1. Introduction
In this tutorial, we’ll explain the mathematics and intuition behind the family of Beta distributions in statistics and analyze their shapes.
2. Intuition
Let’s say we flip a fair coin 10 times and bet on tails with our friend. Since heads and tails are equally likely each time, our win probability in each toss is 1/2.
Then, the number of tails in 10 flips follows the binomial distribution centered at (1/2) * 10 = 5:
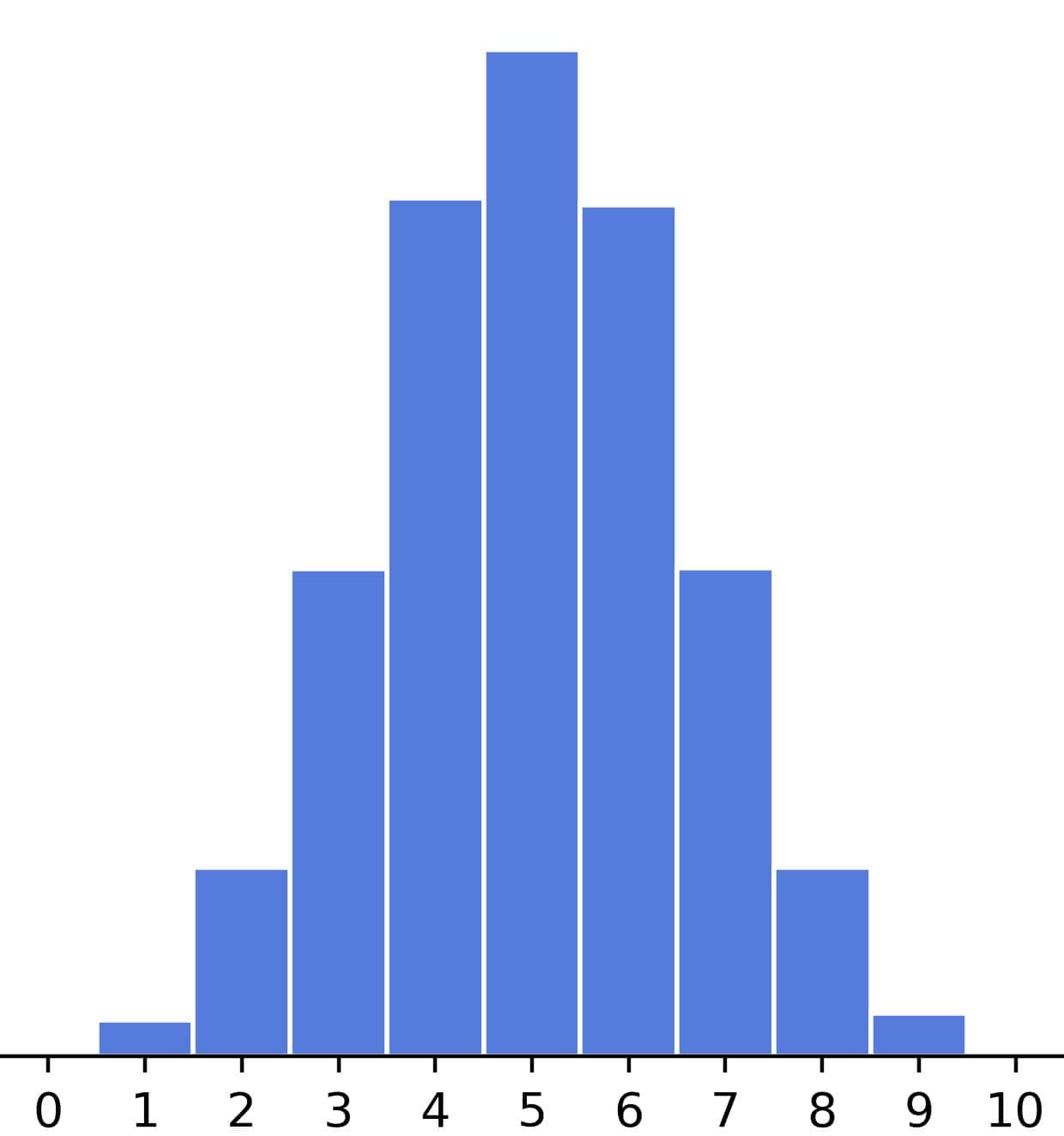
From there, we can derive how much we can expect to win in this game and decide how much money to bet.
However, what if the question is reversed? We flip a coin 10 times and get eight wins. We may be delighted with the financial gain, but our friend, not so much, so we get accused of using a biased coin.
To resolve the dispute, we must determine the coin’s inherent probability of landing on its tails in a random toss. This is precisely what Beta distributions can do.
