1. Overview
In computer architecture, hazards represent conditions that disrupt the smooth execution of instructions, often impacting the performance and efficiency of a processor’s pipeline. Data and structural hazards are two classes of hazards that can lead to stalls, or even incorrect execution, if not managed properly. Having a solid understanding of these hazards is essential for optimizing instruction pipelines.
In this tutorial, we’ll explore structural and data hazards in depth, comparing their causes, effects, and the best ways to mitigate them.
2. Instruction Pipeline Hazards
An instruction pipeline processes multiple instructions concurrently by dividing execution into stages, such as fetching, decoding, executing, and writing back. Ideally, each pipeline stage handles a different instruction per clock cycle, accelerating overall execution. However, pipelines can encounter conflicts or hazards that prevent instructions from processing as intended.
In general, three types of hazards may occur in computer architecture.
The first type is structural hazards, which arise from conflicts over hardware resources. These conflicts can occur when multiple instructions attempt to access the same resource simultaneously.
The second type is data hazards, which result from dependencies between instructions. These dependencies can lead to situations where one instruction must wait for the result of a previous instruction before it can proceed.
Finally, there are control hazards, which relate to changes in control flow, such as branch instructions. These hazards occur when the program execution path changes, potentially leading to delays in instruction processing.
We’ll compare structural and data hazards by exploring how they arise, their impact on the pipeline, and effective mitigation strategies.
3. What Are Structural Hazards?
Structural hazards occur when two or more instructions simultaneously require the same hardware resources. This conflict is common in pipelines where multiple stages might need access to shared resources like memory, registers, or ALUs (arithmetic logic units).
3.1. Example of a Structural Hazard
For instance, consider a pipeline that fetches instructions and loads data using a single memory unit. If one instruction requires data to be fetched while another needs to fetch its next instruction, they might conflict, creating a structural hazard:
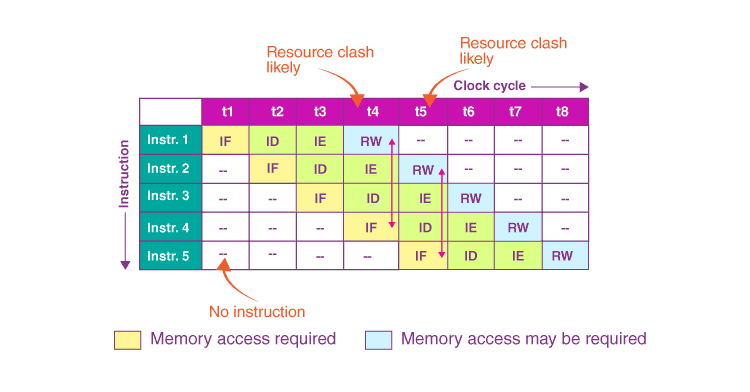
This image is part of Byju’s article on structural hazards (source). This hazard can result in a pipeline stall, causing the processor to pause and delay the execution of instructions until the required resource becomes available.
3.2. Causes and Effects of Structural Hazards
Structural hazards arise from limited hardware resources, which leads to conflicts, especially when functional units, like ALUs, cannot support simultaneous execution. Additionally, using a single memory module for instructions and data introduces bottlenecks, as it restricts memory access to one instruction at a time. Furthermore, poor allocation or design of hardware resources can exacerbate these issues, causing repeated conflicts and negatively impacting pipeline performance.
On the other hand, some effects of structural hazards include pipeline stalls, which increase latency and slow instruction throughput. Extra cycles spent waiting for resources will reduce pipeline efficiency. Finally, designing hardware to detect and manage conflicts significantly complicates the pipeline due to complex hazard-handling logic.
3.3. Solutions to Structural Hazards
Several strategies can be implemented to overcome structural hazards. First, adding additional resources, such as multiple Arithmetic Logic Units (ALUs) or separate memory units for data and instructions, helps to reduce structural hazards by minimizing resource conflicts.
Additionally, proper instruction scheduling can prevent conflicts by spacing out those that utilize the same resources, ensuring a smoother execution flow. Moreover, static and dynamic pipeline scheduling enables some processors to avoid conflicts by scheduling instructions at compile time or adjusting them at runtime.
Finally, implementing out-of-order execution enables the execution of instructions in an alternative order, thereby avoiding resource conflicts. However, this approach requires complex hardware to manage the reordering of instructions effectively.
In the next section, we’ll look at data hazards and how they compare to structural hazards.
