1. Introduction
Multi-headed models use a shared, often pre-trained, backbone network, which feeds into many predictor heads.
In this tutorial, we introduce the concept of multi-headed models and highlight their general structure before exploring their benefits and use cases.
2. What’s a Multi-Headed Model?
A multi-headed model has two key components that allow it to handle several tasks: a shared backbone and multiple heads.
The shared backbone is the main body of the network, often consisting of convolutional layers (in CNNs) or transformer layers (in transformers). It processes the input and learns useful representations (embeddings) for all the tasks.
After the shared layers, the network splits into separate branches (heads), each designed to produce outputs for a specific task. Each head may have a few unique layers that we optimize for that particular task. For instance: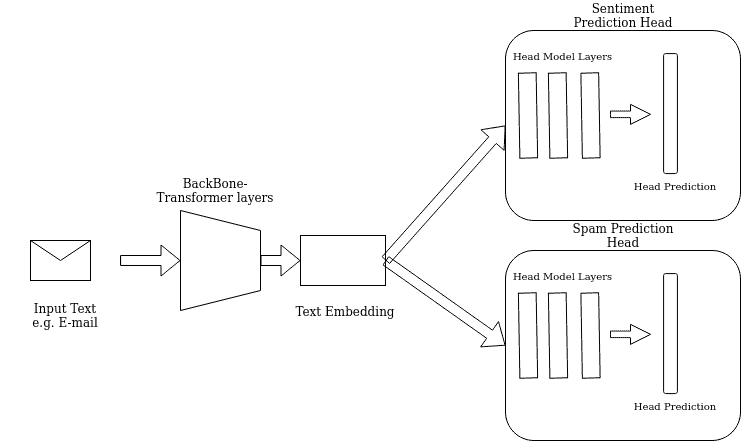
An example is a two-headed NLP model that performs sentiment analysis and spam classification. In this case, one head is responsible for analyzing sentiment (e.g., determining if a text is positive, negative, or neutral), while another head checks whether a message is spam.
Using multiple heads allows a single model to perform distinct tasks simultaneously. The backbone they share does feature extraction, while each head tailors the output for its specific task.
3. Training
During training, each head minimizes the loss function specific to its task. We combine all these losses into a weighted sum and minimize it during training.
In this way, multi-headed models leverage knowledge from multiple tasks. The backbone is trained to extract the features useful for all those tasks, while each head focuses on its specific task: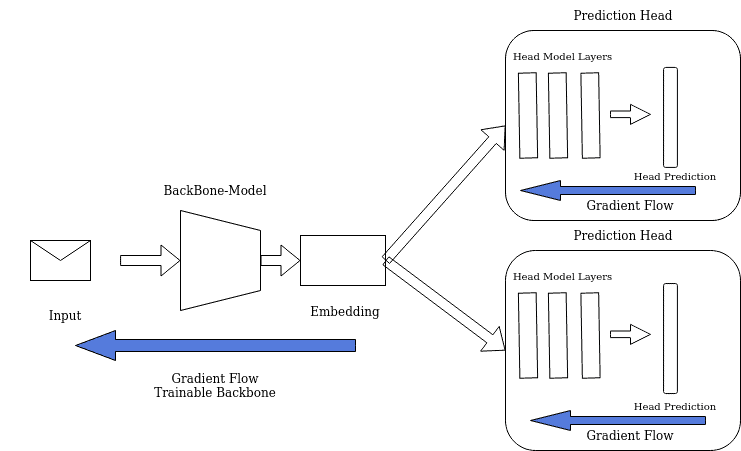
In our example, patterns related to tone, word frequency, and structure learned during sentiment analysis can also be beneficial for detecting spam. Similarly, some features learned during spam classification can be useful for sentiment analysis. The backbone combines them into the feature map (or embedding), which is then processed separately by each task-specific head.
However, we can keep the backbone network constant and train only the heads.
Models using a large pre-trained model, such as BERT, are a good example. The pre-trained backbone is considered general enough to be useful for a wide range of tasks, so we only need to train heads on top of it: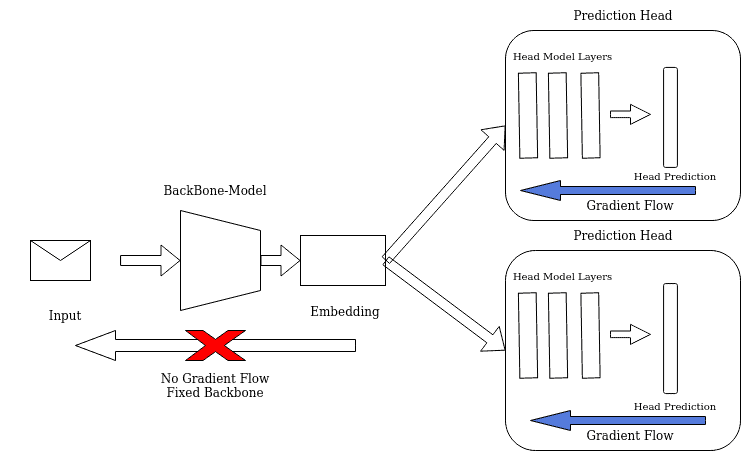
Since the backbone is constant, there’s no knowledge transfer between the heads. However, training is faster because we train smaller head models instead of the entire backbone and the heads. Additionally, training can be parallelized.
4. Benefits and Drawbacks
Multi-headed neural network models have benefits and drawbacks. They excel at generating more robust data representations by leveraging learning signals from multiple tasks, which makes them particularly effective when the primary task data is limited.
Such models also present difficulties during training. Challenges arise when aligning learned representation with certain tasks, especially when one task dominates others during training. This adds additional complexity, as loss function weights may need to be carefully tuned. Such a problem may also arise when using a fixed backbone that is misaligned with one or more of the task heads.
Here’s the summary:
Benefits
Drawbacks
Better and more robust data representations using multi-task signals.
Task alignment challenges arise if some tasks dominate others during training.
Helpful for tasks with limited data by leveraging additional learning tasks.
Adjusting task weightings increases model complexity due to extra hyperparameters.
Faster training when using fixed backbone networks, as only smaller heads are updated.
Fixed backbones may lead to misaligned representations for certain tasks.
5. Use Cases
5.1. Computer Vision
A localization model is an example where we want to both classify an object in an image and place a bounding box around it. A multi-headed model approach well handles such an objective.
Such a model would be useful in the context of self-driving cars. Here, the multiple heads may focus on the separate but related tasks of detecting lanes, localizing objects within lanes, and classifying the objects.
5.2. Natural Language Processing
Models like BERT often use different heads for tasks like sentiment analysis, question answering, named entity recognition, and other NLP tasks.
We keep the BERT backbone model fixed and train only the new task-specific heads. Each head is a distinct model sitting on top of the BERT backbone.
5.3. Reinforcement Learning
Multi-headed architectures allow agents to simultaneously learn a primary objective (e.g., maximize reward) while learning auxiliary objectives that indirectly improve the main task.
This is a form of multi-task learning, in which an agent solves multiple tasks simultaneously or sequentially. We can view this sequential training as a form of curriculum learning in circumstances where the final task is the primary target task.
This type of training augments the learning signal, which is important in reinforcement learning as it tends to have a sparse reward structure and, consequently, slow learning.
6. Conclusion
In this article, we covered multi-headed models in machine learning.
They are a key component of modern deep learning architectures. They consist of shared backbone layers and heads specializing in their specific tasks. We can train the heads and the backbone simultaneously to benefit from knowledge transfer between the tasks, or we can train only the heads on top of the pre-trained backbone.