1. Introduction
In this tutorial, we examine whether Artificial Intelligence (AI) can reason like humans. We explore the OpenAI 0-series, the new family of OpenAI Large Language Models (LLMs) capable of incorporating reasoning into their responses: o1 and o3-mini. OpenAI has been preparing these models for several years under Project Strawberry.
Several studies have shown the 0-series models can perform exceptionally well. For instance, the o1 model achieved an Elo score of 1891 while the o3-mini achieved 2130 with high reasoning effort in Codeforces, a competitive programming challenge. These results are substantially better than those of the earlier models like GPT-4o.
2. Why Is Reasoning Important?
The standard definition of reason is the capacity to consciously apply logic and draw valid conclusions from new and existing information.
Reasoning is how we solve problems in everyday decision-making, science, and philosophy. There are several types: deductive, inductive, analogical, abductive, critical, cause-and-effect, and decomposition reasoning.
2.1. How Humans Perform Reasoning: Example
How should we answer if asked whether the Sun will set in the evening today? Well, we can say that the Sun has set every day in the evening for the past recorded history, and hence, we can conclude that the Sun will set today as well.
Here, we use the knowledge about individual days from the past, infer the rule about the Sun setting every day in the evening, and generalize it to every day, including today. That’s induction. With reasoning, we make better decisions and adapt to new situations.
We can apply the same approach to solve more complex problems. Typically, humans approach a problem by breaking it down into simpler tasks and learning while reasoning about how to solve the simpler tasks and combine the solutions.
2.2. Can LLMs Perform Reasoning?
The theory behind Artificial General Intelligence (AGI) is that one day, AI will surpass human cognitive intelligence. The past few years have shown us that the LLMs are improving at generative tasks, which include multi-modal generation of text, images, audio, video data, etc.
However, a key step towards achieving Artificial General Intelligence (AGI) has always been to perform reasoning-based tasks. This hasn’t been the forte of previous LLMs so far. We had to supplement a model by adopting techniques such as Chain-of-Thought (CoT) prompting.
But imagine if an LLM could perform this kind of reasoning without our help. OpenAI’s o1 family of LLMs promises to achieve this. The longer the o1 models are allowed to run and “think,” the more accurate their answers are.
3. What Makes o1 Models Capable of Reasoning?
So, what fundamental changes in the previous approach could have led to this success? Although not much information is available about the architecture of the o1 models, OpenAI has revealed several working principles.
3.1. Chain-of-Thought
Chain-of-thought (CoT) is a prompting technique that enables complex reasoning capabilities through intermediate reasoning steps:
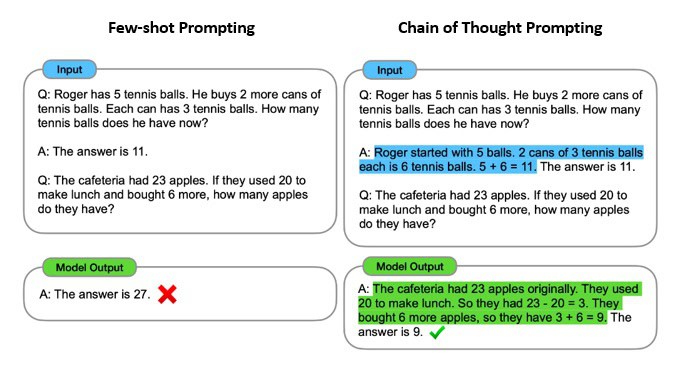
As we can see in the above example, compared to standard prompting techniques, the CoT prompting enables a model to generate a much better response. It enables complex reasoning capabilities by prompting a model to perform complex tasks step-by-step.
But, this still requires us to create sophisticated prompts that can lead to the expected behavior from a model. On the other hand, if the model can generate these CoT prompts on its own, it will be able to apply reasoning to solve complex problems.
The o1 models use techniques like reasoning tokens and have been trained using reinforcement learning to achieve this.
3.2. Reinforcement Learning
The o1 models have been trained using reinforcement learning to apply chain-of-thought reasoning while solving a problem. Reinforcement learning is a type of machine learning in which an autonomous agent learns to perform tasks by interacting with its environment: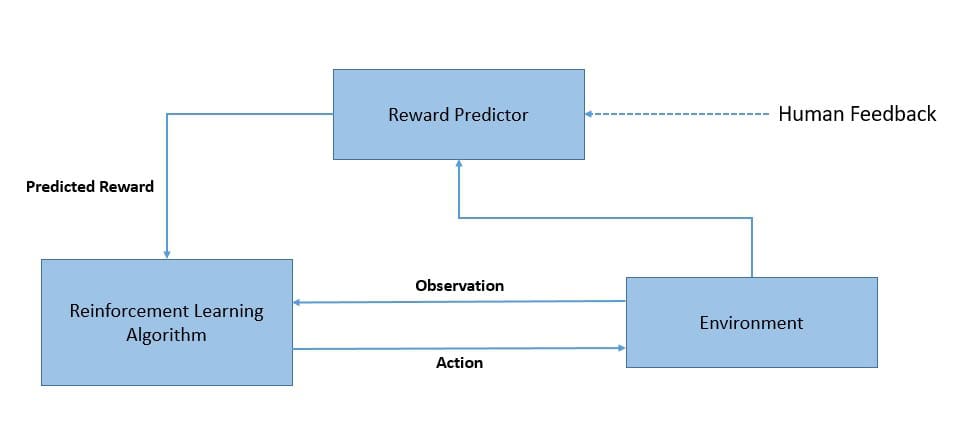
This works based on a trial-and-error approach. The actions that work towards a goal are reinforced, while the ones that detract from the goal are ignored. During the training of 01 models, they are rewarded for the correct answers while penalized for incorrect ones.