4. What Are Data Hazards?
In contrast to structural hazards, data hazards arise when instructions depend on the results of preceding instructions. These hazards occur in pipelines when an instruction attempts to use a register or memory location that a preceding instruction hasn’t yet updated:
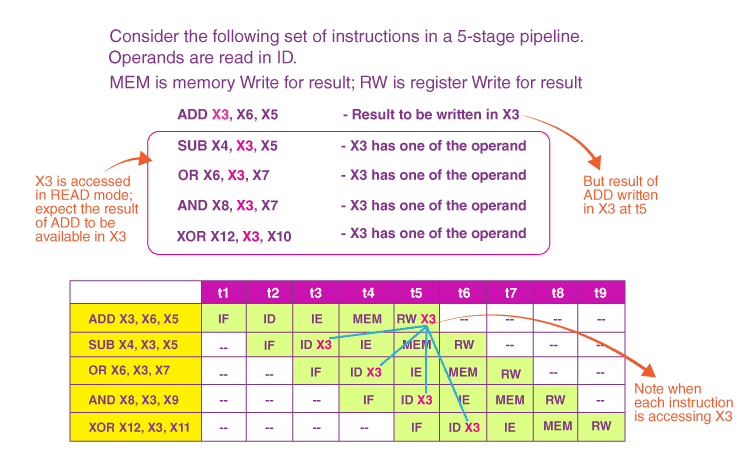
This image is part of Byju’s article on data hazards (source). Data hazards can be classified into three types. Read After Write (RAW) happens when an instruction relies on the result of a prior instruction. For example, if instruction #1 writes to a register and instruction #2 reads from that register before instruction #1 completes.
Write After Read (WAR) occurs when an instruction writes to a location after a previous instruction has read it. While rare in simpler pipelines, WAR is more common in complex systems with out-of-order execution.
Finally, Write After Write (WAW) arises when two instructions write to the same location. If the writing order isn’t preserved, the final value may depend on the execution order, leading to inconsistencies.
4.1. Effects of Data Hazards
Data hazards can significantly affect pipeline performance in various ways. First, they lead to stalls and delays, as the pipeline must wait for data to become available before proceeding. Moreover, they increase system complexity, since detecting and managing data dependencies requires additional hardware, complicating the overall design.
Additionally, if data hazards are not properly managed, potential data corruption can occur, resulting in incorrect values that affect program accuracy.
We can now discuss some solutions to data hazards.
4.2. Solutions to Data Hazards
Data forwarding, also known as data bypassing, allows the output of one instruction to be used as input for another, without waiting for the first instruction to complete. This significantly reduces the impact of Read After Write (RAW) hazards.
Additionally, pipeline stalling can be implemented by introducing delays until the required data becomes available; however, this method can reduce overall pipeline efficiency.
Another effective technique is register renaming, which involves using different physical registers for logically identical variables. This approach can eliminate Write After Read (WAR) and Write After Write (WAW) hazards by allowing each instruction to operate with a unique register.
Finally, out-of-order execution is an advanced technique that enables instructions to be executed in an order that respects data dependencies. However, sophisticated hardware is required to manage the process effectively.
Let’s now look at the differences between structural hazards and data hazards.
5. Differences Between Structural Hazards and Data Hazards
Let’s summarize the main differences between structural and data hazards in a table:
Aspect
Structural Hazards
Data Hazards
Cause
Resource conflicts due to hardware limitations
Data dependencies between instructions
Occurrence
When hardware resources are shared or insufficient
When instructions depend on previous instructions’ output
Impact on Pipeline
Causes stalls, reducing instruction throughput
Causes stalls; may lead to incorrect data if unmanaged
Primary Solution
Adding resources or out-of-order execution
Data forwarding, stalling, and register renaming
Common in
Pipelines with limited resources
Pipelines with data-dependent instructions
Examples
Single-port memory access by fetch and load
RAW, WAR, and WAW dependencies
While we should strive to mitigate both types of hazards, the table illustrates how each one has a different effect on the execution of instructions in the processor’s pipline.
6. Managing Hazards in Modern Processors
Fortunately, modern processors employ various techniques to manage structural and data hazards to maximize instruction throughput and minimize latency.
They avoid structural hazards using redundant resources, such as multiple ALUs or split memory banks. When duplicating hardware resources is impractical, dynamic instruction scheduling and out-of-order execution can reorder instructions to avoid conflicts.
On the other hand, advanced processors manage data hazards with methods like data forwarding, which passes data directly to dependent instructions as soon as it’s available; speculative execution, which predicts the outcomes of conditional instructions to maintain a smooth instruction flow; and register renaming, which uses physical registers instead of logical ones to avoid WAR and WAW hazards by assigning unique register locations.
7. Conclusion
In this article, we’ve covered how structural and data hazards are inherent challenges in pipelined processor architectures. Each introduces unique performance penalties that can impact overall efficiency. Structural hazards result from resource limitations, while data hazards arise from dependencies between instructions.
Modern processors leverage advanced techniques such as out-of-order execution, data forwarding, and register renaming to handle these hazards. A deep understanding of these challenges enables us to enhance system performance.