentence Transformer model for text embedding:
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
embedding_model = embedding_model.to('cpu')
blip_processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
blip_model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
audio_model = whisper.load_model("base")
6.3. Directory Structure
We store our data (PDF, audio, video, and images) in the corresponding folders. Here’s the directory structure:
.
|-- our Python script (llama_multimodal_search.py)
|-- source
| |-- audio (for wav files)
| |-- image (for jpg files)
| |-- pdf (for pdf files)
| `-- video (for mp4 files)
6.4. Data Storage for PDF Documents
For PDF documents, we extract all text and then store it in the document store:
def process_pdf(pdf_path):
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ''
for page_number in range(len(reader.pages)):
text += reader.pages[page_number].extract_text()
return text
document_store = []
def add_pdf(pdf_path):
text = process_pdf(pdf_path)
document_store.append({'type': 'pdf', 'content': text, 'path': pdf_path})
source_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), 'source')
pdf_path = os.path.join(source_path, 'pdf')
pdf_files = glob.glob(pdf_path + '/' + "*.pdf")
for file in pdf_files:
add_pdf(file)
6.5. Data Storage for Audio Files
For audio data (WAV, mp3), we use the Whisper model (base) to get its transcript and then store it in the document store:
def process_audio(audio_path):
result = audio_model.transcribe(audio_path, fp16=False)
text = result['text']
print(f"Audio Transcript: {text}")
return text
def add_audio(audio_path):
text = process_audio(audio_path)
document_store.append({'type': 'audio', 'content': text, 'path': audio_path})
audio_path = os.path.join(source_path, 'audio')
audio_files = glob.glob(audio_path + '/' + "*.wav")
for file in audio_files:
add_audio(file)
6.6. Data Storage for Images
For image files (jpg, png, etc.), we get their text descriptions (image description) and then add them to the document store:
def process_image(image_path):
try:
if isinstance(image_path, str):
image = Image.open(image_path)
elif isinstance(image_path, np.ndarray):
image = Image.fromarray(cv2.cvtColor(image_path, cv2.COLOR_BGR2RGB))
inputs = blip_processor(image, return_tensors="pt")
out = blip_model.generate(**inputs, max_new_tokens=256)
caption = blip_processor.decode(out[0], skip_special_tokens=True)
return caption
except Exception as e:
print(f"Error processing image {image_path}: {e}")
return None
def add_image(image_path):
description = process_image(image_path)
document_store.append({'type': 'image', 'content': description, 'path': image_path})
image_path = os.path.join(source_path, 'image')
image_files = glob.glob(image_path + '/' + "*.jpg")
for file in image_files:
add_image(file)
6.7. Data Storage for Videos
For video files (mp4, mkv), we first uniformly extract frames (visuals) for video data and convert them to their text description (image description). After that, we concatenate all image descriptions:
def process_video(video_path):
captions = []
try:
cap = cv2.VideoCapture(video_path)
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if frame_count % 30 == 0: # Process one frame every second (adjust as needed)
caption = process_image(frame)
if caption:
captions.append(caption)
frame_count += 1
cap.release()
return " ".join(captions)
except Exception as e:
print(f"Error processing video {video_path}: {e}")
return None
def add_video(video_path):
description = process_video(video_path)
document_store.append({'type': 'video', 'content': description, 'path': video_path})
video_path = os.path.join(source_path, 'video')
video_files = glob.glob(video_path + '/' + "*.mp4")
for file in video_files:
add_video(file)
6.8. Indexing and Search
Here’s the vanilla search (search the FAISS index with a query and return the top k results):
def create_faiss_index():
texts = [item['content'] for item in document_store if item['content'] is not None]
embeddings = embedding_model.encode(texts, device='cpu', convert_to_tensor=True)
embeddings = embeddings.cpu().numpy().astype('float32')
index = faiss.IndexFlatL2(embeddings.shape[1]) # L2 distance
index.add(embeddings)
files = [item['path'] for item in document_store if item['content'] is not None]
return index, texts, files
def search_faiss_index(query, index, texts, files):
query_embedding = embedding_model.encode(query, convert_to_tensor=True).numpy().astype('float32')
query_embedding = query_embedding.reshape(1, -1) # Reshape to (1, embedding_dimension)