The Beta distribution with parameters  and
and  shows how much each
shows how much each ![\boldsymbol{x \in [0, 1]}](/wp-content/ql-cache/quicklatex.com-d2716e514d830c16ae378f0dd775f7f2_l3.svg "Rendered by QuickLaTeX.com") is likely as the success probability, given that there were
is likely as the success probability, given that there were  successful and
successful and  unsuccessful trials.
unsuccessful trials.
3. Density
Beta-distributed random variables are defined over [0, 1] and have the following density:
![[f(x; a, b) = C x^{a-1} (1-x)^{b-1} \quad 0 \leq x \leq 1 \text{ and } a,b > 0]](/wp-content/ql-cache/quicklatex.com-2d1485570e2bb3fa499cea7c02f4aab4_l3.svg "Rendered by QuickLaTeX.com")
The constant  ensures that the cumulative distribution function is 1 for
ensures that the cumulative distribution function is 1 for  :
:
![[1 = \int_{0}^{1}f(x; a, b)dx = C \int_{0}^{1} x^{a-1} (1-x)^{b-1} dx = C \cdot B(a, b) \implies C = \frac{1}{B(a, b)}]](/wp-content/ql-cache/quicklatex.com-5be05906ece98d776965652efa0c5432_l3.svg "Rendered by QuickLaTeX.com")
where  is the beta function:
is the beta function:
![[B(a, b) = \frac{\Gamma(a) \Gamma(b)}{\Gamma(a + b)} \qquad \Gamma(u) = \int_{0}^{\infty}t^{u-1}e^{-t}dt]](/wp-content/ql-cache/quicklatex.com-2479d687be7b30800789034f0164703d_l3.svg "Rendered by QuickLaTeX.com")
Therefore, the density is:
![[f(x; a, b) = \frac{1}{B(a, b)}x^{a-1}(1-x)^{b-1}]](/wp-content/ql-cache/quicklatex.com-dfa340437ccdaf769914fc524d9e6913_l3.svg "Rendered by QuickLaTeX.com")
3.1. Why Is There -1?
Essentially, the -1 in the exponents comes from the -1 in the integrand of the Gamma function.
We can try to find some intuition in it using the measure theory.
The CDF of the Beta distribution with parameters  and
and  is:
is:
![[F(t; a, b) = \int_{0}^{t}f(x; a, b)dx = \int_{0}^{t}\frac{1}{B(a, b)}x^{a-1}(1-x)^{b-1}dx]](/wp-content/ql-cache/quicklatex.com-485e2ac9d0a837335ea8dca7a34b03c0_l3.svg "Rendered by QuickLaTeX.com")
Let’s move -1 to the denominator:
![[F(t; a, b) = \int_{0}^{t}\frac{1}{B(a, b)}\frac{x^{a}}{x}\frac{(1-x)^{b}}{1-x}dx = \int_{0}^{t}\frac{1}{B(a, b)}x^{a}(1-x)^{b}\frac{dx}{x(1-x)}]](/wp-content/ql-cache/quicklatex.com-c637a7e8f85dd1ad42458f712d2f1b28_l3.svg "Rendered by QuickLaTeX.com")
Now, we have:
![[\frac{dx}{x(1-x)} = d\left( \log \frac{x}{1-x} \right) = d\mu(x) \text{ for } \mu(x) = \log\frac{x}{1-x}]](/wp-content/ql-cache/quicklatex.com-402dbda2fde40fc87fa4fc9eb79d10d4_l3.svg "Rendered by QuickLaTeX.com")
As a result, we can transform the CDF to:
![[\int_{0}^{t}\frac{1}{B(a, b)}g(x; a, b)d\mu(x) \quad g(x)=x^{a}(1-x)^{b}]](/wp-content/ql-cache/quicklatex.com-107c03a8d1e8c7ddf9ac756a031bf7cb_l3.svg "Rendered by QuickLaTeX.com")
where the density  doesn’t have -1 in the exponents, and and are the numbers of successful and unsuccessful trials.
doesn’t have -1 in the exponents, and and are the numbers of successful and unsuccessful trials.
Intuitively, if we weigh each probability  with the logarithm of the corresponding odds ratio, we can use this interpretation of and . In more technical terms, the density is defined with respect to the measure
with the logarithm of the corresponding odds ratio, we can use this interpretation of and . In more technical terms, the density is defined with respect to the measure  .
.
3.2. Non-Integer Parameters
The parameters and can be non-integers. However, the intuitive explanation was that  and
and  denote the numbers of successful and unsuccessful trials (or and if we use the measure ). How do we interpret a fractional or ?
denote the numbers of successful and unsuccessful trials (or and if we use the measure ). How do we interpret a fractional or ?
