1. Introduction
In this tutorial, we’ll study speech synthesis using the WaveNet model. This was released by Google DeepMind in 2016.
2. Text to Speech
Speech synthesis or Text-to-speech (TTS) is the ability of machines to synthesize human-like speech. Traditional TTS methods include concatenative and parametric synthesis:
In the concatenative approach, we record speech and cut the recordings into smaller units to form an extensive database of speech chunks. Next, we stitch the corresponding speech units for any unseen text to produce new speech. On the other hand, Parametric methods or vocoders simulate the human vocal tract based on a parametric (function with a set of arguments) physical model. Thereafter, we use the recorded speech to adapt these parameters.
The deep learning approach is a recent technique that uses machine or deep learning models for natural-sounding speech synthesis depicting various speaking styles and emotions.
3. WaveNet Model
WaveNet is an autoregressive deep generative model that takes as input raw audio and generates human-like speech with high accuracy and cohesiveness.
3.1. Intuition Behind WaveNet
The idea behind WaveNet is to extract acoustic features such as Mel Spectogram (visual representation of an audio signal’s frequency spectrum over time) from given audio speech and then pass these features in a long, well-defined convolution backbone. These features go through convolution blocks in the network. In the process, the model learns rules on the evolution of the audio waveform. Afterward, use the trained model to create new speech-like waveforms.
3.2. Generative Modeling
We define a model  as generative if tries to learn the true probability distribution
as generative if tries to learn the true probability distribution  from where the given input data points are sampled. then generates new data points using the . can learn in two ways:
from where the given input data points are sampled. then generates new data points using the . can learn in two ways:
- Implicit modeling
- Explicit modeling
is implicit if it learns from the input data points and later uses it to sample new data points without explicitly defining . Generative adversarial network (GAN) belongs to this category.
On the other hand, is explicit if it defines the probability distribution explicitly (a multidimensional isotropic Gaussian) and then fits the input data points to this distribution. WaveNet is an explicit generative model.
3.3. WaveNet Objective
WaveNet is an autoregressive model.
Let’s consider a audio stream  with
with  smples. WaveNet takes the joint probability distribution of the data stream as the product of element-wise conditional distributions for each element
smples. WaveNet takes the joint probability distribution of the data stream as the product of element-wise conditional distributions for each element  in the stream:
in the stream:
![[ p(A) = \prod^{N}_{t=1} p(a_{t}| a_{1}, a_{2}, \ldots, a_{t-1}) ]](/wp-content/ql-cache/quicklatex.com-9fa3bdce3ae542adbeb07faec1061a68_l3.svg "Rendered by QuickLaTeX.com")
Since probability values are minimal and their product generally results in underflow, we move to the log scale:
![[ \log(p(A)) = \sum^{N}_{t=1} \log(p(a_{t}| a_{1}, a_{2}, \ldots, a_{t-1})) ]](/wp-content/ql-cache/quicklatex.com-e5c96722f3cf4632f9a1c9f5db00f798_l3.svg "Rendered by QuickLaTeX.com")
4. WaveNet Architecture
WaveNet is a feed-forward network (FFN) having a convolution backbone (CNN) with skip residual connections:
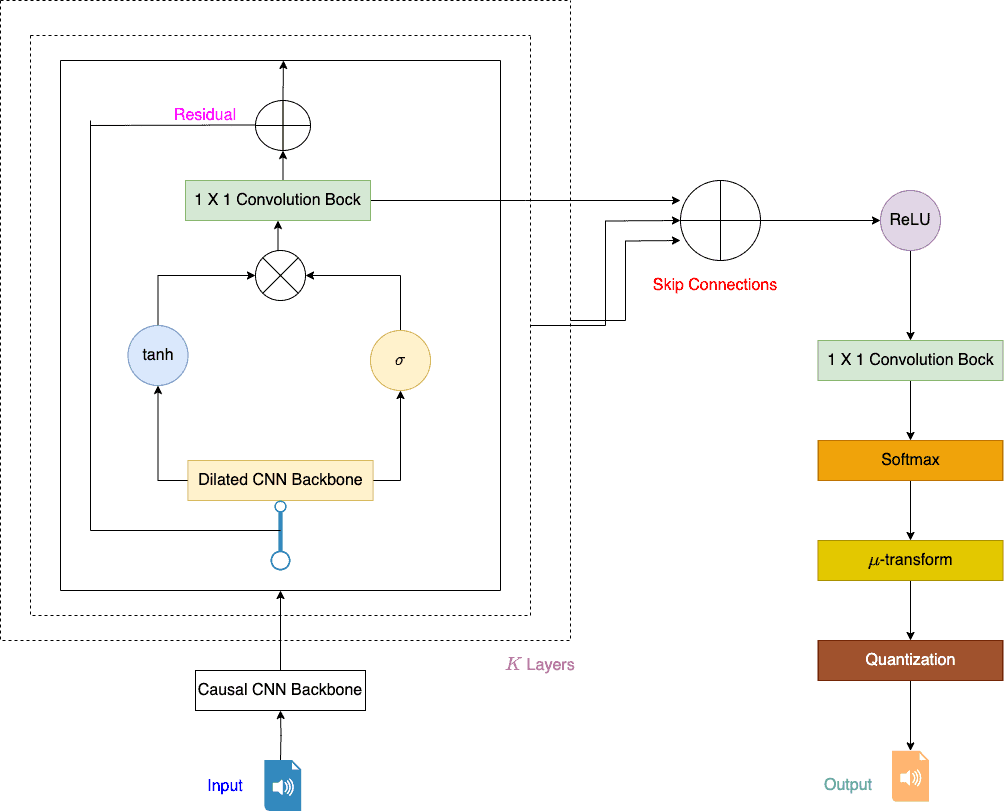
4.1. Description
In WaveNet, we give raw acoustic signals from audio to the CNN. So, we process it layer by layer. Next, we synthesize an output one sample at a time in an autoregressive manner. Finally, we apply the softmax function over the output to get a signal distribution stored as 16-bit integers ( values).
values).