D, I = index.Search(query_embedding, k=3) # Get top 3 results
results = [{'file_name': files[i], 'relevant_chunk': texts[i], 'distance': D[0][j]} for j, i in enumerate(I[0])]
return results
def multimodal_search(query):
results = []
index, texts, files = create_faiss_index() # Create the FAISS index
faiss_results = search_faiss_index(query, index, texts, files)
for result in faiss_results:
results.append(result)
return results
6.9. Integration With LlamaIndex
Now, we present the LlamaIndex augmented search:
def integrate_llamaindex(query):
small_model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(small_model_name)
llm_model = AutoModelForCausalLM.from_pretrained(small_model_name)
llm = HuggingFaceLLM(
context_window=512,
max_new_tokens=128,
generate_kwargs={"temperature": 0.95, "top_k": 50, "top_p": 0.95, "do_sample": False},
tokenizer=tokenizer,
model=llm_model,
tokenizer_name=small_model_name,
model_name=small_model_name,
device_map="auto",
tokenizer_kwargs={"max_length": 512, 'pad_token_id': tokenizer.eos_token_id},
)
Settings.chunk_size = 512
Settings.llm = llm
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
docs = []
for item in document_store:
docs.append(Document(text=item['content']))
if docs:
try:
index = VectorStoreIndex.from_documents(docs, show_progress=True)
except Exception as e:
print(f"Error creating index: {e}")
return []
query_engine = index.as_query_engine(verbose=True, similarity_top_k=3)
response = query_engine.query(query)
print(f"LlamaIndex Response as per its own sources: \n\n{response}\n")
return response
else:
print("No documents to index.")
return []
6.10. Queries Using FAISS and LlamaIndex
Let’s test our solution first with a simple textual query about cats over the index we created from our data sources:
query = "What is a cat?"
results = multimodal_search(query)
for result in results:
print(f"Matched in file: {result['file_name']} on text: {result['relevant_chunk']} with Distance: {result['distance']}")
Here are the results containing the matching file path, text, and distance (the smaller the distance, the higher the relevance):
Matched in file: <path>/source/pdf/dog.pdf on text: The cat (Felis catus), also referred to as domestic cat or house cat, is a small domesticated carnivorous mammal. It is the only domesticated species of the family Felidae... with Distance: 0.7035039663314819
Matched in file: <path>/source/image/cat3.jpg on text: a cat wearing a crown on its head with Distance: 0.911292552947998
Matched in file: <path>/source/image/cat2.jpg on text: a cat sitting on top of a box with Distance: 0.913367509841919
Now, we run the same query with LlamaIndex:
llama_response = integrate_llamaindex(query)
print(f"LlamaIndex Response as per its Own Konwledge: \n\n{str(llama_response)}\n")
print(f"\nLlamaIndex Response as per Our Data sources:\n")
for node_with_score in llama_response.source_nodes:
print(node_with_score.text)
print(node_with_score.score)
It will give us two types of results. First, it will search its own indexed documents and give us the most relevant result:
LlamaIndex Response as per its own sources: "A cat is a small, carnivorous mammal that is found in the wild. It is a member of the family Felidae.
Second, the LlamaIndex will query our data sources:
The cat (Felis catus), also referred to as domestic cat or house cat, is a small domesticated carnivorous mammal. It is the only domesticated species of the family Felidae.... 0.7459072102424552
Let’s change the query to “What is computer vision?.” As expected, the vanilla semantic search gave noncontextual results (audio files) with large distances:
Matched in file: <path>/source/audio/mixkit-dog-barking-twice-1.wav on text: Oop! Oop! with Distance: 1.6404740810394287
Matched in file: <path>/source/audio/mixkit-little-birds-singing-in-the-trees-17.wav on text: with Distance: 1.7246205806732178
Matched in file: <path>/source/image/dog3.jpg on text: a dog sitting on the floor looking up with Distance: 1.7639024257659912
However, LlamaIndex gave this response from its knowledge:
Computer vision is a method of visualizing objects in a way impossible with human vision.
7. Conclusion
In this article, we learned about LlamaIndex.
Pre-trained LLMs need more factual accuracy and current world knowledge to respond more coherently. LlamaIndex uses external knowledge to augment the capabilities of underlying pretrained LLMs.
LlamaIndex is increasingly used in legal applications, preventive healthcare, customer support, telecom, and academia.
As always, the code for this article is available over on GitHub.