Reinforcements help the model to refine its reasoning capabilities and become more adept at handling complex tasks over time, as the model can make corrections by receiving feedback on its responses. Consequently, it learns to use various problem-solving approaches to maximize the reward and pick the most effective one.
O1 models have been trained to solve problems using a chain-of-thoughts process. When we ask them questions, they take time to respond, breaking down the problem and analyzing all possible approaches. This is a notable difference from previous versions of ChatGPT.
3.3. Reasoning Tokens
Another important aspect is the introduction of reasoning tokens and completion tokens as part of the “thinking” process. When the o1 models are asked a question, they generate reasoning tokens to break down the problem and consider multiple approaches to generate a response.
After this, the model produces a response as a completion token and discards the reasoning tokens. While the completion tokens are visible through the APIs, the reasoning tokens are invisible. However, they both form part of the output tokens and occupy space in the model’s context window:
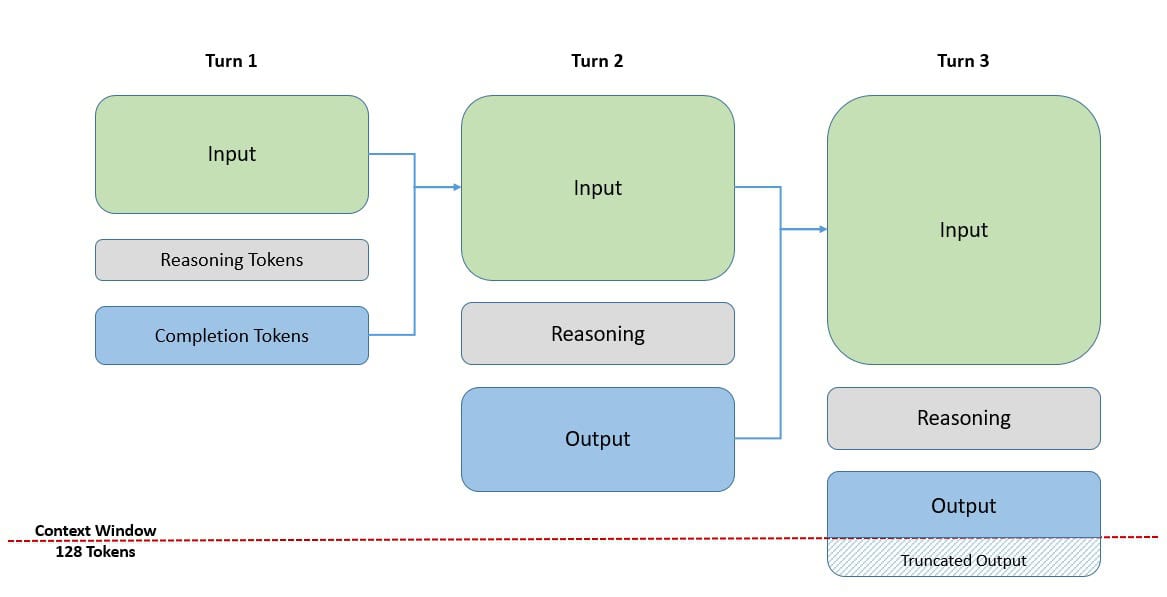
Depending on the complexity of the problem, the reasoning tokens can occupy small to large portions of the context space. If they grow in size significantly, this may also lead to truncation of the output die to a limited context window.
However, it’s possible to limit the total number of tokens the model generates. Such constraints can be an important tool for managing costs while gaining the benefits of reasoning. Also, since o1 models can think “step-by-step” inherently, prompts should be straightforward.