4.2. Dilate Causal CNN
Since WaveNet is autoregressive and works on temporal data, we use a causal CNN backbone instead of vanilla CNN:
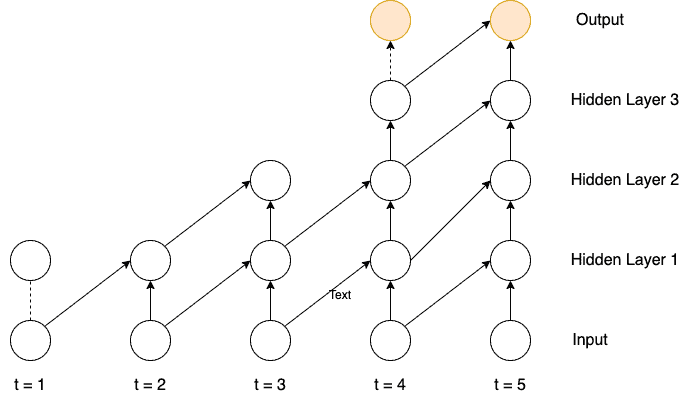
We increase the receptive field size in dilated convolutions by filtering a larger area than its length. We then skip input values with a specific step. For WaveNet, we stack multiple dilated convolution layers over the other to have vast receptive fields.
4.3. Softmax Layer
We pass the model output to the softmax layer to output the probability distribution of the input audio signal. We sample audio signals, convert them into Mel Spectograms, and store them as a sequence of 16-bit integer values. Softmax layer will output values at each time step, making it computationally hard. So, we lower the bit-depth from 16 to 8 non-linearly.
4.4. Activation Function
Like other DNNs, WaveNet also uses non-linear activation functions to learn complex relationships between output and input. So, we use tan-hyperbolic gated with sigmoid activation for WaveNet:
![[ z = \tanh\left(W_{f, k} * x\right) \odot \sigma(W_{g, k} * x) ]](/wp-content/ql-cache/quicklatex.com-a74171cb09a144fffa209c286660fe92_l3.svg "Rendered by QuickLaTeX.com")
Here, we represent conv filters by  , convolution operation by
, convolution operation by  , and element-wise matrix multiplication by
, and element-wise matrix multiplication by  .
.
4.5. Residual and Skip Connection
WaveNet uses both residual and parameterized skip connections in the network. Residual connection over layer  adds the original input to the output of , whereas skip connection merges or concatenates features from different layers. These add-ons, when used in a deep neural network, help regulate gradient flow and ease the overall training process.
adds the original input to the output of , whereas skip connection merges or concatenates features from different layers. These add-ons, when used in a deep neural network, help regulate gradient flow and ease the overall training process.
5. WaveNet Implementation
Let’s look at music generation using the WaveNet model in Python using PyTorch.
5.1. Music Generation Using WaveNet
We’ll use PyTorch for model creation, tensorboard to capture runtime visualization, and then use this trained model for automatic music generation. So, we first train the WaveNet model on a dataset consisting of instrument recording (no speech). For the dataset, we combined all audio files into a single file (numpy binary format) and then used it for training this model for a single iteration.
Once the model is trained, we give a small portion of raw audio as a starting seed. Then we let the model generate a new music piece for 16000 samples (10 sec):
model.eval()
start_data = data[250000][0]
start_data = torch.max(start_data, 0)[1]
generated = model.generate_fast(num_samples=160000,
first_samples=start_data,
progress_callback=prog_callback,
progress_interval=1000,
temperature=1.0,
regularize=0.)
sf.write('latest_generated_clip.wav', generated, 16000, 'PCM_24')
Here is the Mel spectrogram of the newly generated music file. Since our model is trained for only 1 epoch, we can see a small portion of audio waves (green/blue color) amidst noise (violet) :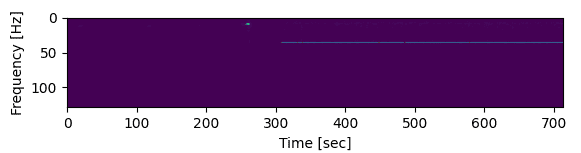
5.2. Speech Generation Using WaveNet
We can use the WaveNet model for text-to-speech generation. Here, we provide the model with input text. Then, we transform the text into linguistic and phonetic features series. This series gives our model all the information at the granular level (current phoneme, syllable, word, etc.) Post this, we feed this series to the model for speech generation. Due to its autoregressive nature, the WaveNet model synthesizes speech conditioned for a new text not only on the previous audio samples but also on the current word.
6. Conclusion
In this article, we’ve learned the WaveNet speech synthesis model.
WaveNet is a generative deep-learning model that synthesizes speech autoregressively. It captures the long temporal dependencies well and trains fast due to its parallel architecture. On the shadow side, we find WaveNet slower on inference. This is because it is inherently sequential due to its autoregressive nature. On the sunny side, WaveNet has enormous applications in speech synthesis, music generation, and audio modeling.