Sometimes, the boundary between success and failure is clear-cut. For example, an experiment (a trial) can have several goals. Achieving some while failing at others constitutes partial success. To allow for this nuanced approach to evaluation, we use non-integers and .
4. Properties
Let’s now check some properties of this distribution family.
4.1. Mean
The mean of a Beta distribution with parameters and is:
![[\int_{0}^{1}xf(x; a, b) dx= \frac{1}{B(a, b)}\int_{0}^{1}x^{a}(1-x)^{b-1}dx = \frac{B(a+1, b)}{B(a, b)}]](/wp-content/ql-cache/quicklatex.com-c80b735b7499616d700d19555fc82886_l3.svg "Rendered by QuickLaTeX.com")
To simplify the expression, we’ll write using the Gamma function  and note that
and note that  :
:
![[\frac{B(a+1, b)}{B(a, b)} = \frac{\frac{\Gamma(a+1) \Gamma(b)}{\Gamma(a+b+1)}}{\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)}} = \frac{\frac{a \Gamma(a)}{(a+b)\Gamma(a+b)}}{\frac{\Gamma(a)}{\Gamma(a+b)}} = \frac{a}{a+b}]](/wp-content/ql-cache/quicklatex.com-ec160d571b5e8a08484e292e19943ae4_l3.svg "Rendered by QuickLaTeX.com")
If  , the mean is 1/2. If
, the mean is 1/2. If  , the distribution’s center is shifted to the right and to the left if
, the distribution’s center is shifted to the right and to the left if  .
.
This has an intuitive explanation. If there are many successful outcomes, it makes sense to believe that the probability of success is higher and vice versa.
4.2. Variance
We can similarly compute the variance:
![[\frac{ab}{(a+b)^2 (a+b+1)}]](/wp-content/ql-cache/quicklatex.com-83cf6c86015432d0fcba18b55434c02a_l3.svg "Rendered by QuickLaTeX.com")
The larger and , the smaller the variance. That is also intuitive. The more experiments we conduct, the more we know about the success probability, so the distribution we use as its model should be less variable.
4.3. Skewness
The skewness of a distribution quantifies its deviation from symmetry. In the case of a beta distribution with shape parameters and , the skewness is:
![[\frac{2(b-a)\sqrt{a+b+1}}{(a+b+2)\sqrt{ab}}]](/wp-content/ql-cache/quicklatex.com-3c04fa2ddbb823ac6e9011d7bce03f8d_l3.svg "Rendered by QuickLaTeX.com")
So, for  , the distribution is symmetric, right-skewed for
, the distribution is symmetric, right-skewed for  , and left-skewed for
, and left-skewed for  .
.
This also has an intuitive explanation. If the number of successes equals the number of unsuccessful trials, there are no grounds to believe the true success probability is more likely to be > 1/2 than < 1/2, and vice versa. A symmetric distribution fits this assertion.
By the same logic, if  , successful trials are a majority, so it’s reasonable to believe that the true success probability is > 1/2. The right model for this assertion is a distribution centered around a value > 1/2. However, the remaining tail stretching to 0 makes the distribution left-skewed. The converse holds for .
, successful trials are a majority, so it’s reasonable to believe that the true success probability is > 1/2. The right model for this assertion is a distribution centered around a value > 1/2. However, the remaining tail stretching to 0 makes the distribution left-skewed. The converse holds for .
4.4. Kurtosis
The formula for the excess kurtosis is a bit more complex:
![[\frac{6\left((a-b)^2(a+b+1) - ab(a+b+2) \right)}{ab(a+b+2)(a+b+3)}]](/wp-content/ql-cache/quicklatex.com-94a31a373d38f38a36f31068c7dd47af_l3.svg "Rendered by QuickLaTeX.com")
Negative values indicate tails lighter than those of the normal distribution, and positive values indicate heavier tails. The exact effect on the shape depends on the values of other moments (that are, in turn, defined by and ).
4.5. Mode
The mode of a distribution is its most likely value, i.e., the value with the highest density.
So, to compute it, we need to find ![x \in [0, 1]](/wp-content/ql-cache/quicklatex.com-123604f52804a7c71ff6ab0465c641cc_l3.svg "Rendered by QuickLaTeX.com") that maximizes the density
that maximizes the density  . Setting the first derivative of to zero and solving for , we get that the mode is:
. Setting the first derivative of to zero and solving for , we get that the mode is:
![[\frac{a-1}{a+b-2}]](/wp-content/ql-cache/quicklatex.com-f17585b0d79f64b65337bddef0d72e06_l3.svg "Rendered by QuickLaTeX.com")
For a symmetric distribution, , and the mode is equal to the mean:
![[\frac{a-1}{a+a-2}=\frac{a-1}{2(a-1)}=\frac{1}{2}]](/wp-content/ql-cache/quicklatex.com-25f90e1368a4b17bef84caac01868e26_l3.svg "Rendered by QuickLaTeX.com")
5. Shapes
Depending on the values of and , the Beta density can take many shapes.