4. Advantages and Limitations
The reasoning-based models provide much better responses with minimal human intervention:
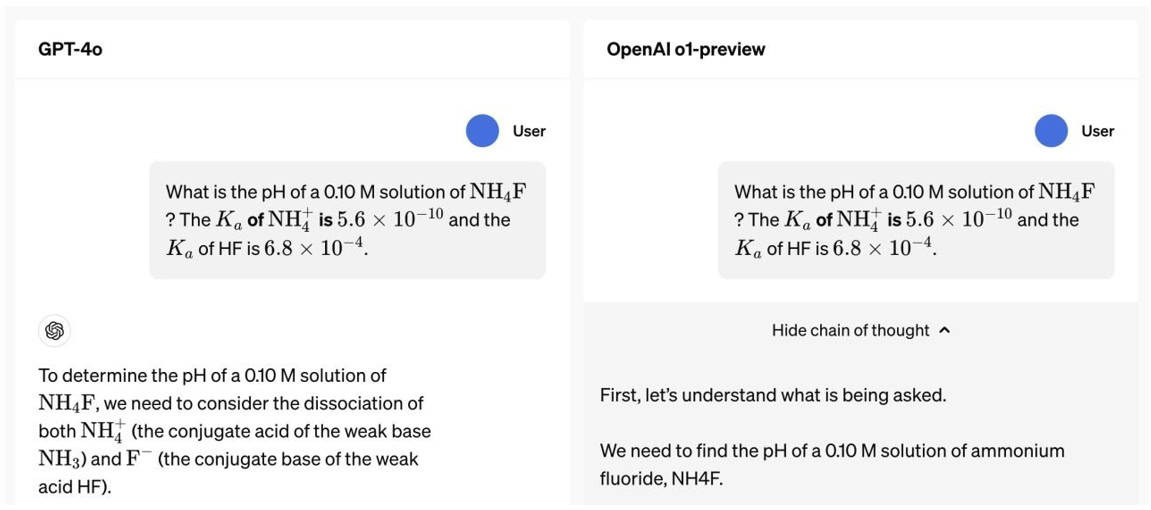
As we can see above, the o1-preview model applies the chain-of-thought reasoning to break down and analyze the problem before producing a final response.
However, while there are tremendous benefits of using reasoning-based models like 01 family of models, they are still evolving and have some limitations of use:
Advantages of o1 Models
Limitations of o1 Models
Better responses than previous models like 4o, without requiring sophisticated prompt engineering techniques.
Quite expensive to train and use. The hidden chain-of-thought process also makes the response time slower than previous models.
Due to their ability to solve complex problems, they have wide applications.
As of now, they can’t access information directly from the web.
Safer to use, with stricter adherence to safety guidelines.
Lack of features like function calling, structured output, and streaming capabilities.
With *o-*series models, OpenAI is also adopting deliberate alignment as their safety strategy. With deliberate alignment, a model uses its reasoning capabilities to evaluate prompts in real-time. This is in contrast to more static approaches taken in earlier models.
5. Evolution of the o-Series Models
OpenAI is committed to bridging any gaps in its current flagship reasoning models. Very soon they are coming up with the next set of models in this series, the o3 family of models. The o3 models build directly on the foundation set by the o1 models.
While the release date for the o3 model is not clear, the o3-mini is already available for use. The o3-mini, like the o1-mini, is a cost-effective alternative designed to bring advanced reasoning capabilities to a wider audience. The results with o3-mini are already very promising:
Criterion
o1
o3-mini
Reasoning effort
Can’t be adjusted
Adjustable based on the complexity of the task
Response time
Takes more time even for simpler problems that may not require high reasoning effort
We can select low-effort reasoning for simpler problems and gain speed and efficiency
Features
Lacks features such as function calling and structured output along with streaming capabilities
Progressively addresses the shortcomings of the o1 model by adding features like function calling and structured output
Error-rate
For complex real-world applications, the error rates are still significant
Aims to reduce critical errors significantly compared to the o1 models, improving precision and reliability
The o3-mini model has also outperformed the o1 models on many parameters of evaluation, like AIME 2024 for competitive math, GPQA Diamond for PhD-level science questions, and Codeforces Elo Scores for competitive programming, to name a few.
5. Future of Reasoning-based AI
It may be early, but it’s safe to say we’ve taken a new direction in the research and development of reasoning-based AI. This has also opened many new frontiers for the application of AI, which can reason through problems and improve over time.
Future improvements in the abilities of reasoning-based models can come in handling uncertainty, integrating knowledge from diverse sources, and adapting to new situations. New situations can arise as they may have to solve problems in which it has no prior training.
The focus will also be on making these models smaller and more efficient for a broader spectrum of tasks. This will increase their reach and value for a wider audience. More applications in fields like medical diagnosis, legal reasoning, and scientific research are almost imminent.
Needless to say, every provider of LLMs will have to prove that their models are safe to use. Mechanisms that can help explain a model’s output will be important to build trust. Moreover, we’ll continue to see stricter legal and industry standards emerge for conformance.
6. Conclusion
In this article, we discussed reasoning as a tool for complex problem-solving. We saw how the new o1 family of models has started to use a chain-of-thought approach inherently. This has helped them apply multi-step reasoning when responding to any question.
**The o-series models use reasoning tokens, chain-of-thought, and reinforcement learning to incorporate reasoning-like computation in their prompts. The idea here is that the models should try to match human reasoning processes via computation.