5.1. Symmetric Shapes
Symmetric shapes have , and we differentiate between three cases:
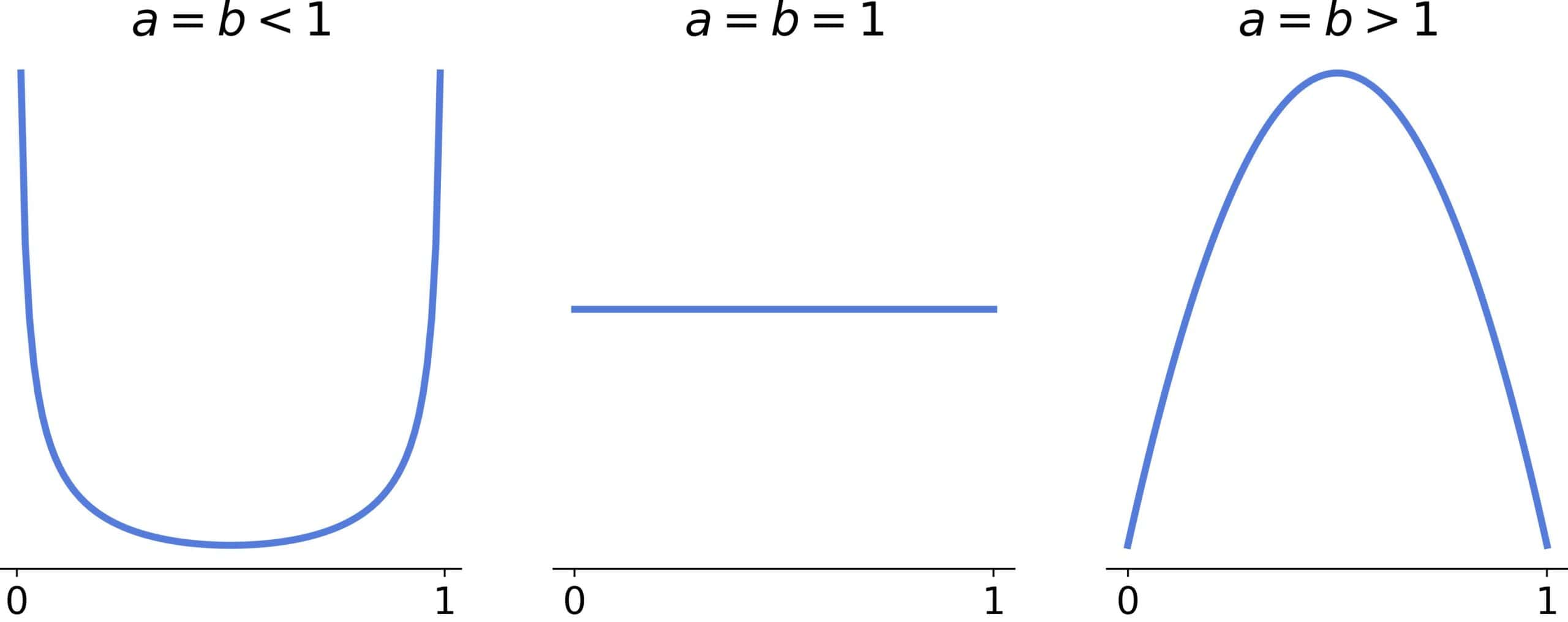
The special case  corresponds to the uniform distribution.
corresponds to the uniform distribution.
If  , the distribution is U-shaped, and if
, the distribution is U-shaped, and if  , it’s bell-shaped and approaches the normal distribution as and increase:
, it’s bell-shaped and approaches the normal distribution as and increase:
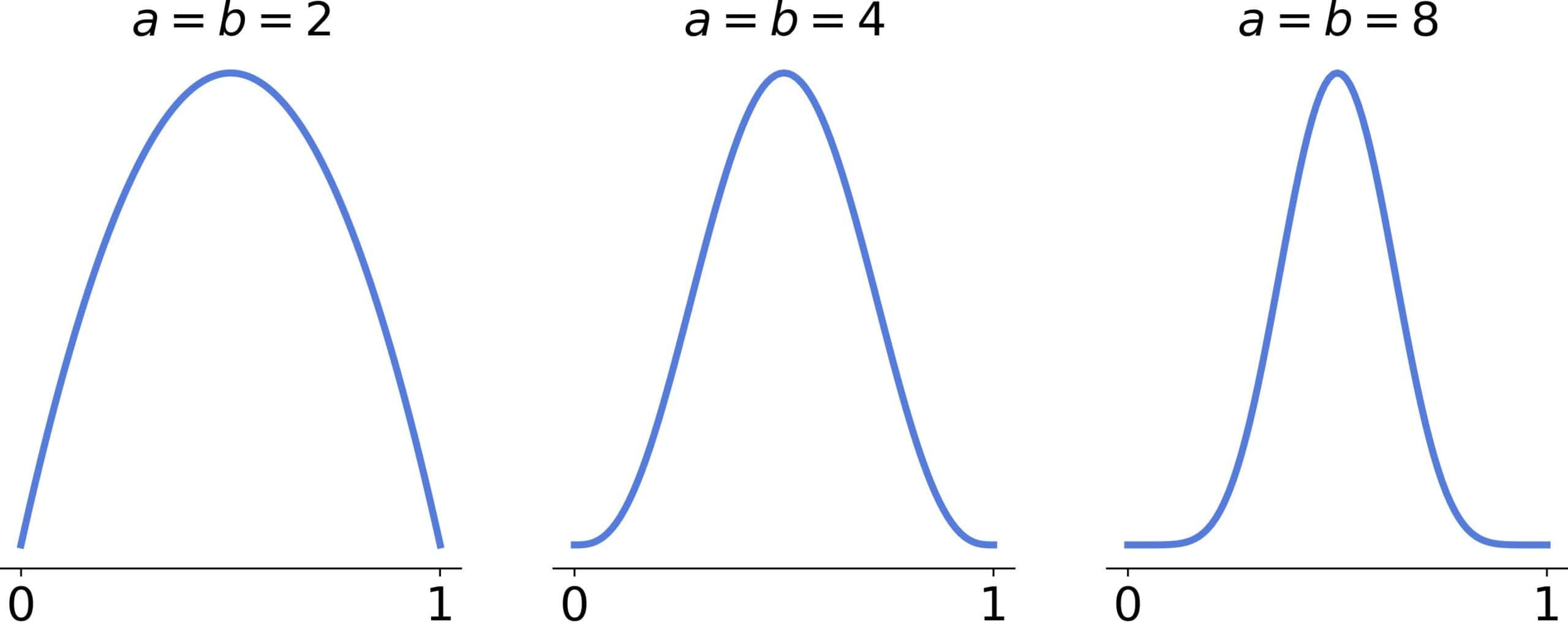
There will be two inflection points if  .
.
5.2. Asymmetric Shapes
For asymmetric shapes, corresponds to right-skewed, and to left-skewed distributions.
If both , the distribution will be convex, approaching an L-shape (reversed or not) as the larger parameter approaches 1:
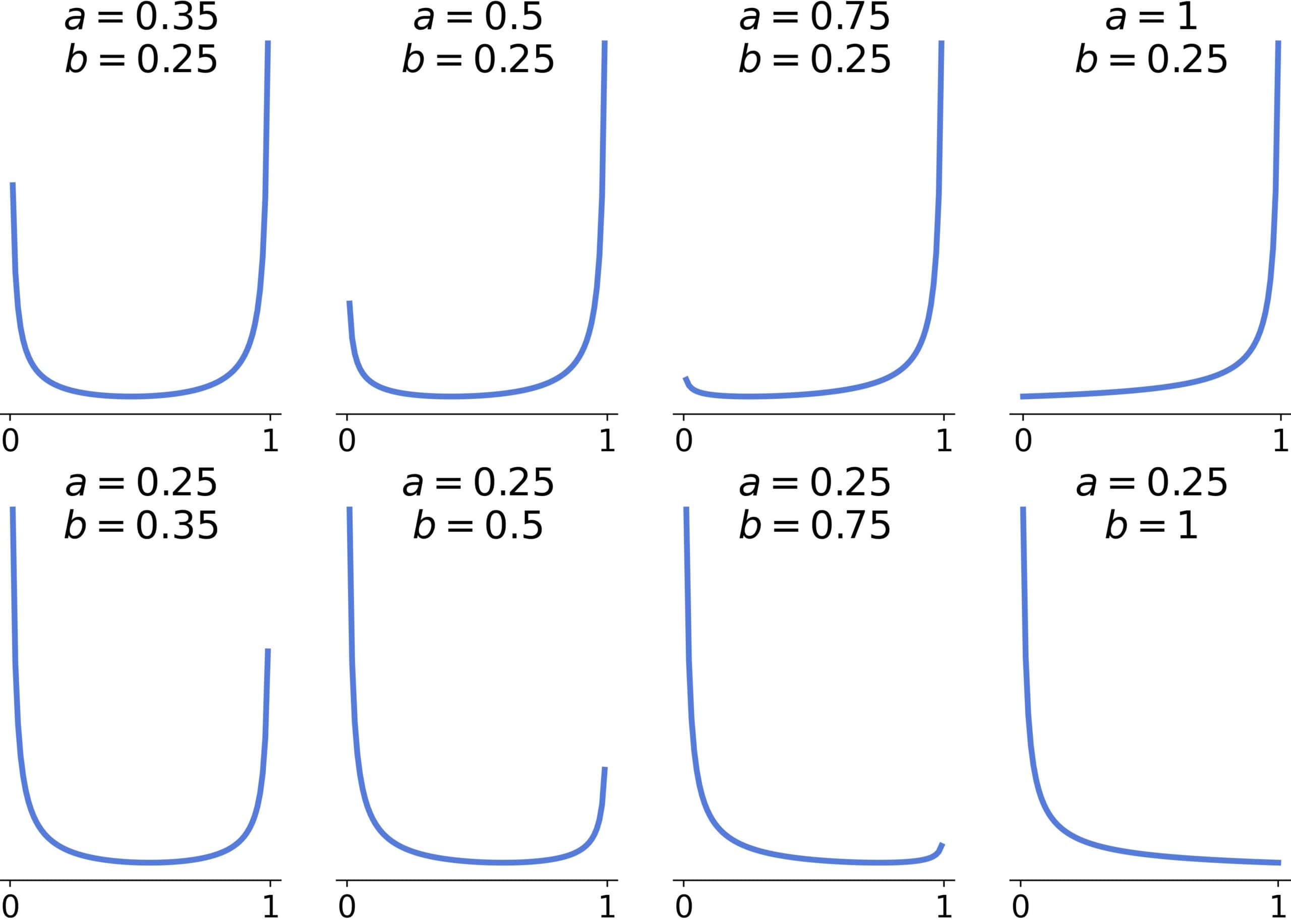
If , the distribution will be unimodal, and the tail heaviness will decrease as the parameters’ difference grows. There will be one inflection point if one parameter is >2 and two inflection points if both are >2:
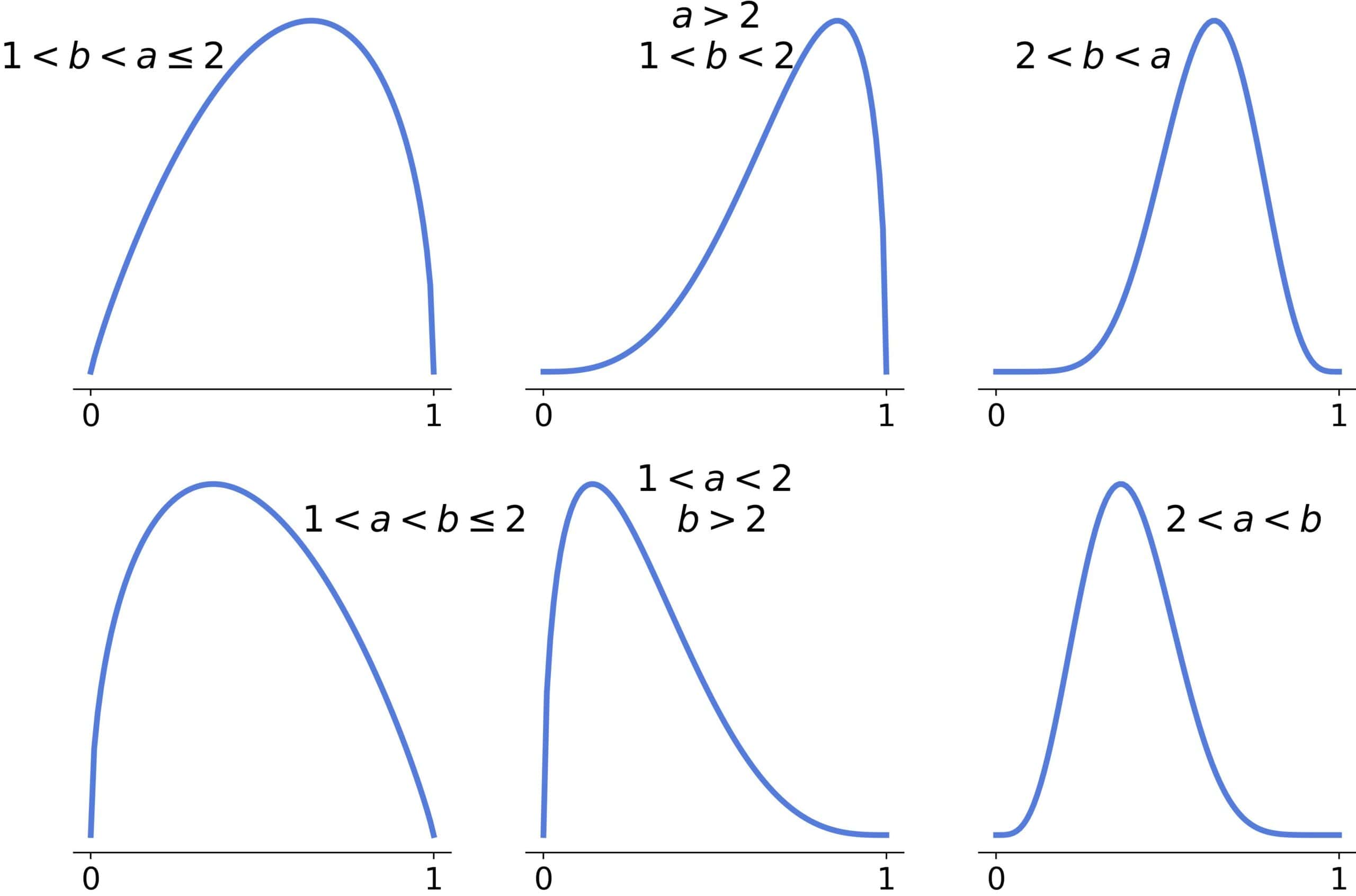
If  and
and  or if
or if  and
and  , the shape will be convex or with one inflection point:
, the shape will be convex or with one inflection point:
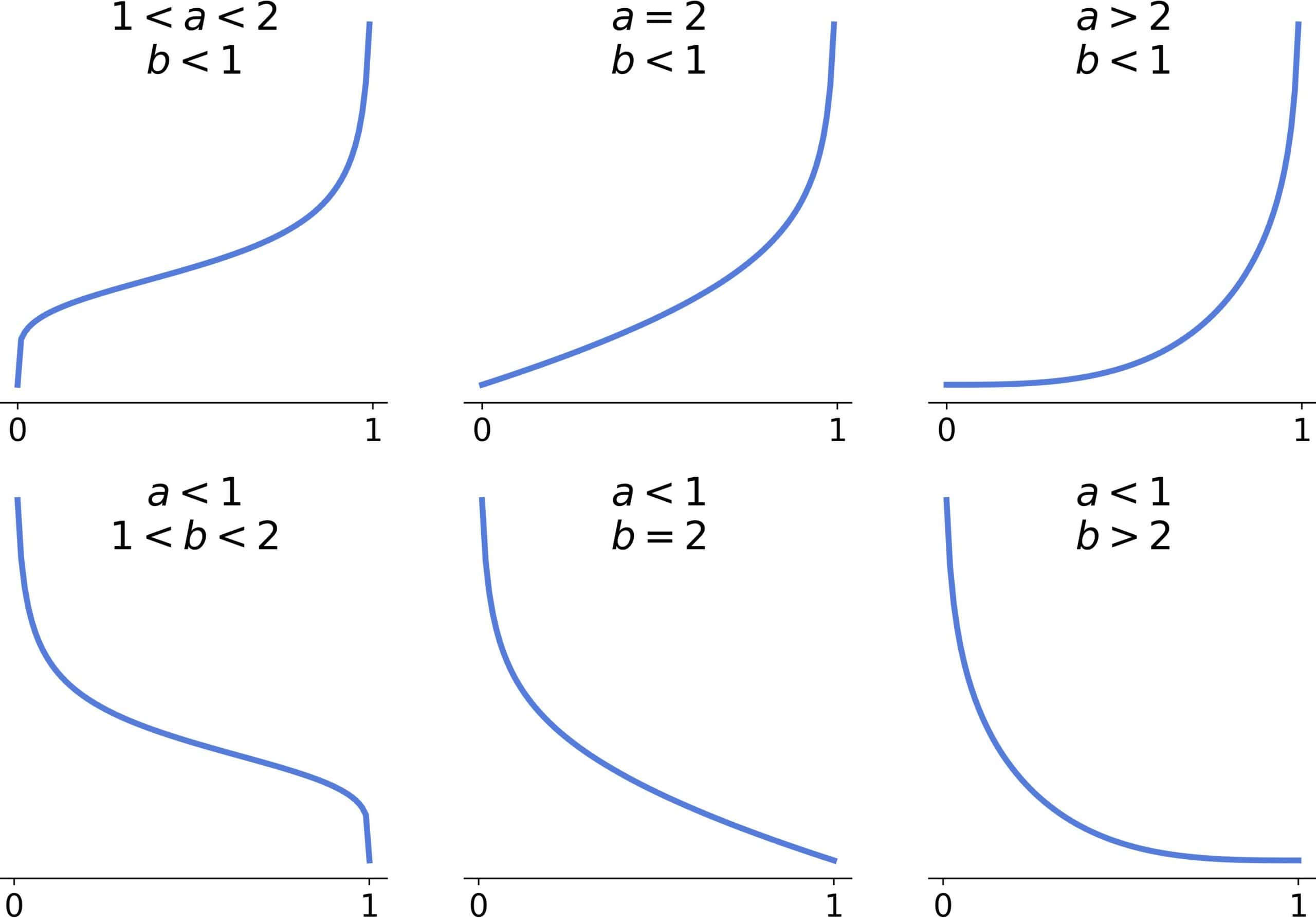
The inflection point will be there if  .
.
The last remaining cases are  and
and  :
:
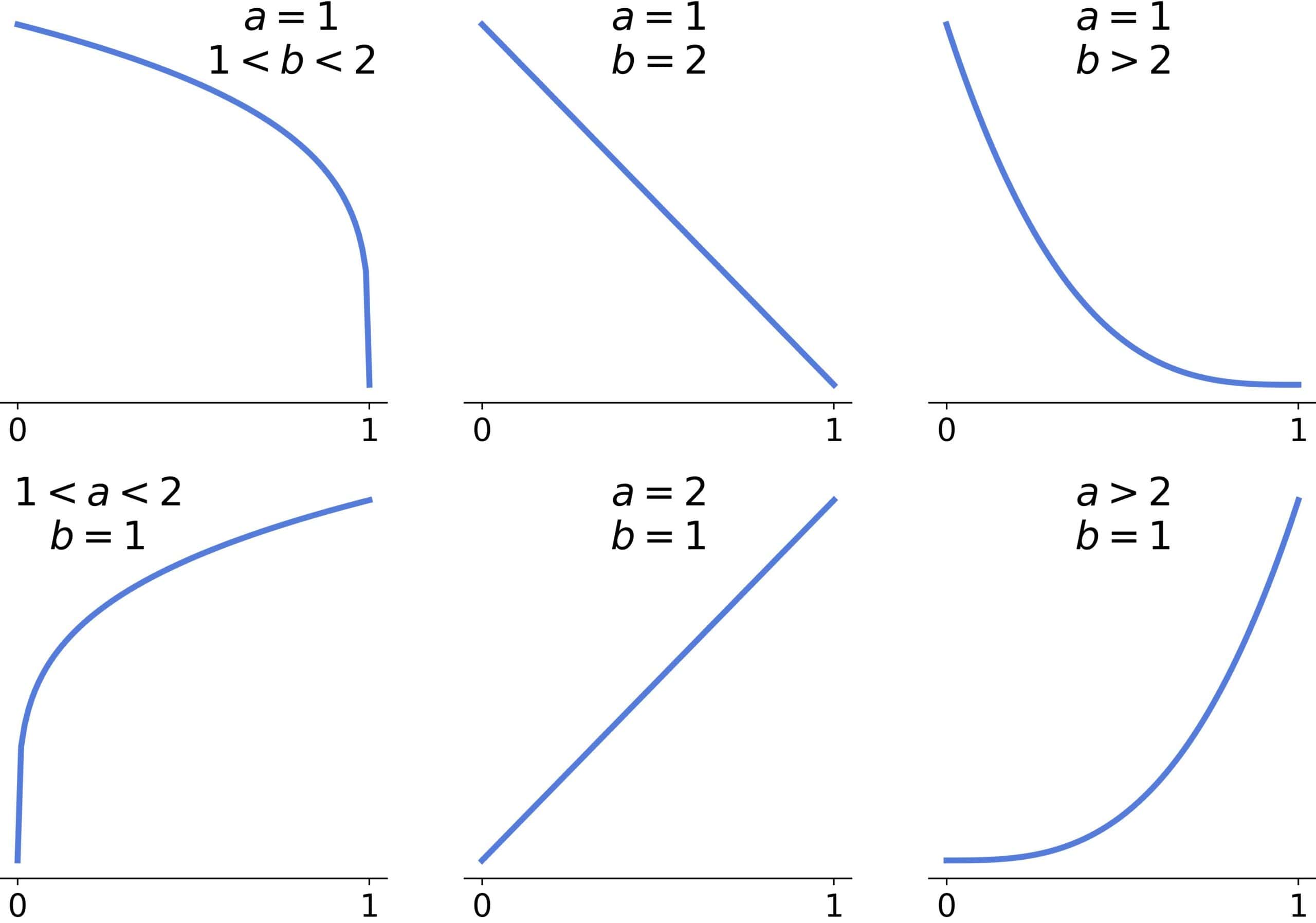
We have a straight line if the larger parameter equals two, a concave curve if it’s <2, and a convex one if it’s >2.
6. Conclusion
In this article, we discussed the family of Beta distributions in statistics. These distributions are defined over [0, 1] and can take many shapes, making them suitable for modeling normalized quantities (such as probabilities).